This post was written by Tim Vollmer, Anna Sackmann, and Elliott Smith
U.S. Federal agency logos, public domain.
Are you a UC Berkeley faculty or researcher publishing results arising through federal grant funding?
Starting in 2026, research funded by all federal agencies will be made freely and immediately available to the public, with no embargo. Some agencies have already updated their public access plans, including the National Institutes of Health, which went into effect on July 1, 2025. All federal agencies must update their public access policies no later than December 31st, 2025.
Join UC Berkeley Library staff on Wednesday, January 14, 2026 from 1:00-2:00 pm on Zoom for an overview of federal agency public access policies affecting research publication and data, and what you need to do as an author.
We’ll cover essential requirements for a variety of federal agency funders such as the Department of Energy, National Institutes of Health, National Science Foundation, and more. We’ll unpack publication and data deposit procedures, review publisher challenges to compliance, and highlight related UC open access publishing support.
Participants will leave with clear takeaways on what they need to do to meet public access requirements, the tools they can utilize, and where to find ongoing support.
The workshop presentation will be recorded and distributed to registrants afterward.
We are delighted to provide information on the Spring 2025 Digital Humanities Faire at UC Berkeley. The continuation of more than a decade of tradition, these DH Faires are designed to celebrate the broad, interdisciplinary digital humanities projects at UC Berkeley.
Keynote
dana boyd is presenting “Data are Made, Not Found” on Wednesday, April 23, 2025 5-6:30pm, Jacobs Institute for Design Innovation, Studio 310 (for more on the talk).
Poster Display:
Tuesday and Wednesday, April 22 and 23, 2025, Poster Display, Doe Library 2nd floor Reference Hall (see attached image with star).
The Gold Start shows the location of the Doe Library, 2nd floor Reference Hall
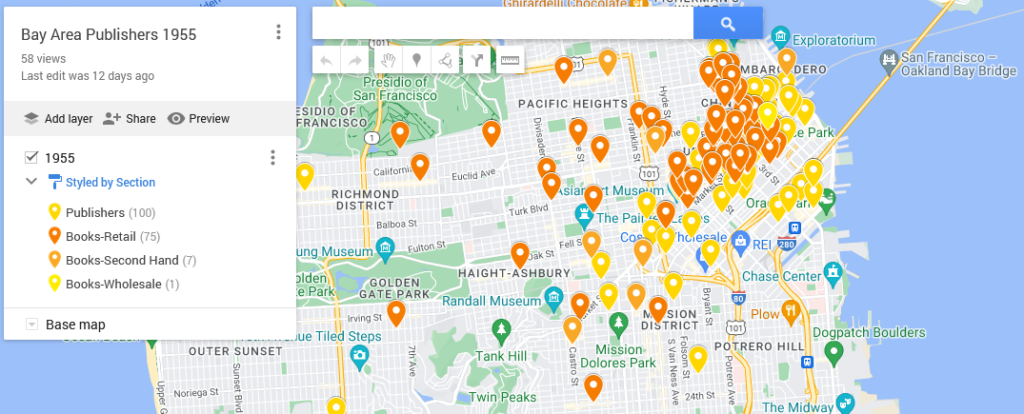
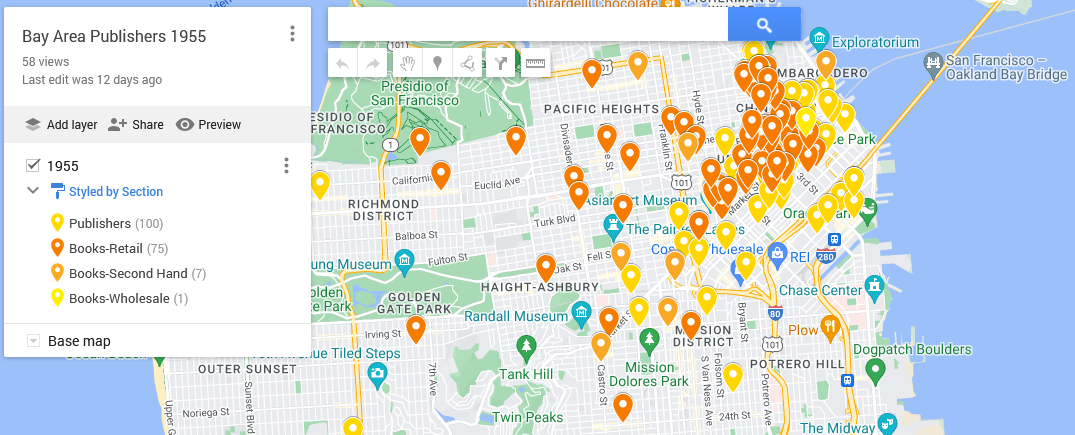
This map shows the locations of the bookstores, printers, and publishers in San Francisco in 1955 according to Polk’s Directory (SFPL link). The map highlights the quantity thereof as well as their centrality in the downtown. That number combined with location suggests that publishing was a thriving industry.
Using my 1955 publishing dataset in Google My Maps (https://www.google.com/maps/d) I have linked the directory addresses of those business categories with a contemporary street map and used different colors to highlight the different types. The contemporary street map allows people to get a sense of how the old data compares to what they know (if anything) about the modern city.
My initial Google My Map, however, was a bit hard to see because of the lack of contrast between my points as well as how they blended in with the base map. One of the things that I like to keep in mind when working with digital tools is that I can often change things. Here, I’m going to poke at and modify my
Base map
Point colors
Information panels
Sharing settings
My goal in doing so is to make the information I want to understand for my research more visible. I want, for example, to be able to easily differentiate between the 1955 publishing and printing houses versus booksellers. Here, contrasting against the above, is the map from the last post:
Click on the map for the last post in this series.
Quick Reminder About the Initial Map
To map data with geographic coordinates, one needs to head to a GIS program (US.gov discussion of). In part because I didn’t yet have the latitude and longitude coordinates filled in, I headed over to Google My Maps. I wrote about this last post, so I shan’t go into much detail. Briefly, those steps included:
Logging into Google My Maps (https://www.google.com/maps/d/)
Clicking the “Create a New Map” button
Uploading the data as a CSV sheet (or attaching a Google Sheet)
Naming the Map something relevant
Now that I have the map, I want to make the initial conclusions within my work from a couple weeks ago stand out. To do that, I logged back into My Maps and opened up the saved “Bay Area Publishers 1955.”
Base Map
One of the reasons that Google can provide My Maps at no direct charge is because of their advertising revenue. To create an effective visual, I want to be able to identify what information I have without losing my data among all the ads.
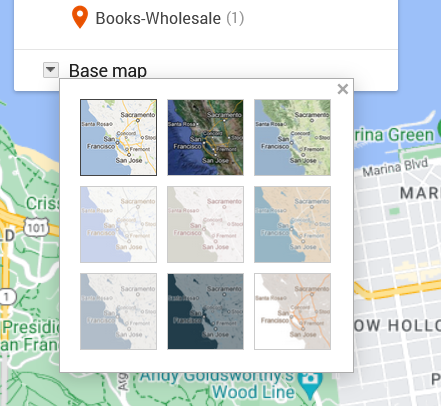
Screen capture from 2024 showing thumbnails for possible base map design.
To move in that direction, I head over to the My Map edit panel where there is a “Base map” option with a down arrow. Hitting that down arrow, I am presented with an option of nine different maps. What works for me at any given moment depends on the type of information I want my data paired with.
The default for Google Maps is a street map. That street map emphasizes business locations and roads in order to look for directions. Some of Google’s My Maps’ other options focus on geographic features, such as mountains or oceans. Because I’m interested in San Francisco publishing, I want a sense of the urban landscape and proximity. I don’t particularly need a map focused on ocean currents. What I do want is a street map with dimmer colors than Google’s standard base map so that my data layer is distinguishable from Google’s landmarks, stores, and other points of interest.
Nonetheless, when there are only nine maps available, I like to try them all. I love maps and enjoy seeing the different options, colors, and features, despite the fact that I already know these maps well.
The options that I’m actually considering are “Light Political” (option center left in the grid) “Mono City” (center of the grid) or “White Water” (bottom right). These base map options focus on that lighter-toned background I want, which allows my dataset points to stand clearly against them.
For me, “Light Political” is too pale. With white streets on light gray, the streets end up sinking into the background, losing some of the urban landscape that I’m interested in. The bright, light blue of the ocean also draws attention away from the city and toward the border, which is precisely what it wants to do as a political map.
I like “Mono City” better as it allows my points to pop against a pale background while the ocean doesn’t draw focus to the border.
Of these options, however, I’m going to go with the “White Water” street map. Here, the city is done up with various grays and oranges, warming the map in contrast to “Mono City.” The particular style also adds detail to some of the geographic landmarks, drawing attention to the city as a lived space. Consequently, even though the white water creeps me out a bit, this map gets closest to what I want in my research’s message. I also know that for this data set, I can arrange the map zoom to limit the amount of water displayed on the screen.
Point colors
Now that I’ve got my base map, I’m on to choosing point colors. I want them to reflect my main research interests, but I’ve also got to pick within the scope of the limited options that Google provides.
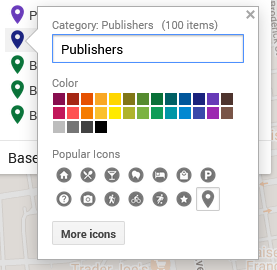
Color choices and symbols one can use for points as of 2024.
I head over to the Edit/Data pane in the My Maps interface. There, I can “Style” the dataset. Specifically, I can tell the GIS program to color my markers by the information in any one of my columns. I could have points all colored by year (here, 1955) or state (California), rendering them monochromatic. I could go by latitude or name and individually select a color for each point. If I did that, I’d run up against Google’s limited, 30-color palette and end up with lots of random point colors before Google defaulted to coloring the rest gray.
What I choose here is the types of business, which are listed under the column labeled “section.”
In that column, I have publishers, printers, and three different types of booksellers:
Printers-Book and Commercial
Publishers
Books-Retail
Books-Second Hand
Books-Wholesale
To make these stand out nicely against my base map, I chose contrasting colors. After all, using contrasting colors can be an easy way to make one bit of information stand out against another.
In this situation, my chosen base map has quite a bit of light grays and oranges. Glancing at my handy color wheel, I can see purples are opposite the oranges. Looking at the purples in Google’s options, I choose a darker color to contrast the light map. That’s one down.
For the next, I want Publishers to compliment Printers but be a clearly separate category. To meet that goal, I picked a darker purply-blue shade.
Moving to Books-Retail, I want them to stand as a separate category from the Printers and Publishers. I want them to complement my purples and still stand out against the grays and oranges. To do that, I go for one of Google’s dark greens.
Looking at the last two categories, I don’t particularly care if people can immediately differentiate the second-hand or wholesale bookstores from the retail category. Having too many colors can also be distracting. To minimize clutter of message, I’m going to make all the bookstores the same color.
Pop-ups/ Information Dock
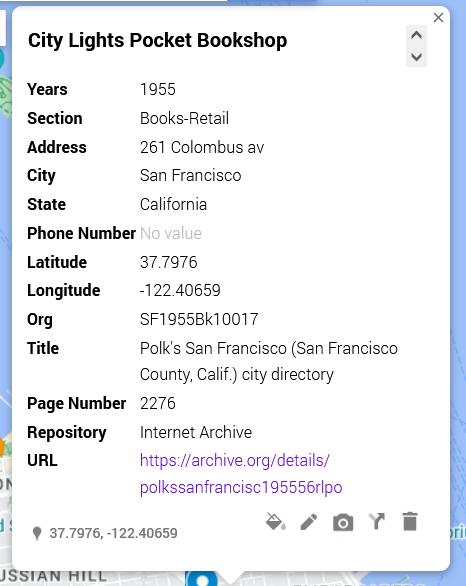
Example of editable data from data sheet row.
For this dataset, the pop-ups are not overly important. What matters for my argument here is the spread. Nonetheless, I want to be aware of what people will see if they click on my different data points.
[Citylights pop-up right]
In this shot, I have an example of what other people will see. Essentially, it’s all of the columns converted to a single-entry form. I can edit these if desired and—importantly—add things like latitude and longitude.
The easiest way to drop information from the pop-up is to delete the column from the data sheet and re-import the data.
Sharing
As I finish up my map, I need to decide whether I want to keep it private (the default) or share it. Some of my maps, I keep private because they’re lists of favorite restaurants or loosely planned vacations. For example, a sibling is planning on getting married in Cadiz in Spain, and I have a map tagging places I am considering for my travel itinerary.
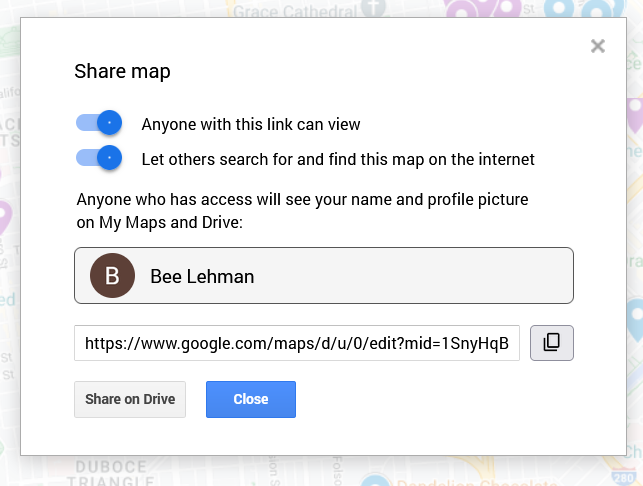
“Share map” pop up with options for making a map available.
Here, in contrast, I want friends and fellow interested parties to be able to see it and find it. To make sure that’s possible, I clicked on “Share” above my layers. On the pop-up (as figured here) I switched the toggles to allow “Anyone with this link [to] view” and “Let others search for and find this map on the internet.” The latter, in theory, will permit people searching for 1955 publishing data in San Francisco to find my beautiful, high-contrast map.
Important: This is also where I can find the link to share the published version of the map. If I pull the link from the top of my window, I’d share the editable version. Be aware, however, that the editable and public versions look a pinch different. As embedded at the top of this post, the published version will not allow the viewer to edit the material and will have the sidebar for showing my information, as opposed to the edit view’s pop-ups.
Next steps
To see how those institutions sit in the 1950s world, I am inclined to see how those plots align across a 1950s San Francisco map. To do that, I’d need to find an appropriate map and add a layer under my dataset. At this time, however, Google Maps does not allow me to add image and/or map layers. So, in two weeks I’ll write about importing image layers into Esri’s ArcGIS.
Last post, I promised to talk about using structured data with a dataset focused on 1950s Bay Area publishing. To get into that topic, I’m going to talk about 1) setting out with a research question as well as 2) data discovery, and 3) data organization, in order to do 4) initial mapping.
Background to my Research
When I moved to the Bay Area, I (your illustrious Literatures and Digital Humanities Librarian) started exploring UC Berkeley’s collections. I wandered through the Doe Library’s circulating collections and started talking to our Bancroft staff about the special library and archive’s foci. As expected, one of UC Berkeley’s collecting areas is California publishing, with a special emphasis on poetry.
Mock-up of ad for books by Allen Ginsberg, City Lights Books Records, 1953-1970, Bancroft Library.
In fact, some of Bancroft’s oft-used materials are the City Light Books collections (link to finding aids in the Online Archive of California) that include some of Allen Ginsberg’s pre-publication drafts of “Howl” and original copies of Howl and Other Poems. You may already know about that poem because you like poetry, or because you watch everything with Daniel Radcliffe in it (IMDB on the 2013 Kill your Darlings). This is, after all, the very poem that led to the seminal trial that influenced U.S. free speech and obscenity laws (often called The Howl Obscenity Trial) . The Bancroft collections have quite a bit about that trial as well as some of Ginsberg’s correspondence with Lawrence Ferlinghetti (poet, bookstore owner, and publisher) during the harrowing legal case. (You can a 2001 discussion with Ferlinghetti on the subject here.)
Research Question
Interested in learning more about Bay Area publishing in general and the period in which Ginsberg’s book was written in particular, I decided to look into the Bay Area publishing environment during the 1950s and now (2020s), starting with the early period. I wanted a better sense of the environment in general as well as public access to books, pamphlets, and other printed material. In particular, I wanted to start with the number of publishers and where they were.
Data Discovery
For a non-digital, late 19th and 20th century era, one of the easiest places to start getting a sense of mainstream businesses is to look in city directories. There was a sweet spot in an era of mass printing and industrialization in which city directories were one of the most reliable sources of this kind of information, as the directory companies were dedicated to finding as much information as possible about what was in different urban areas and where men and businesses were located. The directories, as a guide to finding business, people, and places, were organized in a clear, columned text, highly standardized and structured in order to promote usability.
Raised in an era during which city directories were still a normal thing to have at home, I already knew these fat books existed. Correspondingly, I set forth to find copies of the directories from the 1950s when “Howl” first appeared. If I hadn’t already known, I might have reached out to my librarian to get suggestions (for you, that might be me).
I knew that some of the best places to find material like city directories were usually either a city library or a historical society. I could have gone straight to the San Francisco Public Library’s website to see if they had the directories, but I decided to go to Google (i.e., a giant web index) and search for (historic san francisco city directories). That search took me straight to the SFPL’s San Francisco City Directories Online (link here).
On the site, I selected the volumes I was interested in, starting with Polk’s Directory for 1955-56. The SFPL pages shot me over to the Internet Archive and I downloaded the volumes I wanted from there.
Once the directory was on my computer, I opened it and took a look through the “yellow pages” (i.e., pages with information sorted by business type) for “publishers.”
Note the dense columns of text almost overlap. From R.L. Polk & Co, Polk’s San Francisco City Directory, vol. 1955–1956 (San Francisco, Calif. : R.L. Polk & Co., 1955), Internet Archive. | Public Domain.
Glancing through the listings, I noted that the records for “publishers” did not list City Light Books. Flipped back to “book sellers,” I found it. That meant that other booksellers could be publishers as well. And, regardless, those booksellers were spaces where an audience could acquire books (shocker!) and therefore relevant. Considering the issue, I also looked at the list for “printers,” in part to capture some of the self-publishing spaces.
I now had three structured lists from one directory with dozens of names. Yet, the distances within the book and inability to reorganize made them difficult to consider together. Furthermore, I couldn’t map them with the structure available in the directory. In order to do what I wanted with them (i.e., meet my research goals), I needed to transform them into a machine readable data set.
Creating a Data Set
Machine Readable
I started by doing a one-to-one copy. I took the three lists published in the directory and ran OCR across them in Adobe Acrobat Professional (UC Berkeley has a subscription; for OA access I recommend Transkribus or Tesseract), and then copied the relevant columns into a Word document.
Data Cleaning
The OCR copy of the list was a horrifying mess with misspellings, cut-off words, Ss understood as 8s, and more. Because this was a relatively small amount of data, I took the time to clean the text manually. Specifically, I corrected typos and then set up the text to work with in Excel (Google Sheets would have also worked) by:
creating line breaks between entries,
putting tabs between the name of each institution and corresponding address
Once I’d cleaned the data, I copied the text into Excel. The line breaks functioned to tell Excel where to break rows and the tabs where to understand columns. Meaning:
Each institution had its own row.
The names of the institutions and their addresses were in different columns.
Having that information in different spaces would allow me to sort the material either by address or back to its original organization by company name.
Adding Additional Information
I had, however, three different types of institutions—Booksellers, Printers, and Publishers—that I wanted to be able to keep separate. With that in mind, I added a column for EntryType (written as one word because many programs have issues with understanding column headers with spaces) and put the original directory headings into the relevant rows.
Knowing that I also wanted to map the data, I also added a column for “City” and another for “State” as the GIS (i.e., mapping) programs I planned to use wouldn’t automatically know which urban areas I meant. For these, I wrote the name of the city (i.e., “San Francisco”) and then the state (i.e., “California”) in their respective columns and autofilled the information.
Next, for record keeping purposes, I added columns for where I got the information, the page I got it from, and the URL for where I downloaded it. That information simultaneously served for me as a reminder but also as a pointer for anyone else who might want to look at the data and see the source directly.
I put in a column for Org/ID for later, comparative use (I’ll talk more about this one in a further post,) and then added columns for Latitude and Longitude for eventual use.
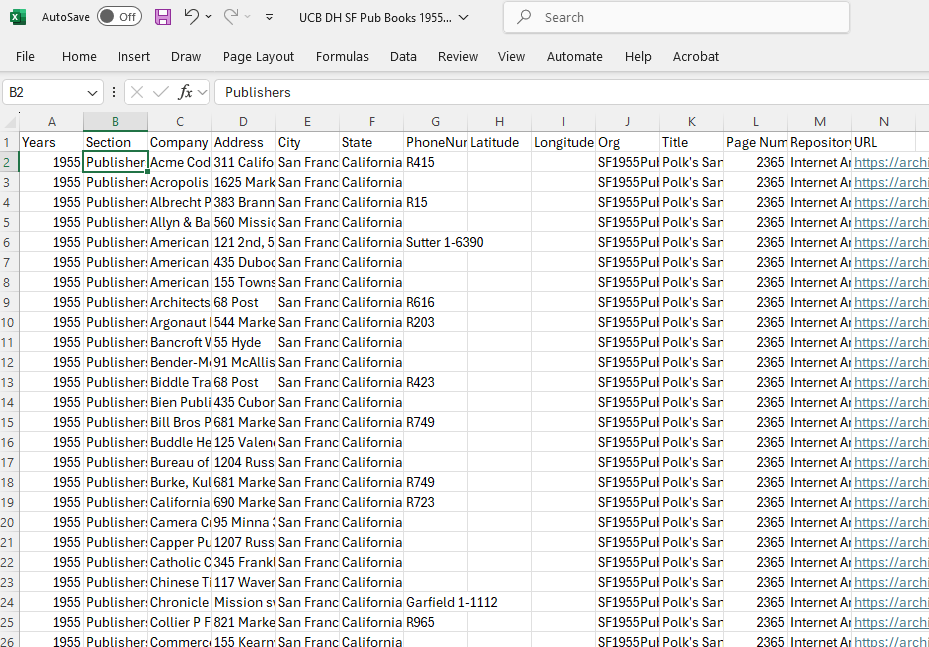
The column headers here are: Years; Section; Company; Address; City; State; PhoneNumber; Latitude; Longitude; Org; Title; PageNumber; Repository; URL. Click on the chart to see the file.
Finally, I saved my data with a filename that I could easily use to find the data again. In this case, I named it “BayAreaPublishers1955.” I made sure to save the data as an Excel file (i.e., .xmlx) and Comma Separated Value file (i.e., .csv) for use and preservation respectively. I also uploaded the file into Google Drive as a Google Sheet so you could look at it.
Initial Mapping of the Data
With that clean dataset, I headed over to Google’s My Maps (mymaps.google.com) to see if my dataset looked good and didn’t show locations in Los Angeles or other spaces. I chose Google Maps for my test because it is one of the easiest GIS programs to use
because many people are already used to the Google interface
the program will look up latitude and longitude based on address
it’s one of the most restrictive, meaning users don’t get overwhelmed with options.
Heading to the My Maps program, I created a “new” map by clicking the “Create a new map” icon in the upper, left hand corner of the interface.
From there, I uploaded my CSV file as a layer. Take a look at the resulting map:
Click on the map for an interactive version. Note that I’ve set the pins to differ in column by “type.”
The visualization highlights the centrality of the 1955 San Francisco publishing world, with its concentration of publishing companies and bookstores around Mission Street. Buying books also necessitated going downtown, but once there, there was a world of information at one’s fingertips.
Add in information gleaned from scholarship and other sources about book imports, custom houses, and post offices, and one can start to think about international book trades and how San Francisco was hooked into it.
I’ll talk more about how to use Google’s My Maps in the next post in two weeks!
This is the first of a multi-part series exploring the idea and use of data in the Arts & Humanities. For more information, check out the UC Berkeley Library’s Data and Digital Scholarship page.
Arts & Humanities researchers work with data constantly. But, what is it?
Part of the trick in talking about “data” in regards to the humanities is that we are already working with it. The books and letters (including the one below) one reads are data, as are the pictures we look at and the videos we watch. In short, arts and humanities researchers are already analyzing data for the essays, articles, and books that they write. Furthermore, the resulting scholarship is data.
For example, the letter below from Bancroft Library’s 1906 San Francisco Earthquake and Fire Digital Collection on Calisphere is data.
George Cooper Pardee, “Aid for San Francisco: Letter from the Mayor in Oregon,”
April 24, 1906, UC Berkeley, Bancroft Library on Calisphere.
One ends up with the question “what isn’t data?”
The broad nature of what “data” is means that instead of asking if something is data, it can be more useful to think about what kind of data one is working with. After all, scholars work with geographic information; metadata (e.g., data about data); publishing statistics; and photographs differently.
Another helpful question is to consider how structured it is. In particular, you should pay attention to whether the data is:
unstructured
semi-structured
structured
The level of structure informs us how to treat the data before we analyze it. If, for example, you have hundreds of of images, you want to work with, it’s likely you’ll have to do significant amount of work before you can analyze your data because most photographs are unstructured.
For example, with this picture of a ceramic hedgehog, the adorable animal, the photograph, and the metadata for the photograph are all different kinds of data. Image: Zde, Ceramic Rhyton in the Form of a Hedgehog, 14. to 13. century BCE, Photograph, March 15, 2014, Wikimedia Commons. | Creative CommonsAttribution-Share Alike 3.0 Unported.
In contrast, the letter toward the top of this post is semi-structured. It is laid out in a typical, physical letter style with information about who, where, when, and what was involved. Each piece of information, in turn, is placed in standardized locations for easy consumption and analysis. Still, to work with the letter and its fellows online, one would likely want to create a structured counterpart.
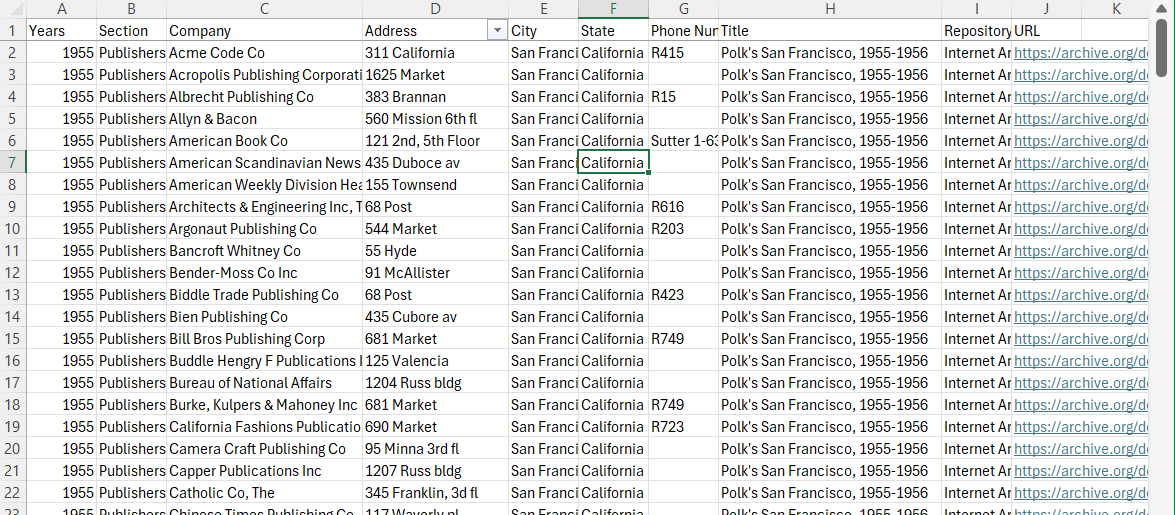
Finally, structured data is usually highly organized and, when online, often in machine-readable chart form. Here, for example, are two pages from the Polk San Francisco City Directory from 1955-1956 with a screenshot of the machine-readable chart from a CSV (comma separated value) file below it. This data is clearly structured in both forms. One could argue that they must be as the entire point of a directory is for easy of information access and reading. The latter, however, is the one that we can use in different programs on our computers.
R.L. Polk & Co, Polk’s San Francisco City Directory, vol. 1955–1956 (San Francisco, Calif. : R.L. Polk & Co., 1955), Internet Archive. | Public Domain.
This post has provided a quick look at what data is for the Arts&Humanities.
The next will be looking at what we can do with machine-readable, structured data sets like the publisher’s information. Stay tuned! The post should be up in two weeks.
UC Berkeley has been loving its data for a long time, and has been part of the international movement which is Love Data Week (LDW) since at least 2016, even during the pandemic! This year is no exception—the UC Berkeley Libraries and our campus partners are offering some fantastic workshops (four of which are led by our very own librarians) as part of the University of California-wide observance.
Love Data Week 2023 is happening next month, February 13-17 (it’s always during the week of Valentine’s Day)!
UC Berkeley Love Data Week offerings for 2023 include:
All members of the UC community are welcome—we hope you will join us! Registration links for our offerings are above, and the full UC-wide calendar is here. If you are interested in learning more about what the library is doing with data, check out our new Data + Digital Scholarship Services page. And, feel free to email us at librarydataservices@berkeley.edu. Looking forward to data bonding next month!