Tag: data management
Library Carpentry Sprint May 10th and 11th
![]()
The UC Berkeley Library is hosting the 2018 Library Carpentry Sprint on May 10th and 11th. This sprint it a part of the larger 2018 Mozilla Global Sprint, and will take place in the Berkeley Institute for Data Science (BIDS), 190 Doe Library from 2-5pm on Thursday, May 10th and from 1-5pm on Friday, May 11th. All are welcome and no experience with Library Carpentry or participating in a sprint is required. Come help us update the existing Library Carpentry curriculum or just come to see what Library Carpentry is all about. If you wish to sign up in advance, simply add you name to the Library Carpentry sprint etherpad under the UC Berkeley section. More information about Library Carpentry can be found here.
What
Library Carpentry Sprint is an international campaign that is a part of the larger Mozilla Global Sprint 2018. The goal of this Library Carpentry sprint is to improve/extend Library Carpentry lessons. Participants can contribute code or content, proofread writing, help with visual design and graphic art, do QA (quality assurance) on prototype tools, or advise or comment on project ideas or plans. All skill levels are welcome!
When
You can drop by anytime on May 10th from 2-5pm or May 11th from 1-5pm
Where
Berkeley Institute for Data Science (BIDS), 190 Doe Memorial Library
Questions
Contact Scott Peterson, speterso@berkeley.edu
UC Berkeley celebrates Love Data Week with great talks and tips!
Kicking off #lovedata18 week @UCBerkeley wih a workshop about @Scopus API! @UCBIDS @UCBerkeleyLib pic.twitter.com/qnXbQp7a9j
— Yasmina Anwar (@yasmina_anwar) February 13, 2018
Last week, the University Library, the Berkeley Institute for Data Science (BIDS), the Research Data Management program were delighted to host Love Data Week (LDW) 2018 at UC Berkeley. Love Data Week is a nationwide campaign designed to raise awareness about data visualization, management, sharing, and preservation. The theme of this year’s campaign was data stories to discuss how data is being used in meaningful ways to shape the world around us.
At UC Berkeley, we hosted a series of events designed to help researchers, data specialists, and librarians to better address and plan for research data needs. The events covered issues related to collecting, managing, publishing, and visualizing data. The audiences gained hands-on experience with using APIs, learned about resources that the campus provides for managing and publishing research data, and engaged in discussions around researchers’ data needs at different stages of their research process.

Participants from many campus groups (e.g., LBNL, CSS-IT) were eager to continue the stimulating conversation around data management. Check out the full program and information about the presented topics.
Photographs by Yasmin AlNoamany for the University Library and BIDS.

LDW at UC Berkeley was kicked off by a walkthrough and demos about Scopus APIs (Application Programming Interface), was led by Eric Livingston of the publishing company, Elsevier. Elsevier provides a set of APIs that allow users to access the content of journals and books published by Elsevier.
In the first part of the session, Eric provided a quick introduction to APIs and an overview about Elsevier APIs. He illustrated the purposes of different APIs that Elsevier provides such as DirectScience APIs, SciVal API, Engineering Village API, Embase APIs, and Scopus APIs. As mentioned by Eric, anyone can get free access to Elsevier APIs, and the content published by Elsevier under Open Access licenses is fully available. Eric explained that Scopus APIs allow users to access curated abstracts and citation data from all scholarly journals indexed by Scopus, Elsevier’s abstract and citation database. He detailed multiple popular Scopus APIs such as Search API, Abstract Retrieval API, Citation Count API, Citation Overview API, and Serial Title API. Eric also overviewed the amount of data that Scopus database holds.

In the second half of the workshop, Eric explained how Scopus APIs work, how to get a key to Scopus APIs, and showed different authentication methods. He walked the group through live queries, showed them how to extract data from API and how to debug queries using the advanced search. He talked about the limitations of the APIs and provided tips and tricks for working with Scopus APIs.

Eric left the attendances with actionable and workable code and scripts to pull and retrieve data from Scopus APIs.

On the second day, we hosted a Data Stories and Visualization Panel, featuring Claudia von Vacano (D-Lab), Garret S. Christensen (BIDS and BITSS), Orianna DeMasi (Computer Science and BIDS), and Rita Lucarelli (Department of Near Eastern Studies). The talks and discussions centered upon how data is being used in creative and compelling ways to tell stories, in addition to rewards and challenges of supporting groundbreaking research when the underlying research data is restricted.

Claudia von Vacano, the Director of D-Lab, discussed the Online Hate Index (OHI), a joint initiative of the Anti-Defamation League’s (ADL) Center for Technology and Society that uses crowd-sourcing and machine learning to develop scalable detection of the growing amount of hate speech within social media. In its recently-completed initial phase, the project focused on training a model based on an unbiased dataset collected from Reddit. Claudia explained the process, from identifying the problem, defining hate speech, and establishing rules for human coding, through building, training, and deploying the machine learning model. Going forward, the project team plans to improve the accuracy of the model and extend it to include other social media platforms.

Next, Garret S. Christensen, BIDS and BITSS fellow, talked about his experience with research data. He started by providing a background about his research, then discussed the challenges he faced in collecting his research data. The main research questions that Garret investigated are: How are people responding to military deaths? Do large numbers of, or high-profile, deaths affect people’s decision to enlist in the military?
Garret discussed the challenges of obtaining and working with the Department of Defense data obtained through a Freedom of Information Act request for the purpose of researching war deaths and military recruitment. Despite all the challenges that Garret faced and the time he spent on getting the data, he succeeded in putting the data together into a public repository. Now the information on deaths in the US Military from January 1, 1990 to November 11, 2010 that was obtained through Freedom of Information Act request is available on dataverse. At the end, Garret showed that how deaths and recruits have a negative relationship.

Orianna DeMasi, a graduate student of Computer Science and BIDS Fellow, shared her story of working with human subjects data. The focus of Orianna’s research is on building tools to improve mental healthcare. Orianna framed her story about collecting and working with human subject data as a fairy tale story. She indicated that working with human data makes security and privacy essential. She has learned that it’s easy to get blocked “waiting for data” rather than advancing the project in parallel to collecting or accessing data. At the end, Orianna advised the attendees that “we need to keep our eyes on the big problems and data is only the start.”

Rita Lucarelli, Department of Near Eastern Studies discussed the Book of the Dead in 3D project, which shows how photogrammetry can help visualization and study of different sets of data within their own physical context. According to Rita, the “Book of the Dead in 3D” project aims in particular to create a database of “annotated” models of the ancient Egyptian coffins of the Hearst Museum, which is radically changing the scholarly approach and study of these inscribed objects, at the same time posing a challenge in relation to data sharing and the publication of the artifacts. Rita indicated that metadata is growing and digital data and digitization are challenging.
It was fascinating to hear about Egyptology and how to visualize 3D ancient objects!

We closed out LDW 2018 at UC Berkeley with a session about Research Data Management Planning and Publishing. In the session, Daniella Lowenberg (University of California Curation Center) started by discussing the reasons to manage, publish, and share research data on both practical and theoretical levels.

Daniella shared practical tips about why, where, and how to manage research data and prepare it for publishing. She discussed relevant data repositories that UC Berkeley and other entities offer. Daniela also illustrated how to make data reusable, and highlighted the importance of citing research data and how this maximizes the benefit of research.

At the end, Daniella presented a live demo on using Dash for publishing research data and encouraged UC Berkeley workshop participants to contact her with any question about data publishing. In a lively debate, researchers shared their experiences with Daniella about working with managing research data and highlighted what has worked and what has proved difficult.
We have received overwhelmingly positive feedback from the attendees. Attendees also expressed their interest in having similar workshops to understand the broader perspectives and skills needed to help researchers manage their data.
I would like to thank BIDS and the University Library for sponsoring the events.
—
Yasmin AlNoamany
Love Data Week 2018 at UC Berkeley
 The University Library, Research IT, and Berkeley Institute for Data Science will host a series of events on February 12th-16th during the Love Data Week 2018. Love Data Week a nationwide campaign designed to raise awareness about data visualization, management, sharing, and preservation.
The University Library, Research IT, and Berkeley Institute for Data Science will host a series of events on February 12th-16th during the Love Data Week 2018. Love Data Week a nationwide campaign designed to raise awareness about data visualization, management, sharing, and preservation.
Please join us to learn about multiple data services that the campus provides and discover options for managing and publishing your data. Graduate students, researchers, librarians and data specialists are invited to attend these events to gain hands-on experience, learn about resources, and engage in discussion around researchers’ data needs at different stages in their research process.
To register for these events and find out more, please visit: http://guides.lib.berkeley.edu/ldw2018guide
Schedule:
Intro to Scopus APIs – Learn about working with APIs and how to use the Scopus APIs for text mining.
01:00 – 03:00 p.m., Tuesday, February 13, Doe Library, Room 190 (BIDS)
Refreshments will be provided.
Data stories and Visualization Panel – Learn how data is being used in creative and compelling ways to tell stories. Researchers across disciplines will talk about their successes and failures in dealing with data.
1:00 – 02:45 p.m., Wednesday, February 14, Doe Library, Room 190 (BIDS)
Refreshments will be provided.
Planning for & Publishing your Research Data – Learn why and how to manage and publish your research data as well as how to prepare a data management plan for your research project.
02:00 – 03:00 p.m., Thursday, February 15, Doe Library, Room 190 (BIDS)
Hope to see you there!
–Yasmin
Great talks and tips in Love Your Data Week 2017
Opening out #LYD17 w/great discussion of #securing research data. Thanks to our experts speakers @UCBIDS @DH @DLabAtBerkeley @ucberkeleylib pic.twitter.com/DqvIKb9sDL
— Yasmina Anwar (@yasmina_anwar) February 14, 2017
This week, the University Library and the Research Data Management program were delighted to participate in the Love Your Data (LYD) Week campaign by hosting a series of workshops designed to help researchers, data specialists, and librarians to better address and plan for research data needs. The workshops covered issues related to managing, securing, publishing, and licensing data. Participants from many campus groups (e.g., LBNL, CSS-IT) were eager to continue the stimulating conversation around data management. Check out the full program and information about the presented topics.
Photographs by Yasmin AlNoamany for the University Library.

The first day of LYD week at UC Berkeley was kicked off by a discussion panel about Securing Research Data, featuring
Jon Stiles (D-Lab, Federal Statistical RDC), Jesse Rothstein (Public Policy and Economics, IRLE), Carl Mason (Demography). The discussion centered upon the rewards and challenges of supporting groundbreaking research when the underlying research data is sensitive or restricted. In a lively debate, various social science researchers detailed their experiences working with sensitive research data and highlighted what has worked and what has proved difficult.

At the end, Chris Hoffman, the Program Director of the Research Data Management program, described a campus-wide project about Securing Research Data. Hoffman said the goals of the project are to improve guidance for researchers, benchmark other institutions’ services, and assess the demand and make recommendations to campus. Hoffman asked the attendees for their input about the services that the campus provides.


On the second day, we hosted a workshop about the best practices for using Box and bDrive to manage documents, files and other digital assets by Rick Jaffe (Research IT) and Anna Sackmann (UC Berkeley Library). The workshop covered multiple issues about using Box and bDrive such as the key characteristics, and personal and collaborative use features and tools (including control permissions, special purpose accounts, pushing and retrieving files, and more). The workshop also covered the difference between the commercial and campus (enterprise) versions of Box and Drive. Check out the RDM Tools and Tips: Box and Drive presentation.

We closed out LYD Week 2017 at UC Berkeley with a workshop about Research Data Publishing and Licensing 101. In the workshop, Anna Sackmann and Rachael Samberg (UC Berkeley’s Scholarly Communication Officer) shared practical tips about why, where, and how to publish and license your research data. (You can also read Samberg & Sackmann’s related blog post about research data publishing and licensing.)

In the first part of the workshop, Anna Sackmann talked about reasons to publish and share research data on both practical and theoretical levels. She discussed relevant data repositories that UC Berkeley and other entities offer, and provided criteria for selecting a repository. Check out Anna Sackmann’s presentation about Data Publishing.


During the second part of the presentation, Rachael Samberg illustrated the importance of licensing data for reuse and how the agreements researchers enter into and copyright affects licensing rights and choices. She also distinguished between data attribution and licensing. Samberg mentioned that data licensing helps resolve ambiguity about permissions to use data sets and incentivizes others to reuse and cite data. At the end, Samberg explained how people can license their data and advised UC Berkeley workshop participants to contact her with any questions about data licensing.

Check out the slides from Rachael Samberg’s presentation about data licensing below.
The workshops received positive feedback from the attendees. Attendees also expressed their interest in having similar workshops to understand the broader perspectives and skills needed to help researchers manage their data.
—
Yasmin AlNoamany
Special thanks to Rachael Samberg for editing this post.
Love Your Data Week 2017
 Love Your Data (LYD) Week is a nationwide campaign designed to raise awareness about research data management, sharing, and preservation. In UC Berkeley, the University Library and the Research Data Management program will host a set of events that will be held from February 13th-17th to encourage and teach researchers how to manage, secure, publish, and license their data. Presenters will describe groundbreaking research on sensitive or restricted data and explore services needed to unlock the research potential of restricted data.
Love Your Data (LYD) Week is a nationwide campaign designed to raise awareness about research data management, sharing, and preservation. In UC Berkeley, the University Library and the Research Data Management program will host a set of events that will be held from February 13th-17th to encourage and teach researchers how to manage, secure, publish, and license their data. Presenters will describe groundbreaking research on sensitive or restricted data and explore services needed to unlock the research potential of restricted data.
Graduate students, researchers, librarians and data specialists are invited to attend these events and learn multiple data services that the campus provides.
Schedule
To register for these events and find out more, please visit our LYD Week 2017 guide:
- Securing Research Data – Explore services needed to unlock the research potential of restricted data.
11:00 am-12:00 pm, Tuesday, February 14, Doe Library, Room 190 (BIDS)
For more background on the Securing Research Data project, please see this RIT News article. - RDM Tools & Tips: Box and Drive – Learn the best practices for using Box and bDrive to manage documents, files, and other digital assets.
10:30 am-11:45 am, Wednesday, February 15, Doe Library, Room 190 (BIDS)
Refreshments are provided by the UC Berkeley Library. - Research Data Publishing and Licensing – This workshop covers why and how to publish and license your research data.
11:00 am-12:00 pm, Thursday, February 16, Doe Library, Room 190 (BIDS)
The presenters will share practical tips, resources, and stories to help researchers at different stages in their research process.
Sponsored and organized by the UC Berkeley Library and the Research Data Management. Contact yasmin@berkeley.edu or quinnd@berkeley.edu with questions.
—–
Yasmin AlNoamany
Could I re-research my first research?
Last week, one of my teammates, at Old Dominion University, contacted me and asked if she could apply some of the techniques I adopted in the first paper I published during my Ph.D. She asked about the data and any scripts I had used to pre-process the data and implement the analysis. I directed her to where the data was saved along with a detailed explanation of the structure of the directories. It took me awhile to remember where I had saved the data and the scripts I had written for the analysis. At the time, I did not know about data management and the best practices to document my research.
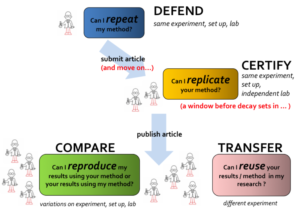
I shared the scripts I generated for pre-processing the data with my colleague, but the information I gave her did not cover all the details regarding my workflow. There were many steps I had done manually for producing the input and the output to and from the pre-processing scripts. Luckily I had generated a separate document that had the steps of the experiments I conducted to generate the graphs and tables in the paper. The document contained details of the research process in the paper along with a clear explanation for the input and the output of each step. When we submit a scientific paper, we get reviews back after a couple of months. That was why I documented everything I had done, so that I could easily regenerate any aspect of my paper if I needed to make any future updates.
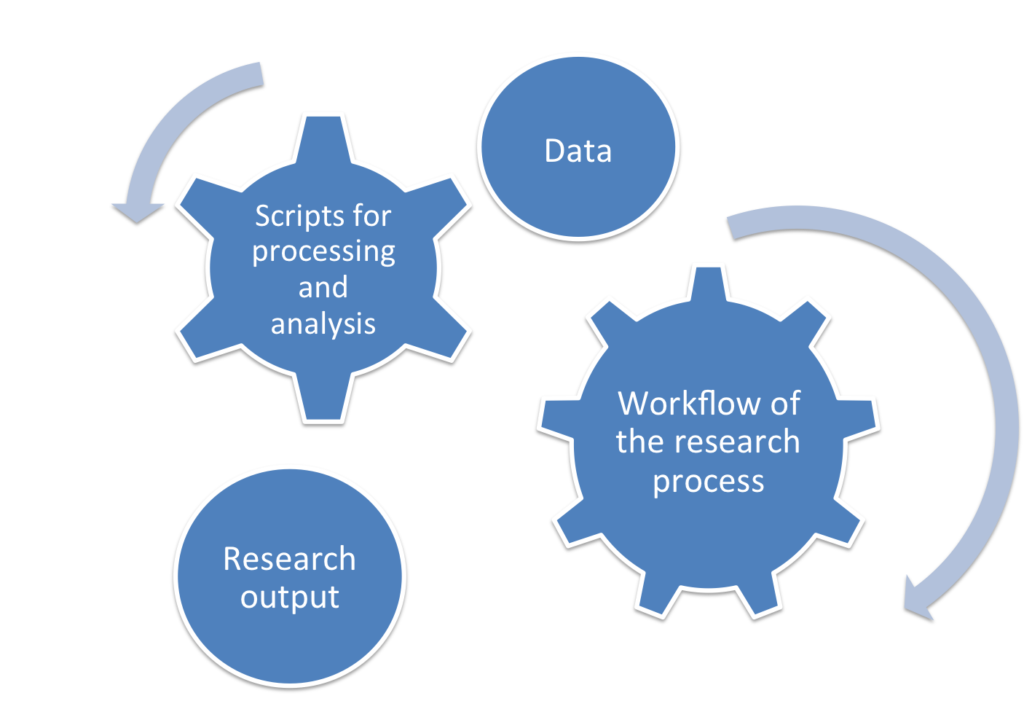
Documenting the workflow and the data of my research paper during the active phase of the research saved me the trouble of trying to remember all the steps I had taken if I needed to make future updates to my research paper. Now my colleague has all the entities of my first research paper: the dataset, the output paper of my research, the scripts that generated this output, and the workflow of the research process (i.e., the steps that were required to produce this output). She can now repeat the pre-processing for the data using my code in a few minutes.
 Funding agencies have data management planning and data sharing mandates. Although this is important to scientific endeavors and research transparency, following good practices in managing research data and documenting the workflow of the research process is just as important. Reproducing the research is not only about storing data. It is also about the best practices to organize this data and document the experimental steps so that the data can be easily re-used and the research can be reproduced. Documenting the directory structure of the data in a file and attaching this file to the experiment directory would have saved me a lot of time. Furthermore, having a clear guidance for the workflow and documentation on how the code was built and run is an important step to making the research reproducible.
Funding agencies have data management planning and data sharing mandates. Although this is important to scientific endeavors and research transparency, following good practices in managing research data and documenting the workflow of the research process is just as important. Reproducing the research is not only about storing data. It is also about the best practices to organize this data and document the experimental steps so that the data can be easily re-used and the research can be reproduced. Documenting the directory structure of the data in a file and attaching this file to the experiment directory would have saved me a lot of time. Furthermore, having a clear guidance for the workflow and documentation on how the code was built and run is an important step to making the research reproducible.

While I was working on my paper, I adopted multiple well known techniques and algorithms for pre-processing the data. Unfortunately, I could not find any source codes that implemented them so I had to write new scripts for old techniques and algorithms. To advance the scientific research, researchers should be able to efficiently build upon past research and it should not be difficult for them to apply the basic tenets of scientific methods. My teammate is not supposed to re-implement the algorithms and the techniques I adopted in my research paper. It is time to change the culture of scientific computing to sustain and ensure the integrity of reproducibility.
Berkeley Services for Digital Scholarship

 Every time you download a spreadsheet, use a piece of someone else’s code, share a video, or take photos for a project, you’re working with data. When you are producing, accessing, or sharing data in order to answer a research question, you’re working with research data, and Berkeley has a service that can help you.
Every time you download a spreadsheet, use a piece of someone else’s code, share a video, or take photos for a project, you’re working with data. When you are producing, accessing, or sharing data in order to answer a research question, you’re working with research data, and Berkeley has a service that can help you.
Research Data Management at Berkeley is a service that supports researchers in every discipline as they find, generate, store, share, and archive their data. The program addresses current and emerging data management issues, compliance with policy requirements imposed by funders and by the University, and reduction of risk associated with the challenges of data stewardship.
In September 2015, the program launched the RDM Consulting Service, staffed by dedicated consultants with expertise in key aspects of managing research data. The RDM Consulting Service coordinates closely with consulting services in Research IT, the Library, and other researcher-facing support organizations on the campus. Contact a consultant at researchdata@berkeley.edu.
The RDM program also developed an online resource guide. The Guide documents existing services, providing context and use cases from a research perspective. In the rapidly changing landscape of federal funding requirements, archiving tools, electronic lab notebooks, and data repositories, the Guide offers information that directly addresses the needs of researchers at Berkeley. The RDM Guide is available at researchdata.berkeley.edu.
Jamie Wittenberg
Research Data Management Service Design Analyst
Contact me at wittenberg[@]berkeley.edu