A requirement of the NEH Foundation grant for PhiloBiblon, “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept” (PW-277550-21) was the preparation of a White Paper to summarize its results and provide advice and suggestions for other projects that have enthusiastic volunteers but little money:
White Paper
NEH Grant PW-277550-21
October 10, 2023
The proposal for this grant, “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept,” submitted to NEH under the Humanities Collections and Reference Resources Foundations grant program, set forth the following goals:
This project will explore the use of the FactGrid: database for Historians Wikibase platform to prototype a low-cost light-weight development model for PhiloBiblon:
(1) show how to map PhiloBiblon’s complex data model to Linked Open Data (LD) / Resource Description Framework (RDF) as instantiated in Wikibase;
(2) evaluate the Wikibase data entry module and create prototype query modules based on the FactGrid Query Service;
(3) study Wikibase’s LD access points to and from libraries and archives;
(4) test the Wikibase data export module for JSON-LD, RDF, and XML on PhiloBiblon data,
(5) train PhiloBiblon staff in the use of the platform;
(6) place the resulting software and documentation on GitHub as the basis for a final “White Paper” and follow-on implementation project.
A Wikibase platform would position PhiloBiblon to take advantage of current and future semantic web developments and decrease long-term sustainability costs. Moreover, we hope to demonstrate that this project can serve as a model for low-cost light-weight database development for similar academic projects with limited resources.
PhiloBiblon is a free internet-based bio-bibliographical database of texts written in the various Romance vernaculars of the Iberian Peninsula during the Middle Ages and the early Renaissance. It does not contain the texts themselves; rather it attempts to catalog all their primary sources, both manuscript and printed, the texts they contain, the individuals involved with the production and transmission of those sources and texts, and the libraries holding them, along with relevant secondary references and authority files for persons, places, and institutions.
It is one of the oldest digital humanities projects in existence, and the oldest in the Hispanic world, starting out as an in-house database for the Dictionary of the Old Spanish Language project (DOSL) at the University of Wisconsin, Madison, in 1972, funded by NEH. Its initial purpose was to locate manuscripts and printed texts physically produced before 1501 to provide a corpus of authentic lexicographical material for DOSL. It soon became evident that the database would also be of interest to scholars elsewhere; and a photo-offset edition of computer printout was published in 1975 as the Bibliography of Old Spanish Texts (BOOST). It contained 977 records, each one listing a given text in a given manuscript or printed edition. A second edition followed in 1977 and a third in 1984.
PhiloBiblon was published in 1992 on CD-ROM, incorporating not only the materials in Spanish but also those in Portuguese and Catalan. By this time BOOST had been re-baptized as BETA (Bibliografía Española de Textos Antiguos), while the Portuguese corpus became BITAGAP (Bibliografia de Textos Antigos Galegos e Portugueses) and the Catalan corpus BITECA (Bibliografia de Textos Antics Catalans, Valencians i Balears). PhiloBiblon was ported to the web in 1997; and the web version was substantially re-designed in 2015. PhiloBiblon’s three databases currently hold over 240,000 records.
All of this data has been input manually by dozens of volunteer staff in the U.S., Spain, and Portugal, either by keyboarding or by cutting-and-pasting, thousands of hours of unpaid labor. That unpaid labor has been key to expanding the databases, but just as important, and much more difficult to achieve, has been the effort to keep up with the display and database technology. The initial database management system (DBMS) was FAMULUS running on the Univac 1110 at Madison, a flat-file DBMS originally developed at Berkeley in 1964. In 1985 the database was mapped to SPIRES (Stanford Public Information Retrieval System) and then, in 1987, to a proprietary relational DBMS, Revelation G, running on an IBM PC.
Today we continue to use Revelation Technology’s OpenInsight on Windows, the lineal descendent of Revelation G. We periodically export data from the Windows database in XML format and upload it to a server at Berkeley, where the XTF (eXtensible Text Framework) program suite parses it into individual records, indexes it, and serves it up on the fly in HTML format in response to queries from users around the world. The California Digital Library developed XTF as open source software ca. 2010, but it is now in the process of being phased out and is no longer supported by the UC Berkeley Library.
The need to find a substitute for XTF caused us to rethink our entire approach to the technologies that make PhiloBiblon possible. Major upgrades to the display and DBMS technology, either triggered by technological change or by a desire to enhance web access, have required significant grant support, primarily from NEH, eleven NEH grants from 1989 to 2021. We applied for the current grant in the hope that it would show us how to get off the technology merry-go-round. Instead of seeking major grant support every five to seven years for bespoke technology, this pilot project was designed to demonstrate that we could solve our technology problems for the foreseeable future by moving PhiloBiblon to Wikibase, the technology underlying Wikipedia and Wikidata. Maintained by Wikimedia Deutschland, the software development arm of the Wikimedia Foundation, Wikibase is made available for free. With Wikibase,we would no longer have to raise money to support our software infrastructure.
We have achieved all of the goals of the pilot project under this current grant and placed all of our software development work on GitHub (see below). We received a follow-on two-year implementation grant from NEH and on 1 July 2023 began work to map all of the PhiloBiblon data from the Windows DBMS to FactGrid.
❧ ❧ ❧
For the purposes of this White Paper, I shall focus on the PhiloBiblon pilot project as a model for institutions with limited resources for technology but dedicated volunteer staff. There are thousands of such institutions in the United States alone, in every part of the country, joined in national and regional associations, e.g., the American Association for State and Local History, Association of African American Museums, Popular Culture Association, Asian / Pacific / American Archives Survey Project, Southeastern Museums Conference. Many of their members are small institutions that depend on volunteer staff and could use the PhiloBiblon model to develop light-weight low-cost databases for their own projects. In the San Francisco Bay Area alone, for example there are dozens of such small cultural heritage institutions (e.g., The Beat Museum, GLBT Historical Society Archives, Holocaust Center Library and Archives, Berkeley Architectural History Association.
To begin at the beginning: What is Linked Open Data and why is it important?
What is Wikibase, why use it, and how does it work?
Linked Open Data (LOD) is the defining principle of the semantic web: “globally accessible and linked data on the internet based on the standards of the World Wide Web Consortium (W3C), an open environment where data can be created, connected and consumed on internet scale.”
Why use it? Simply, data has more value if it can be connected to other data, if it does not exist in a silo.
Wikibase in turn is the “free software for open data projects. It connects the knowledge of people and organizations and enables them to open their linked data to the world.” It is one of the backbone technologies of the LOD world.
Why use it? The primary reason to use Wikibase is precisely to make local or specialized knowledge easily available to the rest of the world by taking advantage of LOD, the semantic web. Conversely, the semantic web makes it easier for local institutions to take advantage of LOD.
How does Wikibase work? The Wikibase data model is deceptively simple. Each record has a “fingerprint” consisting of a Label, a Description, and an optional Alias. This fingerprint uniquely identifies the record. It can be repeated in multiple languages, although in every case the Label and the Description in the other languages must also be unique. Following the fingerprint header comes a series of three-part statements (triples, triplestores) that link a (1) subject Q to an (2) object Q by means of a (3) property P. The new record itself is the subject, to which Wikibase assigns automatically a unique Q#. There is no limit, except that of practicality, to the number of statements that a record can contain. They can be input in any order, and new statements are simply appended at the end of the record. No formal ontology is necessary, although having one is certainly useful, as librarians have discovered over the past sixty years. Must records start with a statement of identity, e.g.: Jack Keraouc (Q160534) [is an] Instance of (P31) Human (Q5).[1] Each statement can be qualified with sub-statements and footnoted with references. Because Wikibase is part of the LOD world, each record can be linked to the existing rich world of LOD identifiers: Jack Keraouc (Q160534) in the Union List of Artist Names ID (P245) is ID 500290917.
Another important reason for using Wikibase is the flexibility that it allows in tailoring Q items and P properties to the needs of the individual institution. There is no need to develop an ontology or schema ahead of time; it can be developed on the fly, so to speak. There is no need to establish a hierarchy of subject headings, for example, like that of the Library of Congress as set forth in the Library of Congress Subject Headings (LCSH). LC subject headings can be extended as necessary or entirely ignored. Other kinds of data can also be added:
New P properties to establish categories: nicknames, associates (e.g., other members of a rock band), musical or artistic styles);
New Q items related to the new P properties (e.g., the other members of the band).
There is no need to learn the Resource Description Access (RDA) rules necessary for highly structured data, such as MARC or its eventual replacement, BIBFRAME. This in turn means that data input does not need persons trained in librarianship.
How would adoption of Wikibase to catalog collections, whether of books, archival materials, or physical objects, work in practice? What decisions must be made? The first decision is simply whether (1) to join Wikidata or (2) set up a separate Wikibase instance (like FactGrid).[2] The former is far simpler. It requires no programming experience at all and very little knowledge of data science. Joining Wikidata simply means mapping the institution’s current database to Wikidata through a careful analysis of the database in comparison with Wikidata. For example, a local music history organization, like the SF Music Hall of Fame, might want to organize an archive of significant San Francisco musicians.
The first statement in the record of rock icon Jerry García might be Instance of (P31) Human (Q5); a second statement might be Sex or Gender (P21) Male (Q6581097); and a third, Occupation (P106) Guitarist (Q855091).
Once the institutional database properties have been matched to the corresponding Wikidata properties, the original database must be exported as a CSV (comma separated values) file. Its data must then be compared systematically to Wikidata through a process known as reconciliation, using the open source OpenRefine tool. This same reconciliation process can be used to compare the institutional database to a large number of other LOD services through Mix n Match, which lists hundreds of external databases in fields ranging alphabetically from Art to Video games. Thus the putative SF Music Hall of Fame database might be reconciled against the large Grammy Awards (5700 records) database of the Recording Academy.
Reconciliation is important because it establishes links between records in the institutional database and existing records in the LOD world. If there are no such records, the reconciliation process creates new records that automatically become part of the LOD world.
One issue to consider is that, like Wikipedia, anyone can edit Wikidata. This has both advantages and disadvantages. The advantage is that outside users can correct or expand records created by the institution. The disadvantage is that a malicious user or simply a well-intentioned but poorly informed one can also damage records by the addition of incorrect information.
In the implementation of the new NEH grant (2023-2025), we hope to have it both ways. Our new user interface will allow, let us say, a graduate student looking at a medieval Spanish manuscript in a library in Poland to add information about that manuscript through a template. However, before that information can be integrated into the master database, it would have to be vetted by a PhiloBiblon editorial committee.
The second option, to set up a separate Wikibase instance, is straightforward but not simple. The Wikibase documentation is a good place to start, but it assumes a fair amount of technical expertise. Matt Miller (currently at the Library of Congress) has provided a useful tutorial, Wikibase for Research Infrastructure , explaining how to set up a Wikibase instance and the steps required to go about it. Our programmer, Josep Formentí, has made this more conveniently available on a public GitHub repository, Wikibase Suite on Docker, which installs a standard collection of Wikibase services via Docker Compose V:
Wikibase
Query Service
QuickStatements
OpenRefine
Reconcile Service
The end result is a local Wikibase instance, like the one created by Formentí on a server at UC Berkeley as part of the new PhiloBiblon implementation grant: PhiloBiblon Wikibase instance. He used as his basis the suite of programs at Wikibase Release Pipeline. Formentí has also made available on GitHub his work on the PhiloBiblon user interface mentioned above. This would serve PhiloBiblon as an alternative to the standard Wikibase interface.
Once the local Wikibase instance has been created, it is essentially a tabula rasa. It has no Properties and no Items. The properties would then have to be created manually, based on the structure of the existing database or on Wikidata. By definition, the first property will be P1. Typically it will be “Instance of,” corresponding to Instance of (P31) in Wikidata.
The Digital Scriptorium project, a union catalog of medieval manuscripts in North American libraries now housed at the University of Pennsylvania, went through precisely this process when it mapped 67 data elements to Wikibase properties created specifically for that project. Thus property P1 states the Digital Scriptorium ID number; P2 states the current holding institution, etc.
Once the properties have been created, the next step is to import the data in a batch process, as described above, by reconciling it with existing databases. Miller explains alternative methods of batch uploads using python scripts.
Getting the initial upload of institutional data into Wikidata or a local Wikibase instance is the hard part, but once that initial upload has been accomplished, all data input from then on can be handled by non-technical staff. To facilitate the input of new records, properties can be listed in a spreadsheet in the canonical input order, with the P#, the Label, and a short Description. Most records will start with the P1 property “Institutional ID number” followed by the value of the identification number in the institutional database. The Cradle or Shape Expressions tools, with the list of properties in the right order, can generate a ready-made template for the creation of new records. Again, this is something that an IT specialist would implement during the initial setup of a local Wikibase instance.
New records can be created easily by inputting statements following the canonical order in the list of properties. New properties can also be created if it is found, over time, that relevant data is not being captured. For example, returning to the Jerry García example, it might be useful to specify “rock guitarist”(Q#) as a subclass of “guitarist.”
The institution would then need to decide whether the local Wikibase instance is to be open or closed. If it were entirely open, it would be like Wikidata, making crowd-sourcing possible. If it were closed, only authorized users could add or correct records. PhiloBiblon is exploring a third option for its user interface, crowdsourcing mediated by an editorial committee that would approve additions or changes before they could be added to the database.
One issue remains, searching:
Wikibase has two search modes, one of which is easy to use, and one of which is not.
- The basic search interface is the ubiquitous Google box. As the user types in a request, the potential records show up below it until the user sees and clicks on the requested record. If no match is found, the user can then opt to “Search for pages containing [the search term],” which brings up all the pages in which the search term occurs, although there is no way to sort them. They show up neither in alphabetical order of the Label nor in numerical order of the Q#.
- More precise and targeted searches must make use of the Wikibase Query Service, which opens a “SPARQL endpoint,” a window in which users can program queries using the SPARQL query language. SPARQL pronounced “sparkle,” is a recursive acronym for “SPARQL Protocol And RDF Query Language,” designed by and for the World Wide Web Consortium (WC3) as the standard language for LOD triplestores, just as SQL (Structured Query Language) is the standard language for relational database tables.
SPARQL is not for the casual user. It requires some knowledge of SPARQL or similar query languages as well as of the specifics of Wikibase items and properties. Many Wikibase installations offer “canned” SPARQL queries. In Wikidata, for example, one can use a canned query to find all of the pictures of the Dutch artist Jan Vermeer and plot their current locations on a map, with images of the pictures themselves. In fact, Wikidata offers over 400 examples of canned queries, each of which can then serve as a model for further queries.
How, then, to make more sophisticated searches available for those who do not wish to learn SPARQL?
For PhiloBiblon we are developing masks or templates to facilitate searching for, e.g., persons, institutions, works. Thus, the institutions mask allows for searches for free text, the institution, its location, its type (e.g., university), and subject headings:
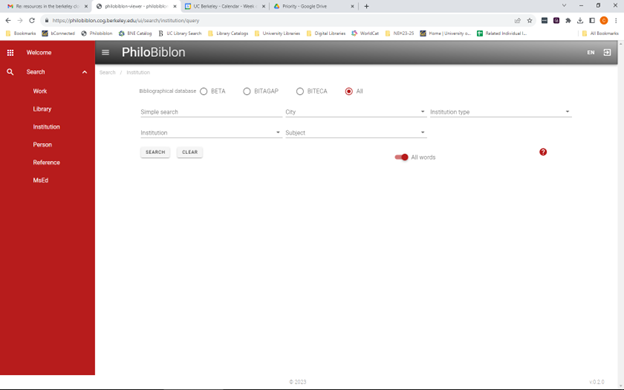
This mimics the search structure of the PhiloBiblon legacy website:
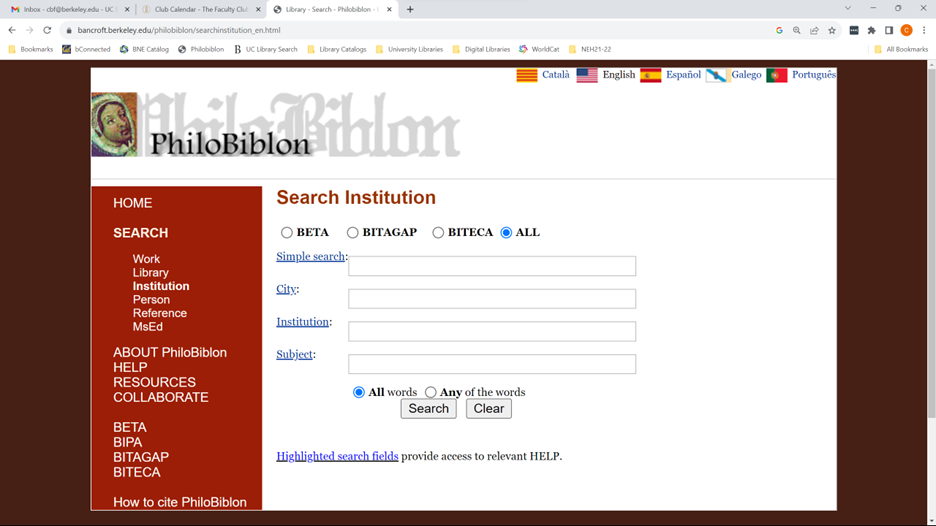
The use of templates does not, however, address the problem of searching across different types of objects or of providing different kinds of outputs. For example, one could not use such a template to plot the locations and dates of Franciscans active in Spain between 1450 and 1500. For this one needs a query language, i.e., SPARQL.
We have just begun to consider this problem under the new NEH implementation grant. It might be possible to use a Large Language Model query service such as ChatGPT or Bard as an interface to SPARQL. A user might send a prompt like this: “Write a SPARQL query for FactGrid to find all Franciscans active in Spain between 1450 and 1500 and plot their locations and dates on a map and a timeline.” This would automatically invoke the SPARQL query service and return the results to the user in the requested format.
Other questions and considerations will undoubtedly arise for any institution or project contemplating the use of Wikibase for its database needs. Nevertheless, we believe that we have demonstrated that this NEH-funded project can serve as a model for low-cost light-weight database development for small institutions or similar academic projects with limited resources.
Questions may be addressed to Charles Faulhaber (cbf@berkeley.edu).
[1] For the sake of convenience, I use the Wikidata Q# and P# numbers.
[2] For a balanced discussion of whether to join Wikidata or set up a local Wikibase instance, see Lozana Rossenova, Paul Duchesne, and Ina Blümel, “Wikidata and Wikibase as complementary research data management services for cultural heritage data.” The 3rd Wikidata Workshop, Workshop for the scientific Wikidata community, @ ISWC 2022, 24 October 2022. CEUR_WS, vol-3262.
Charles Faulhaber
University of California, Berkeley