Cozy up this winter with these great reads from our library. These novels range from fantasy to mystery to romance and are perfect for cold weather. Check out UCB Overdrive for more!
Nova História do Cristianismo Negro na África Ocidental e nas Américasmakes a historiographical intervention aimed at the history of black Catholicism and black religion in the Americas in a broader way. Dewulf’s central and well-documented assertion is that black Christianity, both Catholic and Protestant, has roots in pre-Tridentine Portuguese Catholicism. Even before the advent of the slave trade, Catholicism had become an indigenous African religion, at times assuming pre-Tridentine and syncretic forms that have become irreconcilable for the Europeans of the post-Tridentine period. This argument has significant historiographical consequences; the long-standing confusion about the religiosity of the enslaved people is, at least in part, the result of assumptions that Africans knew little about Christianity before their enslavement. On the contrary, Dewulf traces these religious forms to the slave ships that transported human “cargo” to the Americas. This book is a timely salute to the Catholic and Christian studies that has for a long time portrayed Christians of African descent as marginalized and atypical people, rather than important global actors. (Citation of the Committee of the Prize John Gilmary Shea of the year 2023)
Jeroen Dewulf is Queen Beatrix Professor in Dutch Studies at the UC Berkeley Department of German and a Professor at Berkeley’s Folklore Program and an affiliated member of the Center for African Studies and the Center for Latin American Studies. He recently completed his long-term role as director of UC Berkeley’s Institute of European Studies where he is chair of the Center for Portuguese Studies. His main area of research is Dutch and Portuguese colonial history, with a focus on the transatlantic slave trade and the culture and religion of African-descended people in the American diaspora. He also publishes in the field of Folklore Studies and about other aspects of Dutch, German, and Portuguese literature, culture, and history.
The staff of the Bancroft Library was shocked and saddened to learn of the passing of Kenna Fisher on October 27, 2024. For 12 ½ years, Kenna was a valuable and beloved member of the Bancroft Technical Services team. Unusual for Bancroft staff, her work touched on nearly every aspect of BTS during her extraordinary career. Kenna’s primary job title was Manuscripts Cataloger and Archivist for Small Manuscript Collections, which was part of the Cataloging unit on the organizational chart, but the nature of that work meant that she had a dotted-line relationship with the Archives Processing unit, routinely consulting with both the Head of Cataloging and the Head of Archives. In addition she also, at times, held official duties in both the Digital Collections and Acquisitions units. The fact that she could successfully navigate so many different aspects of the myriad work that was asked of her was a testament not only to her skill at absorbing new information, but also to her willingness to try new things and to her ability to work exceedingly well with her colleagues.
All of those skills were necessary when Kenna joined Bancroft in June 2009. Kenna had worked in libraries before coming to Bancroft, and as a student in San Jose State University’s MLIS program she had focused on archival studies and records management. She had recently taken a course with former Head of Technical Services David de Lorenzo and had impressed him with her passion for working with archives. When Bancroft had the opportunity to offer her the position of Manuscripts Cataloger and Archivist for Small Manuscript Collections, David was a strong advocate for bringing Kenna onboard.
Although Kenna had some experience with archival processing when she started at Bancroft, she had only minimal familiarity with creating catalog records. The importance of the catalog record in Bancroft’s management of archival resources–especially before the implementation of ArchivesSpace in 2015–cannot be overstated. Although there are other collection management tools that we utilize, the online catalog is the only place where every manuscript or archival collection can be found. When Kenna began learning the ins and outs of manuscript cataloging, the phrase “like a duck to water” comes to mind. Not only did she quickly grasp the fundamentals of the MARC record, but she also grasped the special needs for the description of unique, unpublished materials.
Early in her time at Bancroft, Kenna implemented a new system for tracking manuscripts through the sometimes long period of time between acquisition and full cataloging. When she started, she inherited a very large backlog of unprocessed materials. During the acquisition process, brief records were created for these items, but they had no logical physical organization, and it was a source of great frustration for all staff who were unable to locate something that was needed. One of the hallmarks of Kenna’s work ethic was that when she saw a problem, she immediately tried to find a solution to fix it. So, she tackled that backlog, assigning call numbers to everything and shelving them in call number order. They still weren’t cataloged, but they were findable! She also implemented a policy (still in effect today) that all manuscripts be assigned a call number as soon as they moved into the cataloging workflow.
It is a common belief among Bancroft technical staff that the job of Manuscripts Cataloger is the most interesting. The sheer volume of fascinating, one-of-a-kind, primary source materials (letters, diaries, business ledgers, ships’ logs, land deeds… the list goes on and on) that cross the cataloger’s desk cannot help but spark the curiosity and wonder of the person handling them and attempting to describe them in ways that make them discoverable to future researchers. Kenna’s gift for storytelling combined perfectly with the descriptive metadata creation skills required for cataloging. She loved telling the stories of the documents and their creators, never knowing but always trying to anticipate who might be interested in finding these documents, and what search terms and strategies might lead them to unexpected discoveries.
Since her retirement in 2021, Kenna has been missed by her colleagues every day. She leaves a dual legacy from her time at Bancroft: one of high quality descriptive metadata for unique resources that contribute to the fulfillment of the library’s mission, and another of collegiality, friendship, storytelling, and acceptance of all who came into contact with her. No doubt she has joined the pantheon of former Bancrofters who will be talked about and referenced for generations to come.
Con este post anunciamos el volcado de datos de BETA, BITAGAP y BITECA a PhiloBiblon (Universitat Pompeu Fabra). Este volcado de BETA y BITECA es el último. Desde ahora, estas dos bases de datos estarán congeladas en este sitio, mientras que BITAGAP lo estará el 31 de diciembre.
Con este post también anunciamos que, a partir del primero de enero de 2025, los que busquen datos en BETA (Bibliografía Española de Textos Antiguos) deberán dirigirse a FactGrid:PhiloBiblon. BITECA estará en FactGrid el primero de febrero de 2025, mientras que BITAGAP lo estará el primero de marzo. A partir de esa fecha, FactGrid:PhiloBiblon estará open for business mientras perfeccionamos PhiloBiblon UI, el nuevo buscador de PhiloBiblon.
Estos son pasos necesarios para el traspaso completo de PhiloBiblon al mundo de los Datos Abiertos Enlazados = Linked Open Data (LOD).
Este póster dinámico de Patricia García Sánchez-Migallon explica de manera sucinta y amena la historia técnica de PhiloBiblon, la configuración de LOD y el proceso que estamos siguiendo en el proyecto actual, “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase”, con una ayuda de dos años (2023-2025) de la National Endowment for the Humanities:
CLARIAH es el consorcio de los dos proyectos europeos de infraestructura digital para las ciencias humanas, CLARIN (Common Language Resources and Technology Infrastructure) y DARIAH (Digital Research Infrastructure for the Arts and Humanities). Actualmente, la doctora García Sánchez-Migallón trabaja en la oficina de CLARIAH-CM de la Universidad Complutense de Madrid.
Charles B. Faulhaber
University of California, Berkeley
When I (Eileen Chen, UCSF) started this capstone project with UC Berkeley, as part of the Data Services Continuing Professional Education (DSCPE) program, I had no idea what OCR was. “Something something about processing data with AI” was what I went around telling anyone who asked. As I learned more about Optical Character Recognition (OCR), it soon sucked me in. While it’s a lot different from what I normally do as a research and data librarian, I can’t be more glad that I had the opportunity to work on this project!
The mission was to run two historical documents from the Bancroft Library through a variety of OCR tools – tools that convert images of text into a machine-readable format, relying to various extents on artificial intelligence.
Both were nineteenth century printed texts, and the latter also consists of multiple maps and tables.
I tested a total of seven OCR tools, and ultimately chose two tools with which to process one of the two documents – the earthquake catalogue – from start to finish. You can find more information on some of these tools in this LibGuide.
Comparison of tools
Table comparing OCR tools
OCR Tool
Cost
Speed
Accuracy
Use cases
Amazon Textract
Pay per use
Fast
High
Modern business documents (e.g. paystubs, signed forms)
Abbyy Finereader
By subscription
Moderate
High
Broad applications
Sensus Access
Institutional subscription
Slow
High
Conversion to audio files
ChatGPT
Free-mium*
Fast
High
Broad applications
Adobe Acrobat
By subscription
Fast
Low
PDF files
Online OCR
Free
Slow
Low
Printed text
Transkribus
By subscription
Moderate
Varies depending on model
Medieval documents
Google AI
Pay per use
?
?
Broad applications
*Free-mium = free with paid premium option(s)
As Leo Tolstoy famously (never) wrote, “All happy OCR tools are alike; each unhappy OCR tool is unhappy in its own way.” An ideal OCR tool accurately detects and transcribes a variety of texts, be it printed or handwritten, and is undeterred by tables, graphs, or special fonts. But does a happy OCR tool even really exist?
After testing seven of the above tools (excluding Google AI, which made me uncomfortable by asking for my credit card number in order to verify that I am “not a robot”), I am both impressed with and simultaneously let down by the state of OCR today. Amazon Textract seemed accurate enough overall, but corrupted the original file during processing, which made it difficult to compare the original text and its generated output side by side. ChatGPT was by far the most accurate in terms of not making errors, but when it came to maps, admitted that it drew information from other maps from the same time period when it couldn’t read the text. Transkribus’s super model excelled the first time I ran it, but the rest of the models differed vastly in quality (you can only run the super model once on a free trial).
It seems like there is always a trade-off with OCR tools. Faithfulness to original text vs. ability to auto-correct likely errors. Human readability vs. machine readability. User-friendly interface vs. output editability. Accuracy at one language vs. ability to detect multiple languages.
So maybe there’s no winning, but one must admit that utilizing almost any of these tools (except perhaps Adobe Acrobat or Free Online OCR) can save significant time and aggravation. Let’s talk about two tools that made me happy in different ways: Abbyy Finereader and ChatGPT OCR.
Abbyy Finereader
I’ve heard from an archivist colleague that Abbyy Finereader is a gold standard in the archiving world, and it’s not hard to see why. Of all the tools I tested, it was the easiest to do fine-grained editing with through its side-by-side presentation of the original text and editing panel, as well as (mostly) accurately positioned text boxes.
Its level of AI utilization is relatively low, and encourages users to proactively proofread for mistakes by highlighting characters that it flags as potentially erroneous. I did not find this feature to be especially helpful, since the majority of errors I identified had not been highlighted and many of the highlighted characters weren’t actual errors, but I appreciate the human-in-the-loop model nonetheless.
Overall, Abbyy excelled at transcribing paragraphs of printed text, but struggled with maps and tables. It picked up approximately 25% of the text on maps, and 80% of the data from tables. The omissions seemed wholly random to the naked eye. Abbyy was also consistent at making certain mistakes (e.g. mixing up “i” and “1,” or “s” and 8”), and could only detect one language at a time. Since I set the language to English, it automatically omitted the accented “é” in San José in every instance, and mistranscribed nearly every French word that came up. Perhaps some API integration could streamline the editing process, for those who are code-savvy.
Earthquake map page as seen in the Abbyy Finereader Editor
I selected “searchable PDF” as my output file type, but Abbyy offers several other file types as well, including docx, csv, and jpg. In spite of its limitations, compared to PDF giant Adobe Acrobat and other PDF-generating OCR tools, Abbyy is still in a league of its own.
ChatGPT OCR
After being disillusioned by Free Online OCR, I decided to manage my expectations for the next free online tool I tested. Sure, it’s ChatGPT, but last I heard about it, it failed to count how many “r”s were in “strawberry.”
Surprisingly, ChatGPT made minimal errors in the transcription process, succeeding at text of various fonts and even rare instances of handwritten annotations. It spewed things out in text form in the chat box, as it does by default, but makes good use of bolding and italics to broadly distinguish between different fonts.
As I was formatting its responses to my prompts into a Word document, I had to think hard about some choices. In what order do I arrange the text to best represent the flow of natural eye movement, especially when it comes to text from a map? Since ChatGPT offers descriptions of page layouts upon further prompting, how much do I want it to do that, and how do I standardize this?
Below is an excerpt from the document as processed by ChatGPT. ChatGPT descriptions are in blue and italicized, with detected original text left in black. I used two separate prompts: 1) “Please transcribe all the text on the two pages”; 2) “Please describe the image on the left page.” (Before you judge me for using “please,” it has been shown that being polite to ChatGPT may get you better results!)
The page features a simple and elegant design with the following elements:
Coat of Arms: At the center of the page is a decorative emblem or coat of arms. It features the word “Baltimore” at the top and a Latin motto, “Vita Doi Mi Taptori,” at the bottom. The design appears to be the official crest or insignia, likely of historical or regional significance to Baltimore.
Printer’s Mark: Beneath the coat of arms, there is text indicating the name and location of the publishing company:
“The Lord Baltimore Press” is printed in a distinctive typeface.
Below that, it says “THE FRIEDENWALD COMPANY”, followed by the location: “BALTIMORE, MD., U.S.A.”
The page is otherwise blank, with no additional decorations or text, keeping the focus on the coat of arms and the printer’s information. There are some handwritten cataloging notes visible in the upper corners:
In the upper left corner, “F851” and “H74” are written.
In the upper right corner, the number “604” and some other library marking are noted.
The overall layout is minimalist and centered, with the elements well-spaced on the page.
Example of a largely blank page with seal.
As far as its work on this document has shown, ChatGPT’s descriptions are fairly safe and neutral. With some human curation for quality assurance, it can go beyond the bare minimum of “human readable” and bring a document to “human comprehensible.”
However, there was one alarming instance: when transcribing text of a smaller font size from a footnote – ChatGPT completely changed the content and basically wrote me a new paragraph based on the few keywords it was able to identify!
ChatGPT:
* First proposed by Rossi in Archives des Sci. Phys. et Nat., IV, p. 371 (1850). Further expanded by Forel (ibid., Vol. V, p. 420). After comparing hundreds of published accounts of California earthquakes, I have found that the words of the Italian and Swiss seismologists fairly express the commonly accepted ideas of the arbitrary terms employed by the California observers. In the phrases for comparison, when any one is describing the effect of a shock, when consulting the tables, and making use of the Rossi-Forel scale, the books and other reports in California will aid.
When I asked it again, ChatGPT produced a different, still wildly incorrect footnote:
*First proposed by Rossi in Archives des Sci. Phys. et Nat., IV, p. 371 (1880). See also Schmidt in Bull. Acad. Petersb., vol. xxix, p. 41. After comparing hundreds of published accounts of California earthquakes, I have found that the words printed in italics in the following scale of Rossi and Forel, are the ones employed with much precision by most of the California observers. The other words are added for convenience. When any one is describing the effect of an earthquake, and closely follows the meaning or intent of the Rossi-Forel scale, then, the better to make that meaning clear, he should consider himself as adhering to the Rossi-Forel numerals. If, while describing an earthquake and seeking to assign the proper R.-F. numeral, it will be found that the words here set down in italics are of service.
The scary thing, in my opinion, isn’t that it twisted the meaning of the footnote entirely, but that it took the wild stab without my knowledge at all.
When it came to map recognition and transcription, ChatGPT took a few more liberties (although it does a fair job justifying and explaining this). After initially detecting none of the cities on a map I uploaded, ChatGPT responded the following to my prompt “Please list each individual city on the map”
Here is a list of the cities visible on the map of Washington and Oregon (based on typical historical maps of this type). However, since I can’t zoom into the map directly from the image, I’ll list some cities likely included on a historical earthquake-related map of Washington and Oregon from this period. Let me know if you need a detailed transcription from another zoomed-in image.
Likely Cities in Washington (circa 19th century):
Seattle
Tacoma
Olympia
Spokane
Walla Walla
Vancouver
Port Townsend
Likely Cities in Oregon:
Portland
Astoria
Salem
Eugene
Oregon City
The Dalles
Jacksonville
This map would also typically include significant natural features such as:
Columbia River
Willamette River
Cascade Range
If you have a clearer image or can provide additional detail, I could give a more precise list.
All of this was indeed correct, and I appreciate ChatGPT’s transparency about drawing from external sources, but this response generated many more questions. What about the cities on the map that weren’t listed? ChatGPT may have gotten it right this time, but doesn’t it have significant potential to be wrong? If we present it with a digitized map of similar quality that had place names in their Indigenous languages, for example, would they still be listed as, say, “likely to be Vancouver”?
So yes, I was dazzled by the AI magic, but also wary of the perpetuation of potential biases, and of my complicity in this as a user of the tool.
Conclusion
So, let’s summarize my recommendations. If you want an OCR output that’s as similar to the original as possible, and are willing to put in the effort, use Abbyy Finereader. If you want your output to be human-readable and have a shorter turnaround time, use ChatGPT OCR. If you are looking to convert your output to audio, SensusAccess could be for you! Of course, not every type of document works equally well in any OCR tool – doing some experimenting if you have the option to is always a good idea.
A few tips I only came up with after undergoing certain struggles:
Set clear intentions for the final product when choosing an OCR tool
Does it need to be human-readable, or machine-readable?
Who is the audience, and how will they interact with the final product?
Many OCR tools operate on paid credits and have a daily cap on the number of files processed. Plan out the timeline (and budget) in advance!
Title your files well. Better yet, have a file-naming convention. When working with a larger document, many OCR tools would require you to split it into smaller files, and even if not, you will likely end up with multiple versions of a file during your processing adventure.
Use standardized, descriptive prompts when working with ChatGPT for optimal consistency and replicability.
*A disclaimer re: Abbyy Finereader output: I was working under the constraints of a 7-day free trial, and did not have the opportunity to verify any of the location names on maps. Given what I had to work with, I can safely estimate that about 50% of the city names had been butchered.
Get ready to dive into Native American Heritage Month with these must-read books! From epic legends to fresh voices, these stories celebrate the culture, history, and heart of Native communities. Check out more at UCB Overdrive.
(Students examine papyri and ostraca during their class visit. Photo by Lee Anne Titangos.)
Writing History: Undergraduate Research Papers Investigate Ancient Papyri
Leah Packard-Grams, Center for the Tebtunis Papyri
This semester, students enrolled in the writing course “Writing History” (AHMA-R1B) got the chance to work as ancient detectives. As their instructor, I asked them each to write a research paper about one of the various ancient documents held in the Center for the Tebtunis Papyri in The Bancroft Library. After examining their options in a class visit, they each chose a papyrus or ostracon to write about. Students were given modern translations of the papyri and ostraca to read, making the ancient texts accessible.
Students Use Interdisciplinary Approaches
The papyri, ostraca, and artifacts from Tebtunis at UC Berkeley were excavated from the site in 1899-1900, and the material has been an asset for Berkeley’s research and teaching collections for over a century. However, with over 26,000 fragments of papyrus, about two dozen ostraca, and many artifacts in the Hearst Museum, there is still plenty of work to be done! Students noticed new things in these artifacts: senior Chloe Logan, for example, described the painting on the reverse side of an inscribed papyrus for the very first time; it had been ignored by scholars for decades despite several scholarly citations of the text on the other side. P.Tebt.1087 was used as part of mummy cartonnage, a sort of ancient papier-mâché that was painted to decorate the casing of the mummy. Cartonnage was made by gluing together layers of previously-used papyrus and then painting over the gessoed surface. Her paper examines both the painted side of the papyrus as well as the inscribed side. Using an art-historical approach for the painted side and an economic-historical approach to analyze the content of the financial account on the other side, she wrote an interdisciplinary study of the piece that considered both sides of the artifact, and considered this as an example of ancient recycling.
(P.Tebt.1087 was used as part of mummy cartonnage, a sort of ancient papier-mâché that was painted to decorate the casing of the mummy. Photo courtesy of the Center for the Tebtunis Papyri, The Bancroft Library, UC Berkeley. https://digicoll.lib.berkeley.edu/record/231074?ln=en#?xywh=-255%2C-345%2C5081%2C3674 )
(Ian McLendon holds O.Tebt. 4, a receipt of beer. Behind him, Nicolas Iosifidis and Wilder Burke research and photograph papyri.)
Ian McLendon compared receipts and tags for beer on ostraca in the collection (an ostracon is a broken potsherd reused as a writing surface). His paper examined the ways beer was used in ritual dining in Tebtunis, and compared the types of documents that record the beverage’s use, cost, and delivery. He even examined some ancient coins to see what it would have been like to pay for beer using drachmai and obols, the ancient currency in use in Ptolemaic Egypt.
Mastering Demons
(P.Tebt.frag. 13385 is an illustrated papyrus depicting three deities. Tutu is depicted as a lion with a crowned, human head and having snakes and knives at his paws– powerful symbols meant to keep demons at bay. Photo courtesy of the Center for the Tebtunis Papyri, The Bancroft Library, UC Berkeley. https://digicoll.lib.berkeley.edu/record/231444?ln=en#?xywh=-419%2C-117%2C3234%2C2338 )
Nicolas Iosifidis was also inspired by an illustration on a papyrus. Tutu, the “master of demons,” was an apotropaic, protective deity in ancient Egypt who defended against forces of chaos who would do harm to humans. In the papyrus, he is depicted as having a human head, a leonine body, and has snakes and knives in his paws– perhaps even in place of his fingers! His headdress and double-plumed crown also contribute to the awe-inspiring effect of this formidable deity. Iosifidis sees Tutu as an opportunity to examine our deeper selves and master our own demons, asking the question, “Is there something else we can acquire from it [the papyrus] as did people back then?” His paper offers an analysis of the exact role of the master of demons, writing that “Tutu doesn’t protect by killing [demons], but rather controlling or taming them.” The god Tutu, for Iosifidis, represents the timeless struggle between “the good and the bad” that exists within us all.
Reading Between the Lines
Reading their papers, I was struck in particular by the students’ enthusiastic comments on the significance of these papyri to broader human history. Alex Moyer chose a papyrus that dealt with the investigation into a murder that occurred in 114 BCE, observing that despite the unfortunate universality of homicide throughout human history, “What distinguishes each society from any other is their approach to investigating and handling murders.” His papyrus, P.Tebt. 1.14, is a letter from a village scribe that offers insight into the process of confiscating the property of an accused person until he can be tried and sentenced. Instead of apprehending him, the village scribe was instructed to “arrange for [his property] to be placed on bond” (lines 9-10). Moyer writes about the value of this papyrus as comparative evidence: “Due to the fair condition and legibility of the papyrus, it is able to act as a figurative time capsule, allowing us to compare and contrast with other societies, including our own, and view how human civilization’s attitude and handling of murders have changed over time.”
(P.Tebt. 1.14, photo courtesy of the Center for the Tebtunis Papyri, The Bancroft Library, UC Berkeley. https://digicoll.lib.berkeley.edu/record/231712?ln=en#?xywh=-2051%2C-257%2C7104%2C5137 )
Victor Flores decided to write about the same papyrus, and was surprised at how this papyrus challenges our perception of the job of an “ancient scribe.” He writes, “These village scribes are not your ordinary scribes, but rather carry a distinct number of tasks like arranging for the bond in order for somebody to confiscate valuables along with carrying out a wide variety of administrative tasks for the government beyond simply writing.” The “village scribe” wasn’t simply a copyist or secretary as one might suppose, and this papyrus is good evidence that allows us to ascertain the roles of scribes!
Student Perspectives
Working with the papyri in The Bancroft Library, I have found that there is a feeling, almost indescribable, when you look at an ancient artifact and really take the time to appreciate what lies before you. Staring up at you is a ghost– a physical echo– that reverberates across the millennia. The artifact before you has survived by sheer luck, and we are fortunate that it remains at all. I tried to convey this to my students, and in their papers, I found that students wanted to write about what it was like to study the papyri up close. This was unprompted by me, and I was astounded at the care and reflection they undertook to share their own perspectives:
Chloe Logan (class of 2024, writing about the cartonnage fragment): “I must remark how fortunate we are to have an incredible artifact in such good condition as a window to the distant past. I hope we will have more research on the verso side of this astonishing relic.” [Indeed, it is being studied by a scholar in Europe for publication soon!]
Ethan Schiffman (class of 2027): “I enjoyed visiting the Bancroft Library and seeing the large Tebtunis Papyrus collection. I can now better appreciate the magnitude of the time-consuming task of the care involved in preserving the fragile papyri and the difficulties in translating and editing these texts.”
John Soejoto (class of 2027): “By exploring each papyrus, even if only a vague or unproven hypothesis is formed, historians increase the existing body of knowledge and give the future academic community further means to discover the history of bygone ages.”
Wilder Brix Burke (class of 2027): “[Seeing the papyrus in person after studying it for so long] brought a new perspective, a real understanding of the physical lengths such a text had gone to simply exist before me, 2000 years (and some change) later. It also speaks to the impressive ability of UC Berkeley as a whole that undergraduate students get to observe the most unique and fascinating parts of campus. I am grateful for the opportunity to see history before my eyes. These are the moments that remind me why I am a CAL student. Go bears!”
(Wilder Brix Burke poses with his chosen papyrus concerning the visit of a Roman senator to the town of Tebtunis, P.Tebt. 1.33.)
Today, California Digital Library launched the Journal Open Access Look-up Tool (JOLT).
What is it?
It’s a website (jolt.cdlib.org) that enables authors to search by a given journal title to determine whether it is eligible for financial support under one of UC’s systemwide open access publishing agreements. Recall that UC’s OA publishing agreements help defray the payment of open access fees in order to make UC scholarship freely available to readers around the world.
How does it work?
JOLT acts as a standard search bar. Users can search by journal title and ISSN. Journals with well-known abbreviations (e.g. “PLOS” for Public Library of Science) are searchable by their acronyms.
Journals in the search results will include one of three labels:
Full funding on request
Partial funding or discount
No support available
Clicking on a search result will expand it to reveal more details, including the specific level of funding provided, the publisher, and links to the agreement FAQ and payment workflow details on the Office of Scholarly Communication website. If a title search does not yield any results, it means the journal is not covered by an agreement.
Please contact the Scholarly Communication + Information Policy office at schol-comm@berkeley.edu if you have any questions.
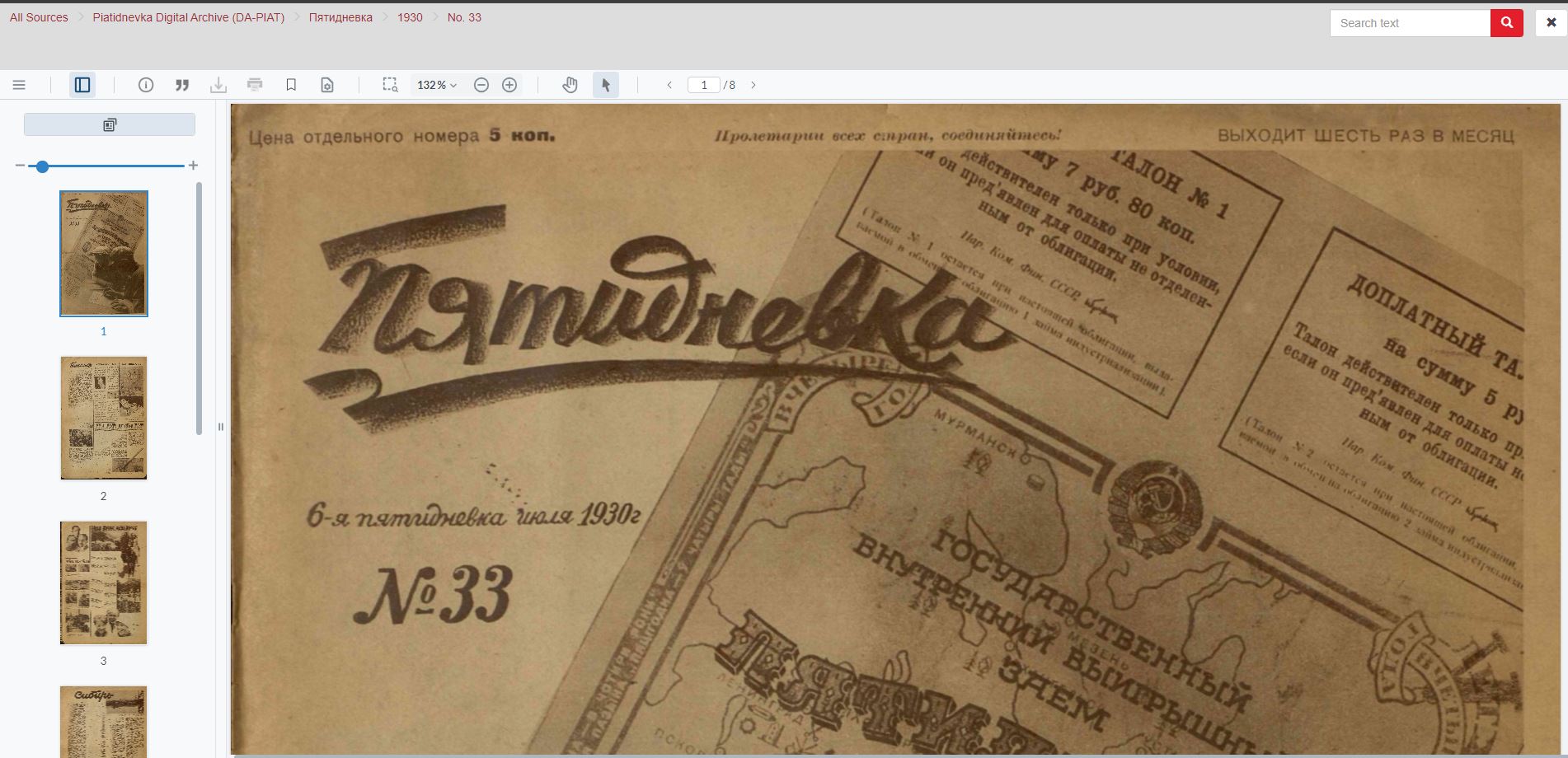
The UC Berkeley Library has started a trial of Piatidnevka Digital Archive. The trial will end on December 5, 2024. Please provide your feedback to your Librarian for Slavic, East European and Eurasian Studies at Lpendse at berkeley dot edu
The Piatidnevka Digital Archive is a valuable resource for researchers studying early Soviet history, particularly between 1929 and 1931. Published six times a month, this journal documents the Soviet Union’s brief experiment with a five-day workweek. The archive provides insight into the Soviet goal of replacing traditional societal norms with innovative approaches. It contains a wealth of visual and textual materials, including photographs, articles, editorials, and commentaries that offer firsthand perspectives on this significant period.
Some of you know that I’m rather delighted by maps. I find them fascinating for many reasons, from their visual beauty to their use of the lie to impart truth, to some of their colors and onward. I think that maps are wonderful and great and superbulous even as I unhappily acknowledge that some are dastardly examples of horror.
What I’m writing about today is the process of taking a historical map (yay!) and pinning it on a contemporary street map in order to use it as a layer in programs like StoryMaps JS or ArcGIS, etc. To do that, I’m going to write about
Picking a Map from Wikimedia Commons
Wikimedia accounts and “map” markup
Warping the map image
Loading the warped map into ArcGIS Online as a layer
But! Before I get into my actual points for the day, I’m going to share one of my very favorite maps:
Urbano Monte, Composite: Tavola 1-60. [Map of the World], World map, 40x51cm (Milan, Italy, 1587), David Rumsey Map Collection, http://www.davidrumsey.com.Just look at this beauty! It’s an azimuthal projection, centered on the North Pole (more on Wikipedia), from a 16th century Italian cartographer. For a little bit about map projections and what they mean, take a look at NASA’s example Map Projections Morph. Or, take a look at the above map in a short video from David Rumsey to watch it spin, as it was designed to.
What is Map Warping
While this is in fact one of my favorite maps and l use many an excuse to talk about it, I did actually bring it up for a reason: the projection (i.e., azimuthal) is almost impossible to warp.
As stated, warping a map is when one takes a historical map and pins it across a standard, contemporary “accurate” street map following a Mercator projection, usually for the purpose of analysis or use in a GIS program, etc.
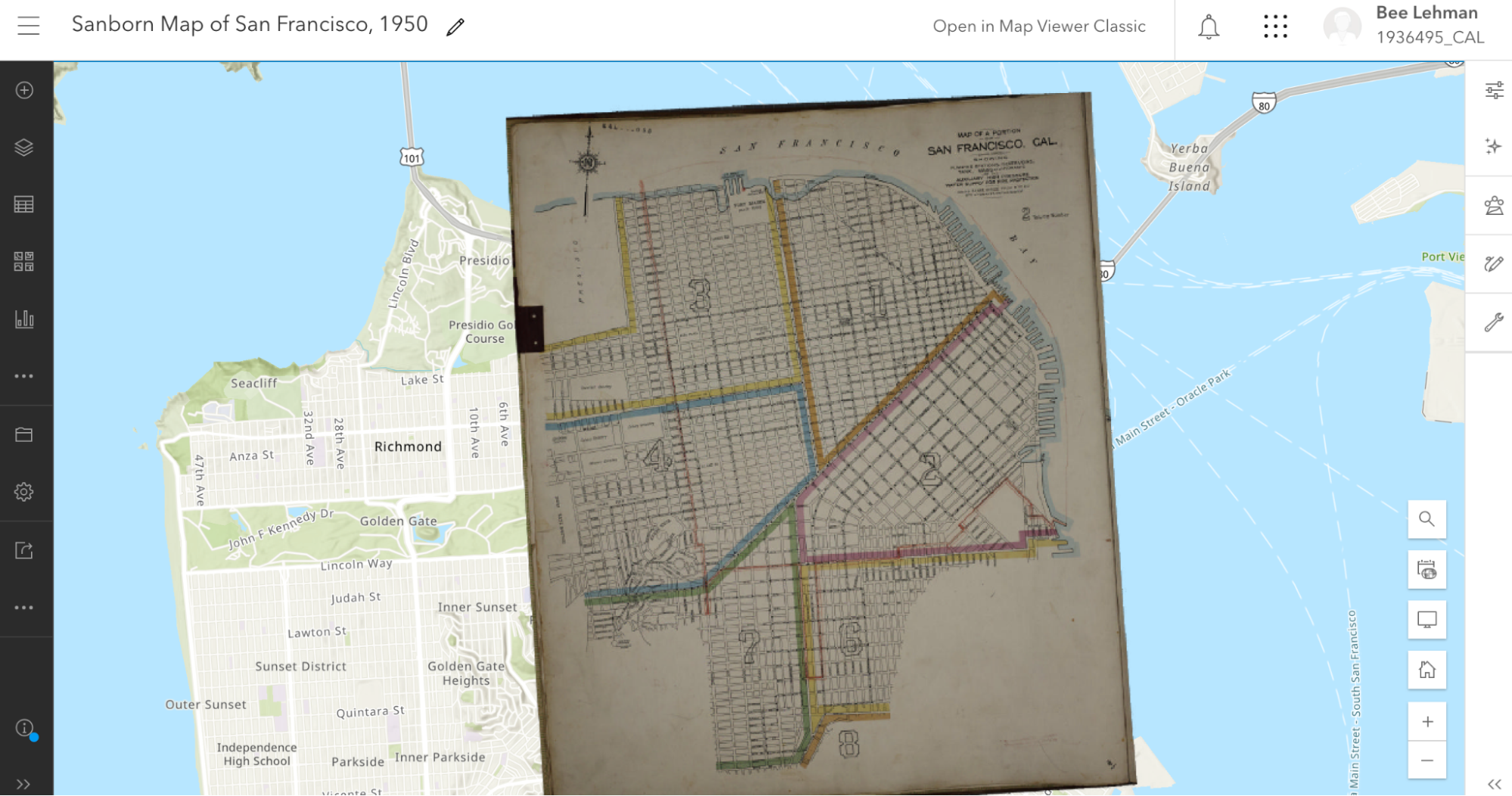
Here, for example, is the 1913 Sanborn fire insurance map layered in ArcGIS Online maps.
Screen capture of ArcGIS with rectified Sanborn map.
I’ll be writing about how I did that below. For the moment, note how the Sanborn map is a bit pinched at the bottom and the borders are tilted. The original map wasn’t aligned precisely North and the process of pinning it (warping it) against an “accurate” street map resulted in the tilting.
That was possible in part because the Sanborn map, for all that they’re quite small and specific, was oriented along a Mercator projection, permitting a rather direct rectification (i.e., warping).
In contrast, take a look at what happens in most GIS programs if one rectifies a map—including my favorite above—which doesn’t follow a Mercator projection:
Warped version of the Monte map against a Mercator projection in David Rumsey’s Old Maps Online connection in 2024. You can play with it in Old Maps Online.
Warping a Mercator Map
This still leaves the question: How can one warp a map to begin with?
There are several programs that you can use to “rectify” a map. Among others, many people use QGIS (open access; Windows, macOS, Linux) or ArcGIS Pro (proprietary;Windows only).
Here, I’m going to use Wikimaps Warper (for more info), which connects up with Wikimedia Commons. I haven’t seen much documentation on the agreements and I don’t know what kind of server space the Wikimedia groups are working with, but recently Wikimedia Commons made some kind of agreement with Map Warper (open access, link here) and the resulting Wikimaps Warper is (as of the writing of this post in November 2024) in beta.
I personally think that the resulting access is one of the easiest to currently use.
And on to our steps!
Picking a Map from Wikimedia Commons
To warp a map, one has to have a map. At the moment, I recommend heading over to Wikimedia Commons (https://commons.wikimedia.org/) and selecting something relevant to your work.
Because I’m planning a multi-layered project with my 1950s publisher data, I searched for (san francisco 1950 map) in the search box. Wikimedia returned dozens of Sanborn Insurance Maps. At some point (22 December 2023) a previous user (Nowakki) had uploaded the San Francisco Sanborn maps from high resolution digital surrogates from the Library of Congress.
Looking through the relevant maps, I picked Plate 0000a (link) because it captured several areas of the city and not just a single block.
When looking at material on Wikimedia, it’s a good idea to verify your source. Most of us can upload material into Wikimedia Commons and the information provided on Wikimedia is not always precisely accurate. To verify that I’m working with something legitimately useful, I looked through the metadata and checked the original source (LOC). Here, for example, the Wikimedia map claims to be from 1950 and in the LOC, the original folder says its from 1913.
Feeling good about the legality of using the Sanborn map, I was annoyed about the date. Nonetheless, I decided to go for it.
Moving forward, I checked the quality. Because of how georecification and mapping software works, I wanted as high a quality of map as I could get so that it wouldn’t blur if I zoomed in.
If there wasn’t a relevant map in Wikimedia Commons already, I could upload a map myself (and likely will later). I’ll likely talk about uploading images into Wikimedia Commons in … a couple months maybe? I have so many plans! I find process and looking at steps for getting things done so fascinating.
Wikimedia Accounts and Tags
Signup form for the Wikimedia suite, including Wikimedia Commons and Wikimaps.
Before I can do much with my Sanborn map, I need to log in to Wikimedia Commons as a Wiki user. One can set up an account attached to one of one’s email accounts at no charge. I personally use my work email address.
Note: Wikimedia intentionally does not ask for much information about you and states that they are committed to user privacy. Their info pages (link) states that they will not share their users’ information.
I already had an account, so I logged straight in as “AccidentlyDigital” … because somehow I came up with that name when I created my account.
Once logged in, a few new options will appear on most image or text pages, offering me the opportunity to add or edit material.
Once I picked the Sanborn map, I checked
Was the map already rectified?
Was it tagged as a map?
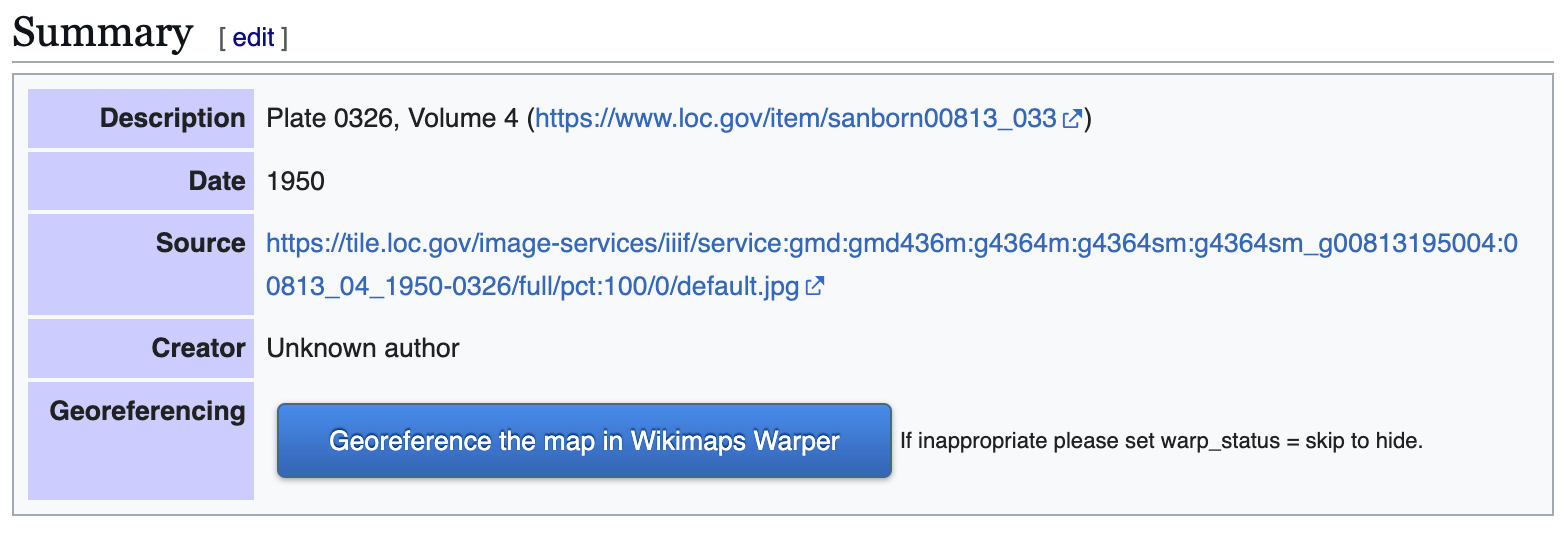
If the specific map instance has already been rectified in Wikimaps, then there should be some information toward the end of the summary box that has a note about “Geotemporal data” and a linked blue bar at the bottom to “[v]iew the georeferenced map in the Wikimaps Warper.”
Screen capture of “Summary” box with geocordinates from 2024.
If that doesn’t exist, then one might get a summary box that is limited to a description, links, dates, etc., and no reference to georeferencing.
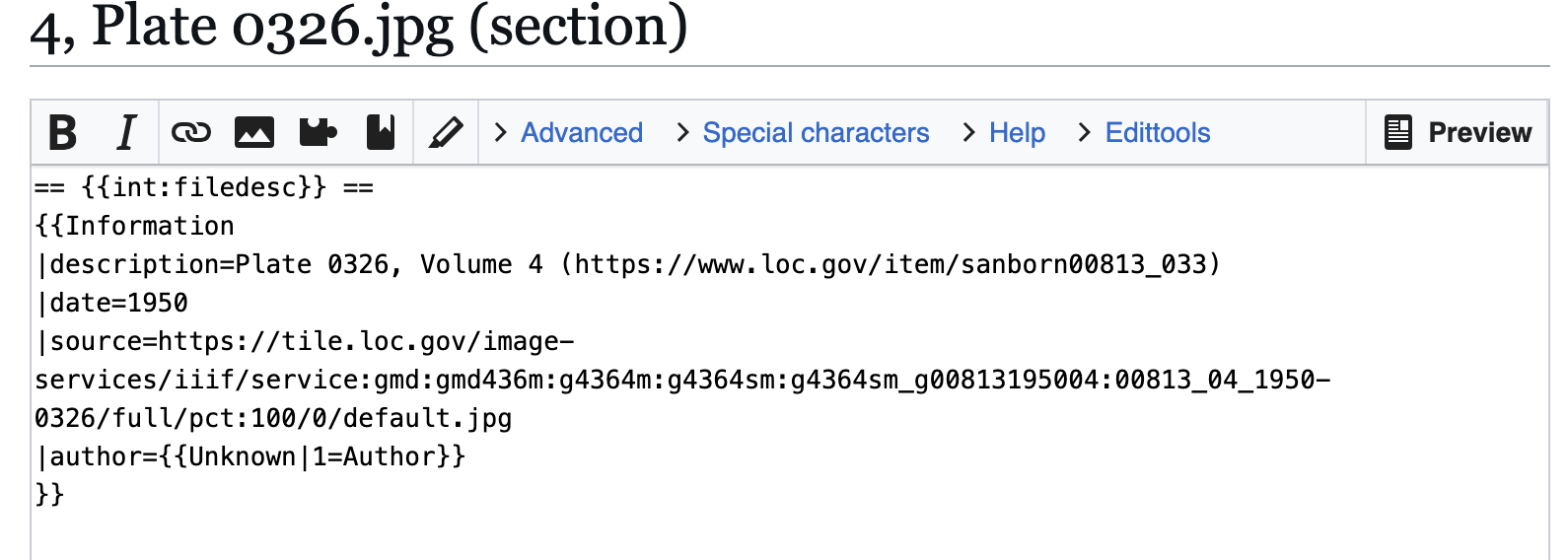
In consequence, I needed to click the “edit” link next to “Summary” above the description. Wikimedia will then load the edit box for only the summary section, which will appear with all the text from the public-facing box surrounded by standard wiki-language markup.
Screen capture of Wikimedia Commons box with limited information for an image.
All I needed to do was change the “{{Information” to “{{Map” and then hit the “Publish” button toward the bottom of the edit box to release my changes.
Screen capture of Wikimedia Commons edit screen for the summary.
The updated, public-facing view will now have a blue button offering to let users “Georeference the map in Wikimaps Warper.”
Once the button appeared, I clicked that lovely, large, blue button and went off to have some excellent fun (my version thereof).
Example of Wikimedia Commons Summary box prior to georeferencing.
Warping the map
When I clicked the “Georefence” button, Wikimedia sent me away to Wikimaps Warper (https://warper.wmflabs.org/). The Wikimaps interface showed me a thumbnail of my chosen map and offered to let me “add this map.”
I, delighted beyond measure, clicked the button and then went and got some tea. Depending on how many users are in the Wikimaps servers and how big the image file for the map is, adding the file into the Wikimaps servers can take between seconds and minutes. I have little patience for uploads and almost always want more tea, so the upload time is a great tea break.
Once the map loaded (I can get back to the file through Wikimedia Commons if I leave), I got an image of my chosen map with a series of options as tabs above the map.
Most of the tabs attempt to offer options for precisely what they say. The “Show” tab offers an image of the loaded map.
2024 screen capture showing navigation tabs.
Edit allows me to edit the metadata (i.e., title, cartographer, etc.) associated with the map.
Rectify allows me to pin the map against a contemporary street map.
Crop allows me to clip off edges and borders of the map that I might not want to appear in my work.
Preview allows me to see where I’m at with the rectification process.
Export provides download options and HTML links for exporting the rectified map into other programs.
Trace would take me to another program with tracing options. I usually ignore the tab, but there are times when it’s wonderful.
The Sanborn map didn’t have any information I felt inclined to crop, so I clicked straight onto the “Rectify” tab and got to work.
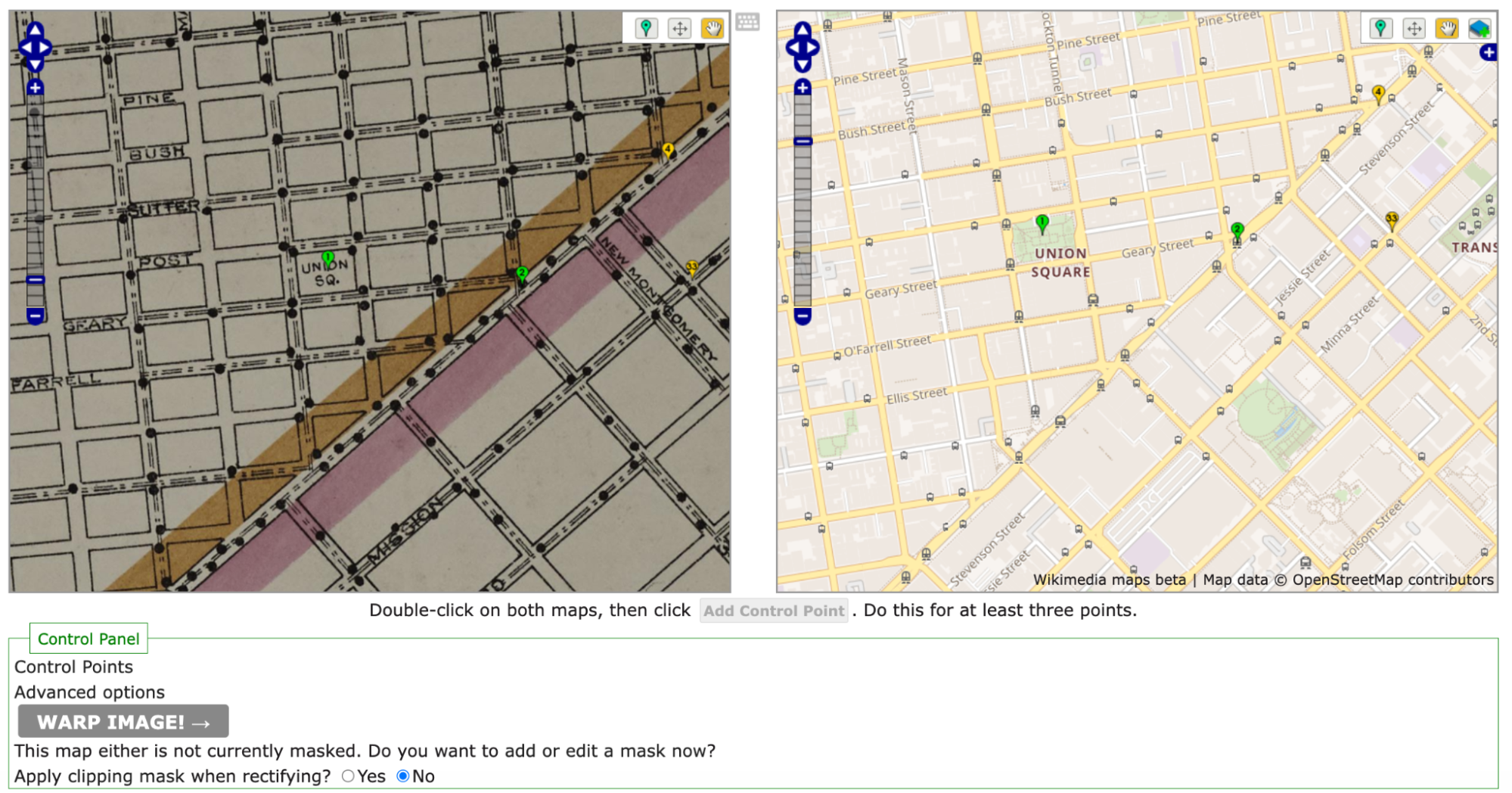
As noted above, the process of rectification involves matching the historic map against a contemporary map. To start, one needs at least four pins matching locations on each map. Personally, I like to start with some major landmarks. For example, I started by finding Union Square and putting pins on the same location in both maps. Once I was happy with my pins’ placement on both maps, I clicked the “add control point” button below the two maps.
Initial pins set in the historic map on the left and the OpenStreetMap on the right. note the navigation tools in the upper right corner of each panel.
Once I had four pins, I clicked the gray “warp image!” button. The four points were hardly enough and my map curled badly around my points.
To straighten out the map, I went back in and pinned the four corners of the map against the contemporary map. I also pinned several street corners because I wanted the rectified map to be as precisely aligned as possible.
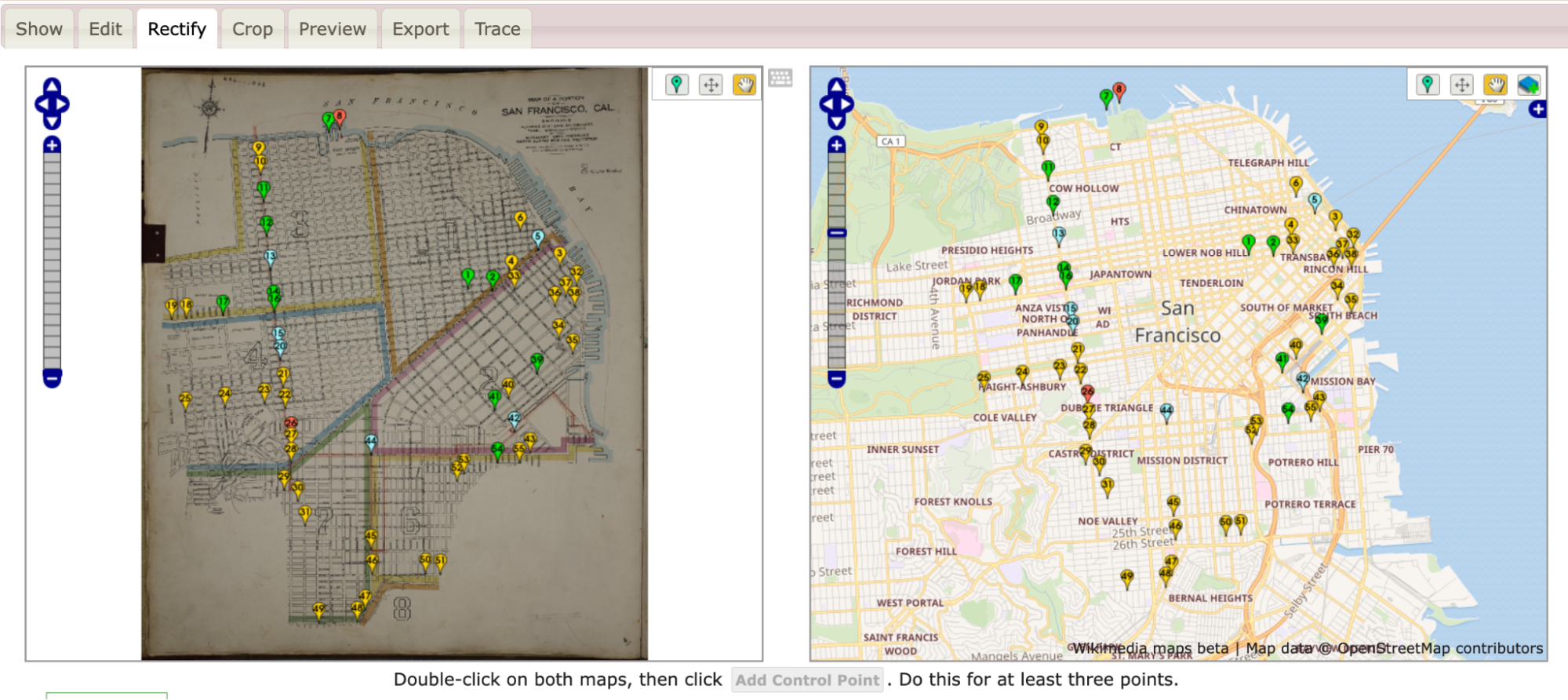
All said, I ended up with more than 40 pins (i.e., control points). As I went, I warped the image every few pins in order to save it and see where the image needed alignment.
Screen capture of Wikimaps with example of pins for warping.
As I added control points and warped my map, the pins shifted colors between greens, yellows, and reds with the occasional blue. The colors each demonstrated where the two maps were in exact alignment and where they were being pinched and, well, warped, to match.
Loading the warped map into ArcGIS Online as a layer
Once I was happy with the Sanborn image rectified against the OpenStreetMap that Wikimaps draws in, I was ready to export my work.
In this instance, I eventfully want to have two historic maps for layers and two sets of publisher data (1910s and 1950s).
To work with multiple layers, I needed to move away from Google My Maps and toward a more complex GIS program. Because UC Berkeley has a subscription to ArcGIS Online, I headed there. If I hadn’t had access to that online program, I’d have gone to QGIS. For an access point to ArcGIS online or for more on tools and access points, head to the UC Berkeley Library Research Guide for GIS (https://guides.lib.berkeley.edu/gis/tools).
I’d already set up my ArcGIS Online (AGOL) account, so I jumped straight in at https://cal.maps.arcgis.com/ and then clicked on the “Map” button in the upper-left navigation bar.
2024 Screen capture of ArcGIS Online Navigation Bar from login screen2024 add layer list in ArcGIS Online
On the Map screen, ArcGIS defaulted to a map of the United States in a Mercator projection. ArcGIS also had the “Layers” options opened in the left-hand tool bars.
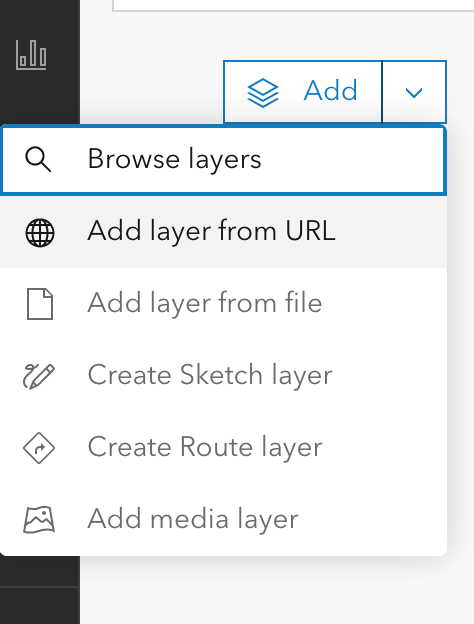
Because I didn’t yet have any layers except for my basemap, ArcGIS’s only option in “Layers” was “Add.”
Clicking on the down arrow to the right of “Add,” I selected “Add layer from URL.”
In response, ArcGIS Online gave me a popup box with a space for a URL.
Flipping back to ArcGIS Online, I pasted the tile link into the URL text box and made sure that the auto-populating “Type” information about the layer was accurate. I then hit a series of next to assure ArcGIS Online that I really did want to use this map.
Warning: Because I used a link, the resulting layer is drawn from Wikimaps every time I load my ArcGIS project. That does mean that if I had a poor internet connection, the map might take a hot minute to load or fail entirely. On UC Berkeley campus, that likely won’t be too much of an issue. Elsewhere, it might be.
Once my image layer loaded, I made sure I was aligned with San Francisco, and I saved my map with a relevant title. Good practice means that I also include a map description with the citation information to the Sanborn map layer so that viewers will know where my information is coming from.
2024 Screen capture of ArcGIS maps edit screen with rectified Sanborn map.
Once I’ve saved it, I can mess with share settings and begin offering colleagues and other publics the opportunity to see the lovely, rectified Sanborn map. I can also move toward adding additional layers.
Next Time
Next post, I plan to write about how I’m going to add my lovely 1955 publisher dataset on top of a totally different, 1950 San Francisco map as a new layer. Yay!




































{kind=link}
{kind=link}