 Founded in 1875, Al-Ahram (الأهرام, “The Pyramids”) is one of the longest-running newspapers in the Middle East. It has long been regarded as Egypt’s most authoritative and influential newspaper, and one of the most important newspapers in the Arab world, with a circulation of over 1 million. Prior to 1960, the newspaper was an independent publication and was renowned for its objectivity and independence. After being nationalized by President Nasser in 1960, Al-Ahram became the de facto voice of the Egyptian government and today the newspaper is managed by the Supreme Council of Press.
Founded in 1875, Al-Ahram (الأهرام, “The Pyramids”) is one of the longest-running newspapers in the Middle East. It has long been regarded as Egypt’s most authoritative and influential newspaper, and one of the most important newspapers in the Arab world, with a circulation of over 1 million. Prior to 1960, the newspaper was an independent publication and was renowned for its objectivity and independence. After being nationalized by President Nasser in 1960, Al-Ahram became the de facto voice of the Egyptian government and today the newspaper is managed by the Supreme Council of Press.
Year: 2023
Primary Sources: New content from ProQuest
Through an arrangement with the California Digital Library and ProQuest, the Library has access to additional historical digital archives, including:
- Latino Civil Rights During the Carter Administration, 1979-1981
- American Federation of Labor Records: The Samuel Gompers Era, 1877-1937
- Southern Life and African American History, Plantation Records, Part 3
- Southern Life and African American History, Plantation Records, Part 4
The historical newspaper holdings have also been expanded to include:
- The Hindustan times, 1924-2010
- Barron’s Magazine (1921-2007)
- Louisville Defender (1951-2010) & The Michigan Chronicle (1939-2010) Part of African American Historical Newspapers
- St. Petersburg/Tampa Bay Times (1901-2009) part of U.S. Regional Historical Newspapers
- London Evening Standard (1827-2010) Part of International Historical Newspapers
- The San Francsico Examiner (1965-2007) part of Western Regional Historical Newspapers
- In addition, access to the South China Morning Post has been extended to the years 1958-2001. Part of International Historical Newspapers
Native-American Heritage Month

Celebrate National Native American Heritage Month in November with us! We’ve put together a collection of fiction and non-fiction for you to explore. Find more information and discover live events on the Native American Heritage Month website.

Angela Sterritt

Lisa Bird-Wilson

Peter Stark

Rebecca Roanhorse

Stephen Graham Jones

Patty Krawec
Bancroft Quarterly Processing News
The archivists of The Bancroft Library are pleased to announce that in the past quarter (July-September 2023) we opened the following Bancroft archival collections to researchers.
General and UARC Collections:
Michael Paul Rogin papers (processed by Marjorie Bryer)
Acción Latina records and El Tecolote newspaper archive (processed by Marjorie Bryer)
Pam Levinson papers (processed by Presley Hubschmitt)
William Moore journals and other papers (processed by Lara Michels)
Renee Gregorio papers (processed by Simi Best)
Howard A. Brett collection of Panama Canal materials (processed by Lara Michels)
C. (Walter Clay) Lowdermilk papers (processed by Presley Hubschmitt)
Mosaic Law Congregation records (processed by Presley Hubschmitt)
Daniel Holmes collection of Sierra Club burro trips and Yosemite National Park backcountry research (processed by Jaime Henderson)
Triangle Gallery records (processed by Dean Smith)
Western Jewish History Center records (processed by Presley Hubschmitt)
Bransten and Rothmann family papers (processed by Presley Hubschmitt)
Friends of the River collection (transfer from UC Riverside; additional processing work by Lara Michels and Jaime Henderson)
George W. Barlow papers (processed by Jessica Tai)
Streetfare Journal records (processed by Lara Michels and student processing assistant Malayna Chang)
Roger Parodi collection of art museum and gallery announcements (processed by Lara Michels and student processing assistant David Eick)
Israel Louis Greenblat papers (processed by Presley Hubschmitt)
American Cultures Center records (processed by Jessica Tai)
Larry Orman archive of The Friends of the Stanislaus River materials (processed by Jaime Henderson)
Hamilton Boswell papers (digital materials processed by Christina Velazquez Fidler)
Pictorial Collections:
130 small collections and single items (approximately 6,650 items, total)
William F. Knowland’s gubernatorial campaign of 1958 photographs (and miscellaneous subjects added in Series 4 of the Lonnie Wilson archive)
3,155 new scans from Thérèse Bonney’s WWII era photographs from Finland, 1939, and France, Portugal, Belgium 1940
Collections Currently in Process:
Elizabeth A. Rauscher papers (Jessica Tai)
Associated Students of the University of California, Berkeley, records (Jessica Tai)
California Faience archive (Jaime Henderson)
Jan Kerouac papers (Marjorie Bryer)
Sister Makinya Sibeko-Kouate papers (Marjorie Bryer)
Nathan and Julia Hare papers (Marjorie Bryer)
Morris M. Goldstein papers (Presley Hubschmitt)
Hertzmann and Koshland family papers (Presley Hubschmitt)
Bush Street Synagogue Cultural Center records (Presley Hubschmitt and student processing assistant Malayna Chang)
Charles Muscatine papers–digital component (Christina Velazquez Fidler)
ruth weiss papers (Simi Best)
Townsend Berkeley Books Chat with Aglaya Glebova
Aleksandr Rodchenko: Photography in the Time of Stalin
with Aglaya Glebova
BERKELEY BOOK CHATS
Wednesday, Nov 8, 2023 12:00 pm – 1:00 pm
For more information, see the Townsend Website.

Through the lens of Aleksandr Rodchenko’s photography, Aglaya Glebova (History of Art) charts a new and provocative understanding of the troubled relationship between technology, modernism, and state power in Stalin’s Soviet Union.
Aleksandr Rodchenko: Photography in the Time of Stalin (Yale, 2023) traces the shifting meanings of photography in the early Soviet Union, as it reconsiders the relationship between art and politics during what is usually considered the end of the critical avant-garde. Aleksandr Rodchenko (1891–1956), a versatile Russian artist and one of Constructivism’s founders, embraced photography as a medium of revolutionary modernity. Yet his photographic work between the late 1920s and the end of the 1930s exhibits an expansive search for a different pictorial language.
In the context of the extreme transformations carried out under the first Five-Year Plans, Rodchenko’s photography questioned his own modernist commitments. At the heart of this book is Rodchenko’s infamous 1933 photo-essay on the White Sea-Baltic Canal, site of one of the first gulags. Glebova’s careful reading of Rodchenko’s photography reveals a surprisingly heterodox practice and brings to light experiments in adjacent media, including the collaborative design work Rodchenko undertook with Varvara Stepanova, his partner in art and life.
Glebova is joined by Harsha Ram (Slavic Languages & Literatures and Comparative Literature). After a brief discussion, they respond to questions from the audience.
Native American Heritage Month Art Resources
November is National Native American Heritage Month. Check out these online resources about Native American Art. Come see additional titles on display in the Art History/ Classics Library.



The Sweet Smell of Home Unsettling Native Art Histories… Women and Ledger Art



Shifting Grounds Mapping Modernisms Making History


Indigenuity Art for an Undivided Earth Art for a New Understanding
New Publication from Faculty Lisa Pieraccini

Art History Faculty Lisa Pieraccini has a new publication out titled Consumption, Ritual, Art and Society: Interpretive Approaches and Recent Discoveries of Food and Drink in Etruria (2023)
It will soon be available from UC Berkeley Library for loan.
From the Publisher:
Food determines who we are. We are what we eat, but also how we eat, with whom we eat, where we eat and, in some cases, even why we eat. Food production and consumption in the ancient world can express multiple dimensions of identity and negotiate belonging to, or exclusion from, cultural groups. It can bind through religious praxis, express wealth, manifest cultural identity, reveal differentiation in age or gender, and define status. As a prism through which to investigate the past, its utility is manifold. The chapters gathered together in this ground-breaking book explore the intersections between food, consumption, and ritual within Etruscan society through a purposeful cross-disciplinary approach. It offers a unique and innovative selection of up-to-date analysis from a variety of Etruscan food-related topics. From banqueting, feasting, fish rites, and symbolic consumption to bio-archaeological data, this volume explores a new and exciting field in ancient Italian archaeology.
PhiloBiblon 2023 n. 6 (octubre): PhiloBiblon White Paper
A requirement of the NEH Foundation grant for PhiloBiblon, “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept” (PW-277550-21) was the preparation of a White Paper to summarize its results and provide advice and suggestions for other projects that have enthusiastic volunteers but little money:
White Paper
NEH Grant PW-277550-21
October 10, 2023
The proposal for this grant, “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept,” submitted to NEH under the Humanities Collections and Reference Resources Foundations grant program, set forth the following goals:
This project will explore the use of the FactGrid: database for Historians Wikibase platform to prototype a low-cost light-weight development model for PhiloBiblon:
(1) show how to map PhiloBiblon’s complex data model to Linked Open Data (LD) / Resource Description Framework (RDF) as instantiated in Wikibase;
(2) evaluate the Wikibase data entry module and create prototype query modules based on the FactGrid Query Service;
(3) study Wikibase’s LD access points to and from libraries and archives;
(4) test the Wikibase data export module for JSON-LD, RDF, and XML on PhiloBiblon data,
(5) train PhiloBiblon staff in the use of the platform;
(6) place the resulting software and documentation on GitHub as the basis for a final “White Paper” and follow-on implementation project.
A Wikibase platform would position PhiloBiblon to take advantage of current and future semantic web developments and decrease long-term sustainability costs. Moreover, we hope to demonstrate that this project can serve as a model for low-cost light-weight database development for similar academic projects with limited resources.
PhiloBiblon is a free internet-based bio-bibliographical database of texts written in the various Romance vernaculars of the Iberian Peninsula during the Middle Ages and the early Renaissance. It does not contain the texts themselves; rather it attempts to catalog all their primary sources, both manuscript and printed, the texts they contain, the individuals involved with the production and transmission of those sources and texts, and the libraries holding them, along with relevant secondary references and authority files for persons, places, and institutions.
It is one of the oldest digital humanities projects in existence, and the oldest in the Hispanic world, starting out as an in-house database for the Dictionary of the Old Spanish Language project (DOSL) at the University of Wisconsin, Madison, in 1972, funded by NEH. Its initial purpose was to locate manuscripts and printed texts physically produced before 1501 to provide a corpus of authentic lexicographical material for DOSL. It soon became evident that the database would also be of interest to scholars elsewhere; and a photo-offset edition of computer printout was published in 1975 as the Bibliography of Old Spanish Texts (BOOST). It contained 977 records, each one listing a given text in a given manuscript or printed edition. A second edition followed in 1977 and a third in 1984.
PhiloBiblon was published in 1992 on CD-ROM, incorporating not only the materials in Spanish but also those in Portuguese and Catalan. By this time BOOST had been re-baptized as BETA (Bibliografía Española de Textos Antiguos), while the Portuguese corpus became BITAGAP (Bibliografia de Textos Antigos Galegos e Portugueses) and the Catalan corpus BITECA (Bibliografia de Textos Antics Catalans, Valencians i Balears). PhiloBiblon was ported to the web in 1997; and the web version was substantially re-designed in 2015. PhiloBiblon’s three databases currently hold over 240,000 records.
All of this data has been input manually by dozens of volunteer staff in the U.S., Spain, and Portugal, either by keyboarding or by cutting-and-pasting, thousands of hours of unpaid labor. That unpaid labor has been key to expanding the databases, but just as important, and much more difficult to achieve, has been the effort to keep up with the display and database technology. The initial database management system (DBMS) was FAMULUS running on the Univac 1110 at Madison, a flat-file DBMS originally developed at Berkeley in 1964. In 1985 the database was mapped to SPIRES (Stanford Public Information Retrieval System) and then, in 1987, to a proprietary relational DBMS, Revelation G, running on an IBM PC.
Today we continue to use Revelation Technology’s OpenInsight on Windows, the lineal descendent of Revelation G. We periodically export data from the Windows database in XML format and upload it to a server at Berkeley, where the XTF (eXtensible Text Framework) program suite parses it into individual records, indexes it, and serves it up on the fly in HTML format in response to queries from users around the world. The California Digital Library developed XTF as open source software ca. 2010, but it is now in the process of being phased out and is no longer supported by the UC Berkeley Library.
The need to find a substitute for XTF caused us to rethink our entire approach to the technologies that make PhiloBiblon possible. Major upgrades to the display and DBMS technology, either triggered by technological change or by a desire to enhance web access, have required significant grant support, primarily from NEH, eleven NEH grants from 1989 to 2021. We applied for the current grant in the hope that it would show us how to get off the technology merry-go-round. Instead of seeking major grant support every five to seven years for bespoke technology, this pilot project was designed to demonstrate that we could solve our technology problems for the foreseeable future by moving PhiloBiblon to Wikibase, the technology underlying Wikipedia and Wikidata. Maintained by Wikimedia Deutschland, the software development arm of the Wikimedia Foundation, Wikibase is made available for free. With Wikibase,we would no longer have to raise money to support our software infrastructure.
We have achieved all of the goals of the pilot project under this current grant and placed all of our software development work on GitHub (see below). We received a follow-on two-year implementation grant from NEH and on 1 July 2023 began work to map all of the PhiloBiblon data from the Windows DBMS to FactGrid.
❧ ❧ ❧
For the purposes of this White Paper, I shall focus on the PhiloBiblon pilot project as a model for institutions with limited resources for technology but dedicated volunteer staff. There are thousands of such institutions in the United States alone, in every part of the country, joined in national and regional associations, e.g., the American Association for State and Local History, Association of African American Museums, Popular Culture Association, Asian / Pacific / American Archives Survey Project, Southeastern Museums Conference. Many of their members are small institutions that depend on volunteer staff and could use the PhiloBiblon model to develop light-weight low-cost databases for their own projects. In the San Francisco Bay Area alone, for example there are dozens of such small cultural heritage institutions (e.g., The Beat Museum, GLBT Historical Society Archives, Holocaust Center Library and Archives, Berkeley Architectural History Association.
To begin at the beginning: What is Linked Open Data and why is it important?
What is Wikibase, why use it, and how does it work?
Linked Open Data (LOD) is the defining principle of the semantic web: “globally accessible and linked data on the internet based on the standards of the World Wide Web Consortium (W3C), an open environment where data can be created, connected and consumed on internet scale.”
Why use it? Simply, data has more value if it can be connected to other data, if it does not exist in a silo.
Wikibase in turn is the “free software for open data projects. It connects the knowledge of people and organizations and enables them to open their linked data to the world.” It is one of the backbone technologies of the LOD world.
Why use it? The primary reason to use Wikibase is precisely to make local or specialized knowledge easily available to the rest of the world by taking advantage of LOD, the semantic web. Conversely, the semantic web makes it easier for local institutions to take advantage of LOD.
How does Wikibase work? The Wikibase data model is deceptively simple. Each record has a “fingerprint” consisting of a Label, a Description, and an optional Alias. This fingerprint uniquely identifies the record. It can be repeated in multiple languages, although in every case the Label and the Description in the other languages must also be unique. Following the fingerprint header comes a series of three-part statements (triples, triplestores) that link a (1) subject Q to an (2) object Q by means of a (3) property P. The new record itself is the subject, to which Wikibase assigns automatically a unique Q#. There is no limit, except that of practicality, to the number of statements that a record can contain. They can be input in any order, and new statements are simply appended at the end of the record. No formal ontology is necessary, although having one is certainly useful, as librarians have discovered over the past sixty years. Must records start with a statement of identity, e.g.: Jack Keraouc (Q160534) [is an] Instance of (P31) Human (Q5).[1] Each statement can be qualified with sub-statements and footnoted with references. Because Wikibase is part of the LOD world, each record can be linked to the existing rich world of LOD identifiers: Jack Keraouc (Q160534) in the Union List of Artist Names ID (P245) is ID 500290917.
Another important reason for using Wikibase is the flexibility that it allows in tailoring Q items and P properties to the needs of the individual institution. There is no need to develop an ontology or schema ahead of time; it can be developed on the fly, so to speak. There is no need to establish a hierarchy of subject headings, for example, like that of the Library of Congress as set forth in the Library of Congress Subject Headings (LCSH). LC subject headings can be extended as necessary or entirely ignored. Other kinds of data can also be added:
New P properties to establish categories: nicknames, associates (e.g., other members of a rock band), musical or artistic styles);
New Q items related to the new P properties (e.g., the other members of the band).
There is no need to learn the Resource Description Access (RDA) rules necessary for highly structured data, such as MARC or its eventual replacement, BIBFRAME. This in turn means that data input does not need persons trained in librarianship.
How would adoption of Wikibase to catalog collections, whether of books, archival materials, or physical objects, work in practice? What decisions must be made? The first decision is simply whether (1) to join Wikidata or (2) set up a separate Wikibase instance (like FactGrid).[2] The former is far simpler. It requires no programming experience at all and very little knowledge of data science. Joining Wikidata simply means mapping the institution’s current database to Wikidata through a careful analysis of the database in comparison with Wikidata. For example, a local music history organization, like the SF Music Hall of Fame, might want to organize an archive of significant San Francisco musicians.
The first statement in the record of rock icon Jerry García might be Instance of (P31) Human (Q5); a second statement might be Sex or Gender (P21) Male (Q6581097); and a third, Occupation (P106) Guitarist (Q855091).
Once the institutional database properties have been matched to the corresponding Wikidata properties, the original database must be exported as a CSV (comma separated values) file. Its data must then be compared systematically to Wikidata through a process known as reconciliation, using the open source OpenRefine tool. This same reconciliation process can be used to compare the institutional database to a large number of other LOD services through Mix n Match, which lists hundreds of external databases in fields ranging alphabetically from Art to Video games. Thus the putative SF Music Hall of Fame database might be reconciled against the large Grammy Awards (5700 records) database of the Recording Academy.
Reconciliation is important because it establishes links between records in the institutional database and existing records in the LOD world. If there are no such records, the reconciliation process creates new records that automatically become part of the LOD world.
One issue to consider is that, like Wikipedia, anyone can edit Wikidata. This has both advantages and disadvantages. The advantage is that outside users can correct or expand records created by the institution. The disadvantage is that a malicious user or simply a well-intentioned but poorly informed one can also damage records by the addition of incorrect information.
In the implementation of the new NEH grant (2023-2025), we hope to have it both ways. Our new user interface will allow, let us say, a graduate student looking at a medieval Spanish manuscript in a library in Poland to add information about that manuscript through a template. However, before that information can be integrated into the master database, it would have to be vetted by a PhiloBiblon editorial committee.
The second option, to set up a separate Wikibase instance, is straightforward but not simple. The Wikibase documentation is a good place to start, but it assumes a fair amount of technical expertise. Matt Miller (currently at the Library of Congress) has provided a useful tutorial, Wikibase for Research Infrastructure , explaining how to set up a Wikibase instance and the steps required to go about it. Our programmer, Josep Formentí, has made this more conveniently available on a public GitHub repository, Wikibase Suite on Docker, which installs a standard collection of Wikibase services via Docker Compose V:
Wikibase
Query Service
QuickStatements
OpenRefine
Reconcile Service
The end result is a local Wikibase instance, like the one created by Formentí on a server at UC Berkeley as part of the new PhiloBiblon implementation grant: PhiloBiblon Wikibase instance. He used as his basis the suite of programs at Wikibase Release Pipeline. Formentí has also made available on GitHub his work on the PhiloBiblon user interface mentioned above. This would serve PhiloBiblon as an alternative to the standard Wikibase interface.
Once the local Wikibase instance has been created, it is essentially a tabula rasa. It has no Properties and no Items. The properties would then have to be created manually, based on the structure of the existing database or on Wikidata. By definition, the first property will be P1. Typically it will be “Instance of,” corresponding to Instance of (P31) in Wikidata.
The Digital Scriptorium project, a union catalog of medieval manuscripts in North American libraries now housed at the University of Pennsylvania, went through precisely this process when it mapped 67 data elements to Wikibase properties created specifically for that project. Thus property P1 states the Digital Scriptorium ID number; P2 states the current holding institution, etc.
Once the properties have been created, the next step is to import the data in a batch process, as described above, by reconciling it with existing databases. Miller explains alternative methods of batch uploads using python scripts.
Getting the initial upload of institutional data into Wikidata or a local Wikibase instance is the hard part, but once that initial upload has been accomplished, all data input from then on can be handled by non-technical staff. To facilitate the input of new records, properties can be listed in a spreadsheet in the canonical input order, with the P#, the Label, and a short Description. Most records will start with the P1 property “Institutional ID number” followed by the value of the identification number in the institutional database. The Cradle or Shape Expressions tools, with the list of properties in the right order, can generate a ready-made template for the creation of new records. Again, this is something that an IT specialist would implement during the initial setup of a local Wikibase instance.
New records can be created easily by inputting statements following the canonical order in the list of properties. New properties can also be created if it is found, over time, that relevant data is not being captured. For example, returning to the Jerry García example, it might be useful to specify “rock guitarist”(Q#) as a subclass of “guitarist.”
The institution would then need to decide whether the local Wikibase instance is to be open or closed. If it were entirely open, it would be like Wikidata, making crowd-sourcing possible. If it were closed, only authorized users could add or correct records. PhiloBiblon is exploring a third option for its user interface, crowdsourcing mediated by an editorial committee that would approve additions or changes before they could be added to the database.
One issue remains, searching:
Wikibase has two search modes, one of which is easy to use, and one of which is not.
- The basic search interface is the ubiquitous Google box. As the user types in a request, the potential records show up below it until the user sees and clicks on the requested record. If no match is found, the user can then opt to “Search for pages containing [the search term],” which brings up all the pages in which the search term occurs, although there is no way to sort them. They show up neither in alphabetical order of the Label nor in numerical order of the Q#.
- More precise and targeted searches must make use of the Wikibase Query Service, which opens a “SPARQL endpoint,” a window in which users can program queries using the SPARQL query language. SPARQL pronounced “sparkle,” is a recursive acronym for “SPARQL Protocol And RDF Query Language,” designed by and for the World Wide Web Consortium (WC3) as the standard language for LOD triplestores, just as SQL (Structured Query Language) is the standard language for relational database tables.
SPARQL is not for the casual user. It requires some knowledge of SPARQL or similar query languages as well as of the specifics of Wikibase items and properties. Many Wikibase installations offer “canned” SPARQL queries. In Wikidata, for example, one can use a canned query to find all of the pictures of the Dutch artist Jan Vermeer and plot their current locations on a map, with images of the pictures themselves. In fact, Wikidata offers over 400 examples of canned queries, each of which can then serve as a model for further queries.
How, then, to make more sophisticated searches available for those who do not wish to learn SPARQL?
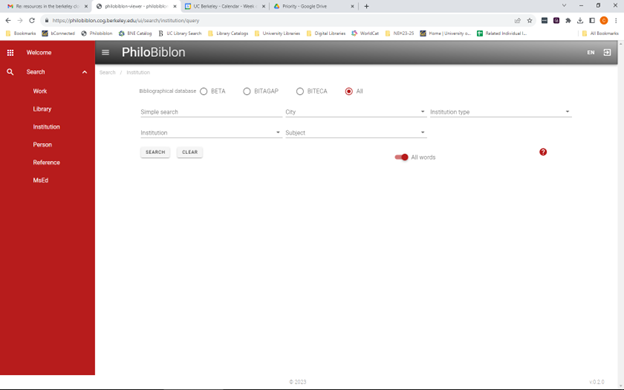
For PhiloBiblon we are developing masks or templates to facilitate searching for, e.g., persons, institutions, works. Thus, the institutions mask allows for searches for free text, the institution, its location, its type (e.g., university), and subject headings:
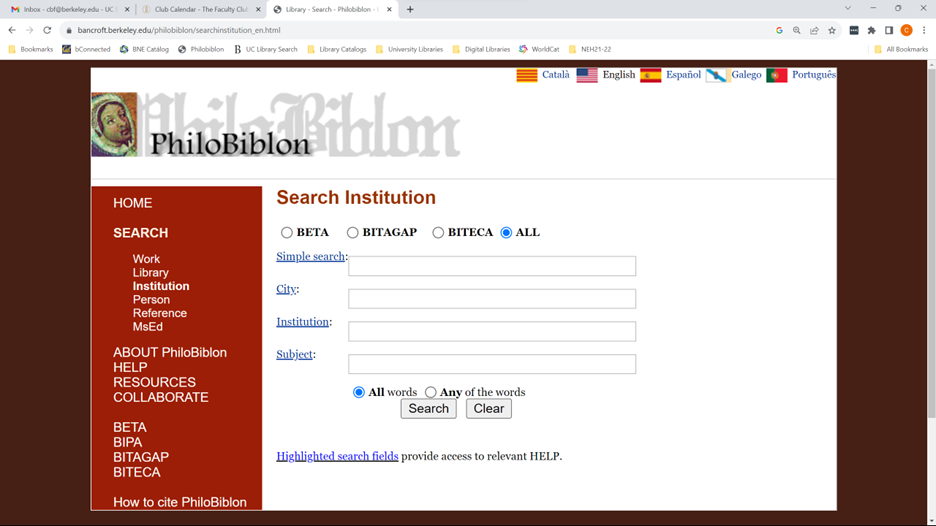
This mimics the search structure of the PhiloBiblon legacy website:
The use of templates does not, however, address the problem of searching across different types of objects or of providing different kinds of outputs. For example, one could not use such a template to plot the locations and dates of Franciscans active in Spain between 1450 and 1500. For this one needs a query language, i.e., SPARQL.
We have just begun to consider this problem under the new NEH implementation grant. It might be possible to use a Large Language Model query service such as ChatGPT or Bard as an interface to SPARQL. A user might send a prompt like this: “Write a SPARQL query for FactGrid to find all Franciscans active in Spain between 1450 and 1500 and plot their locations and dates on a map and a timeline.” This would automatically invoke the SPARQL query service and return the results to the user in the requested format.
Other questions and considerations will undoubtedly arise for any institution or project contemplating the use of Wikibase for its database needs. Nevertheless, we believe that we have demonstrated that this NEH-funded project can serve as a model for low-cost light-weight database development for small institutions or similar academic projects with limited resources.
Questions may be addressed to Charles Faulhaber (cbf@berkeley.edu).
[1] For the sake of convenience, I use the Wikidata Q# and P# numbers.
[2] For a balanced discussion of whether to join Wikidata or set up a local Wikibase instance, see Lozana Rossenova, Paul Duchesne, and Ina Blümel, “Wikidata and Wikibase as complementary research data management services for cultural heritage data.” The 3rd Wikidata Workshop, Workshop for the scientific Wikidata community, @ ISWC 2022, 24 October 2022. CEUR_WS, vol-3262.
Charles Faulhaber
University of California, Berkeley
Workshop Reminder — From Dissertation to Book: Navigating the Publication Process on November 9, 2023

Date/Time: Thursday, November 9, 2023, 11:00am–12:30pm
Location: Zoom only. Register via LibCal.
Hear from a panel of experts—an acquisitions editor, a first-time book author, and an author rights expert—about the process of turning your dissertation into a book. You’ll come away from this panel discussion with practical advice about revising your dissertation, writing a book proposal, approaching editors, signing your first contract, and navigating the peer review and publication process.
UC Berkeley Library to Copyright Office: Protect fair uses in AI training for research and education

We are pleased to share the UC Berkeley Library’s response to the U.S. Copyright Office’s Notice of Inquiry regarding artificial intelligence and copyright. Our response addresses the essential fair use right relied upon by UC Berkeley scholars in undertaking groundbreaking research, and the need to preserve access to the underlying copyright-protected content so that scholars using AI systems can conduct research inquiries.
In this blog post, we explain what the Copyright Office is studying, and why it was important for the Library to make scholars’ voices heard.
What the Copyright Office is studying and why
Loosely speaking, the Copyright Office wants to understand how to set policy for copyright issues raised by artificial intelligence (“AI”) systems.
Over the last year, AI systems and the rapid growth of their capabilities have attracted significant attention. One type of AI, referred to as “generative AI”, is capable of producing outputs such as text, images, video, or audio (including emulating a human voice) that would be considered copyrightable if created by a human author. These systems include, for instance, the chatbot ChatGPT, and text-to-image generators like DALL·E, Midjourney, and Stable Diffusion. A user can prompt ChatGPT to write a short story that features a duck and a frog who are best friends, or prompt DALL·E to create an abstract image in the style of a Jackson Pollock painting. Generative AI systems are relevant to and impact many educational activities on a campus like UC Berkeley, but (at least to date) have not been the key facilitator of campus research methodologies.
Instead, in the context of research, scholars have been relying on AI systems to support a set of research methodologies referred to as “text and data mining” (or TDM). TDM utilizes computational tools, algorithms, and automated techniques to extract revelatory information from large sets of unstructured or thinly-structured digital content. Imagine you have a book like “Pride and Prejudice.” There are nearly infinite volumes of information stored inside that book, depending on your scholarly inquiry, such as how many female vs. male characters there are, what types of words the female characters use as opposed to the male characters, what types of behaviors the female characters display relative to the males, etc. TDM allows researchers to identify and analyze patterns, trends, and relationships across volumes of data that would otherwise be impossible to sift through on a close examination of one book or item at a time.
Not all TDM research methodologies necessitate the usage of AI systems to extract this information. For instance, as in the “Pride and Prejudice” example above, sometimes TDM can be performed by developing algorithms to detect the frequency of certain words within a corpus, or to parse sentiments based on the proximity of various words to each other. In other cases, though, scholars must employ machine learning techniques to train AI models before the models can make a variety of assessments.
Here is an illustration of the distinction: Imagine a scholar wishes to assess the prevalence with which 20th century fiction authors write about notions of happiness. The scholar likely would compile a corpus of thousands or tens of thousands of works of fiction, and then run a search algorithm across the corpus to detect the occurrence or frequency of words like “happiness,” “joy,” “mirth,” “contentment,” and synonyms and variations thereof. But if a scholar instead wanted to establish the presence of fictional characters who embody or display characteristics of being happy, the scholar would need to employ discriminative modeling (a classification and regression technique) that can train AI to recognize the appearance of happiness by looking for recurring indicia of character psychology, behavior, attitude, conversational tone, demeanor, appearance, and more. This is not using a generative AI system to create new outputs, but rather training a non-generative AI system to predict or detect existing content. And to undertake this type of non-generative AI training, a scholar would need to use a large volume of often copyright-protected works.
The Copyright Office is studying both of these kinds of AI systems—that is, both generative AI and non-generative AI. They are asking a variety of questions in response to having been contacted by stakeholders across sectors and industries with diverse views about how AI systems should be regulated. Some of the concerns expressed by stakeholders include:
- Who is the “author” of generative AI outputs?
- Should people whose voices or images are used to train generative AI systems have a say in how their voices or images are used?
- Should the creator of an AI system (whether generative or non-generative) need permission from copyright holders to use copyright-protected materials in training the AI to predict and detect things?
- Should copyright owners get to opt out of having their content used to train AI? Should ethics be considered within copyright regulation?
Several of these questions are already the subject of pending litigation. While these questions are being explored by the courts, the Copyright Office wants to understand the entire landscape better as it considers what kinds of AI copyright regulations to enact.
The copyright law and policy landscape underpinning the use of AI models is complex, and whatever regulatory decisions that the Copyright Office makes will bear ramifications for global enterprise, innovation, and trade. The Copyright Office’s inquiry thus raises significant and timely legal questions, many of which we are only beginning to understand.
For these reasons, the Library has taken a cautious and narrow approach in its response to the inquiry: we address only two key principles known about fair use and licensing, as these issues bear upon the nonprofit education, research, and scholarship undertaken by scholars who rely on (typically non-generative) AI models. In brief, the Library wants to ensure that (1) scholars’ voices, and that of the academic libraries who support them, are heard to preserve fair use in training AI, and that (2) copyright-protected content remains available for AI training to support nonprofit education and research.
Why the study matters for fair use
Previous court cases like Authors Guild v. HathiTrust, Authors Guild v. Google, and A.V. ex rel. Vanderhye v. iParadigms have addressed fair use in the context of TDM and determined that the reproduction of copyrighted works to create and text mine a collection of copyright-protected works is a fair use. These cases further hold that making derived data, results, abstractions, metadata, or analysis from the copyright-protected corpus available to the public is also fair use, as long as the research methodologies or data distribution processes do not re-express the underlying works to the public in a way that could supplant the market for the originals. Performing all of this work is essential for TDM-reliant research studies.
For the same reasons that the TDM process is fair use of copyrighted works, the training of AI tools to do that TDM should also be fair use, in large part because training does not reproduce or communicate the underlying copyrighted works to the public. Here, there is an important distinction to make between training inputs and outputs, in that the overall fair use of generative AI outputs cannot always be predicted in advance: The mechanics of generative models’ operations suggest that there are limited instances in which generative AI outputs could indeed be substantially similar to (and potentially infringing of) the underlying works used for training; this substantial similarity is possible typically only when a training corpus is rife with numerous copies of the same work. However, the training of AI models by using copyright-protected inputs falls squarely within what courts have determined to be a transformative fair use, especially when that training is for nonprofit educational or research purposes. And it is essential to protect the fair use rights of scholars and researchers to make these uses of copyright-protected works when training AI.
Further, were these fair use rights overridden by limiting AI training access to only “safe” materials (like public domain works or works for which training permission has been granted via license), this would exacerbate bias in the nature of research questions able to be studied and the methodologies available to study them, and amplify the views of an unrepresentative set of creators given the limited types of materials available with which to conduct the studies.
Why access to AI training content should be preserved
For the same reasons, it is important that scholars’ ability to access the underlying content to conduct AI training be preserved. The fair use provision of the Copyright Act does not afford copyright owners a right to opt out of allowing other people to use their works for good reason: if content creators were able to opt out, the provision for fair use would be undermined, and little content would be available to build upon for the advancement of science and the useful arts. Accordingly, to the extent that the Copyright Office is considering creating a regulatory right for creators to opt out of having their works included in AI training, it is paramount that such opt-out provision not be extended to any AI training or activities that constitute fair use, particularly in the nonprofit educational and research contexts.
AI training opt-outs would be a particular threat for research and education because fair use in these contexts is already becoming an out-of-reach luxury even for the wealthiest institutions. Academic libraries are forced to pay significant sums each year to try to preserve fair use rights for campus scholars through the database and electronic content license agreements that libraries sign. In the U.S., the prospect of “contractual override” means that, although fair use is statutorily provided for, private parties (like publishers) may “contract around” fair use by requiring libraries to negotiate for otherwise lawful activities (such as conducting TDM or training AI for research), and often to pay additional fees for the right to conduct these lawful activities on top of the cost of licensing the content, itself. When such costs are beyond institutional reach, the publisher or vendor may then offer similar contractual terms directly to research teams, who may feel obliged to agree in order to get access to the content they need. Vendors may charge tens or even hundreds of thousands of dollars for this type of access.
This “pay-to-play” landscape of charging institutions for the opportunity to rely on existing statutory rights is particularly detrimental for TDM research methodologies, because TDM research often requires use of massive datasets with works from many publishers, including copyright owners that cannot be identified or who are unwilling to grant licenses. If the Copyright Office were to enable rightsholders to opt-out of having their works fairly used for training AI, then academic institutions and scholars would face even greater hurdles in licensing content for research purposes.
First, it would be operationally difficult for academic publishers and content aggregators to amass and license the “leftover” body of copyrighted works that remain eligible for AI training. Costs associated with publishers’ efforts in compiling “AI-training-eligible” content would be passed along as additional fees charged to academic libraries. In addition, rightsholders might opt out of allowing their work to be used for AI training fair uses, and then turn around and charge AI usage fees to scholars (or libraries)—essentially licensing back fair uses for research. These scenarios would impede scholarship by or for research teams who lack grant or institutional funds to cover these additional expenses; penalize research in or about underfunded disciplines or geographical regions; and result in bias as to the topics and regions studied.
Scholars need to be able to utilize existing knowledge resources to create new knowledge goods. Congress and the Copyright Office clearly understand the importance of facilitating access and usage rights, having implemented the statutory fair use provision without any exclusions or opt-outs. This status quo should be preserved for fair use AI training—and particularly in the nonprofit educational or research contexts.
Our office is here to help
No matter what happens with the Copyright Office’s inquiry and any regulations that ultimately may be established, the UCB Library’s Office of Scholarly Communication Services is here to help you. We are a team of copyright law and information policy (licensing, privacy, and ethics) experts who help UC Berkeley scholars navigate legal, ethical, and policy considerations in utilizing resources in their research and teaching. And we are national and international leaders in supporting TDM research—offering online tools, trainings, and individual consultations to support your scholarship. Please feel free to reach out to us with any questions at schol-comm@berkeley.edu.