Brianna Iswono is a third-year undergraduate student at UC Berkeley majoring in chemical engineering. Throughout the Fall 2024 semester, Brianna worked with Roger Eardley-Pryor of the Oral History Center to earn academic credits through Berkeley’s Undergraduate Research Apprentice Program (URAP). URAP provides opportunities for undergraduates to work closely with Berkeley scholars on cutting edge research projects for which Berkeley is world-renowned. In this post, Brianna reflects on her research about nuclear power as it appeared in the Oral History Center archives.
As a chemical engineering student at UC Berkeley, my coursework only briefly touches on topics of nuclear power and energy. I wanted to learn more and my curiosity deepened as I saw more and more headlines about nuclear energy in news articles and social media. To dive deeper, in the fall of 2024 I joined Berkeley’s URAP (Undergraduate Research Apprenticeship Program) under the mentorship of historian Roger Eardley-Pryor at the Oral History Center, where I analyzed various oral histories and technical reports about nuclear energy. Through this experience, what I discovered was not only a stronger interest in nuclear power, but a field marked by polarizing perspectives and profound complexity—one where simple answers do not exist.
William E. Siri, environmentalist and biophysicist, 1964
Nuclear power stands as one of the most reliable carbon-free energy sources available today. Unlike fossil fuels, it produces no carbon dioxide during electricity generation, which makes nuclear power a critical tool in the fight against climate change and reducing greenhouse gas emissions. Given the growing urgency for energy facilities to reduce their overall emissions, nuclear power offers a viable option for large-scale, reliable energy production. As former Sierra Club president, mountaineer, biophysicist, and Berkeley Lab energy analyst William E. Siri noted in his oral history in the late 1970s, “Coal is a very dirty fuel… That leaves nuclear as one clean energy source until solar and other energy sources are fully developed.” Today, solar and wind are more developed, but the energy they generate drops when the sun sets or when winds cease. By providing steady, continuous power, nuclear energy complements intermittent renewable sources like wind and solar, ensuring grid stability. This reliability reduces the need for fossil fuel-based backup systems and thus helps mitigate climate change.
David Brower, environmental activist and first executive director of the Sierra Club (undated).
However, nuclear power is not without its environmental challenges. The construction and operation of plants can disrupt local ecosystems, particularly since they are often built in rural areas rich in biodiversity and ecological value. Habitat disruption, deforestation, and the high demand for water used in reactor cooling all remain significant concerns. The presence of nuclear plants places an increased strain on local water resources, particularly in underserved regions already facing water scarcity. In the first of his two archived oral history interviews, David Brower, the former executive director of the Sierra Club, the nation’s largest environmental organization, explained about the Club’s consideration of nuclear power, “You certainly haven’t helped the poor by degrading the environment, the working place, by not getting into the battles to protect them from the chemicals that they’re exposed to.”
Laurence I. Moss, nuclear engineer and former Sierra Club president, 1973.
Also, the visual impact of large nuclear facilities can dramatically alter the character of scenic areas. At least in California, public opposition was fueled historically by concern that industrial structures for nuclear power detracts from the natural beauty and environment of rural areas, making them appear stark and out of place. Laurence I. Moss, former Sierra Club president and nuclear engineer, worked directly on construction of nuclear reactors. Moss shared in his oral history, “In my mind it was always a location issue. That was not the right place to put a nuclear power plant, or any industrial facility. I would not want to put a residential development there, anything that would alter the natural environment for the worse.” Moss’s perspective highlights the tension between technological advancement and environmental preservation, underscoring the importance of careful site selection to balance progress with respect for natural landscapes.
Professor Thomas H. Pigford, founding chair of UC Berkeley’s Department of Nuclear Engineering, 2001.
Another major challenge, and perhaps the most pressing, is the management of nuclear waste. Nuclear reactors generate long-lived radioactive waste that requires secure, long-term storage, and even the most advanced waste repositories carry the risk of leakage or contamination over the thousands of years that spent nuclear fuel remains toxic. Efforts to manage nuclear waste have included ambitious ideas such as deep-sea disposal or even launching the waste into the sun. However, these approaches fail to fully eliminate the risk of leakage, especially given the exceptionally long timescales over which the waste must remain secure, and they often introduce additional challenges. As Thomas H. Pigford, the founding chair of UC Berkeley’s Department of Nuclear Engineering, explained in his oral history from the late 1990s,“Another more attractive approach is to shoot the radioactive waste into the sun, which would require concentrating it to reduce the weight. And that’s where it belongs, because the sun is so radioactive. But there, the technical challenge or problem is the abort rate of missiles, of space vessels, and so when consulting the people in NASA, we concluded that that was just untenable.” Such unresolved issues remain a central concern for environmental advocates, highlighting the ongoing tension between the potential of nuclear power as a clean energy source and the ecological risks it poses.
Economically, nuclear power presents both opportunities and challenges. Once operational, nuclear reactors have relatively low fuel and operating costs compared to many other energy sources. Uranium, the main fuel used, is highly energy-dense, requiring only small amounts to generate large quantities of energy. This efficiency makes nuclear power a cost-effective solution to meet large-scale energy demands, providing a reliable supply of energy at a lower long-term cost while still delivering the high output needed to sustain industrial and societal needs. After working directly with the economic analysis of nuclear plant construction in the 1960s, Moss shared, “we were able to show that other alternatives, specifically a nuclear power alternative, built in those years could provide power at lower cost than the dams.” Nuclear power also has an extensive reach that goes far beyond reactors, influencing a wide range of industries and technologies. The advancements and expertise gained through working with radiation and the advanced technologies required for waste facilities have helped with the development of new medical technologies used to measure radiation. Professor Pigford was directly involved in establishing the nuclear engineering curriculum at Berkeley and saw its expansion into related medical technologies. In his oral history, Pigford shared “Yes, well, there are plenty of jobs in waste disposal. And they are emphasizing more and more the interaction with the bioengineering program, which, as you probably know, is a new push on the campus. There’s a new department, and they’ve even gone into the field of tomography, which is doing scans on the brain and on the rest of the body. These involve nuclear reactions and so the development of instrumentation for that, techniques of sensing the nuclear radiations and interpreting them, is occupying more and more time.” Pigford’s insight highlights how nuclear engineering graduates have the opportunity to apply their expertise to innovations in health-related technologies, such as medical imaging.
Environmental activist in Seoul, Korea, at a rally marking the 12th anniversary in 2023 of Japan’s Fukushima nuclear disaster (photograph by Ahn Young-joon of Associated Press).
Yet, a major economic challenge of nuclear power is the huge initial investment needed to build a plant. Designing, constructing, and meeting regulatory standards for a single nuclear plant can cost billions of dollars. While the long-term operating costs are lower, the upfront costs to begin production are much higher than those of other energy sources.This creates a significant barrier, particularly for developing countries that may also lack the technical expertise or regulatory infrastructure needed to operate plants safely. In his oral history, Siri captured the economic trade-off and complexity of nuclear power. Siri noted, “The more countries that have nuclear power plants, particularly the less advanced countries, the more likelihood there will be of meltdowns, simply because many such countries don’t have the technical base on which to maintain such an industry.” For these countries, nuclear power offers a chance to advance economically, but it also comes with the greater risk of catastrophic failure.
Roy Woodall, Australian geologist (undated).
On the global stage, nuclear technology carries a sense of prestige. Non-nuclear nations often see other nations with advanced nuclear developments as leaders in innovation, which enhances their national pride and elevates their international status. The high demand for uranium to fuel nuclear reactors has led various countries to form alliances or joint ventures, employing any means necessary to secure a share of the advancements in nuclear technology. Roy Woodall, an Australian geologist known for his contributions to the mining and exploration industries, directly engaged with the mining sector to meet the growing global demand for uranium. In his oral history from the early 2000s, Woodall shared, “There was quite a lot of interest from other overseas companies in looking for uranium in Australia, so we formed a joint venture to look for conglomerate-type uranium deposits in Northern Western Australia.” His experience highlights the global scramble for uranium resources, reflecting how the race for nuclear technology has spurred both national and international collaboration.
Michael R. Peevey, an energy entrepreneur and regulator (undated).
However, the social risks associated with nuclear power are significant. Public fear of radiation exposure, which can lead to various health risks, has been intensified by past large-scale nuclear accidents like Fukushima and Three Mile Island, along with the media frenzy surrounding them. When reflecting on nuclear concerns during his oral history in 2019, Michael R. Peevey, a UC Berkeley alumnus, former electric utility executive, and previous president of the California Public Utilities Commission, recalled “But we had Chernobyl in Russia, which was a disaster; it’s a lingering disaster today.” Such concern has resulted in widespread resistance to the construction of new nuclear reactors and calls to shutdown existing ones. Grassroots movements and anti-nuclear campaigns have further fueled this opposition, creating a broad social aversion to nuclear power.
David Pesonen, attorney and environmentalist, 1963.
David E. Pesonen is a UC Berkeley alumnus, attorney, and environmental activist best known for his leadership role in the battle to defeat a PG&E nuclear power plant at Bodega Bay in the early 1960s. In his oral history recorded in the late 1990s, Pesonen explained his motivation for spreading the anti-nuclear power agenda. “Mainly because of the waste disposal problem. I don’t know the answer to that. I don’t know that anybody does. And also because I think the design of the generation of plants that we are involved with is inherently unsafe.” Despite the advanced safety features of modern plants, the widespread fear and skepticism continue to challenge the nuclear industry, highlighting the complex intersection of technological progress, environmental concerns, and public perception.
After conducting this oral history research and diving into the different aspects of nuclear power, I have come to realize that this field is inherently complex. I am still unsure where I stand in these debates, but one thing is clear: nuclear energy shouldn’t be dismissed outright. A recent LA Times article notes that, as energy-demanding technologies like AI continue developing rapidly, the demand for energy will only increase and all carbon-free options must be considered, especially in light of climate change. At the same time, we cannot ignore the risks that nuclear power poses. I think that the best approach is to carefully consider all non-fossil energy sources, such as nuclear or renewable, to make informed choices. Nuclear power is neither entirely good nor entirely bad; it is a complex and multifaceted technology with the potential for significant benefits and serious risks. Attitudes will likely continue to shift back and forth, but embracing the complexities of nuclear power is important to making wise decisions about its future role in meeting global energy needs. Reflecting on my semester of oral history research, I am grateful to have taken this URAP opportunity, as it gave me valuable insight and a new understanding of nuclear power that I always hoped to explore. Nuclear power is a complicated yet astonishing field, and I hope others can be informed on it to formulate their own stance on how to create a greener future.
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. As a soft-money research unit of The Bancroft Library, the Oral History Center must raise outside funding to cover its operational costs for conducting, processing, and preserving its oral history work, including the salaries of its interviewers and staff, which are not covered by the university. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
“TOPAZ” by Emily Ehlen, a graphic illustration based on oral histories recorded in the Oral History Center’s Japanese American Intergenerational Narratives project
In April 2024, Oral History Center (OHC) interviewers Amanda Tewes, Shanna Farrell, and Roger Eardley-Pryor traveled to Salt Lake City, Utah, where we presented our work on the Japanese American Intergenerational Narratives Project at the annual meeting of the National Council on Public History (NCPH). We also joined a pilgrimage to the central desert of Utah along with other public historians and several members of the Wakasa Memorial Committee, including survivors and descendants of the Topaz prison camp in Utah, one of the ten US government mass incarceration sites where Japanese Americans were unjustly imprisoned during World War II. Our experiences in Utah at NCPH and at Topaz reiterated how history remains a powerful and living force, and how oral history can help promote that power. Difficult questions about “belonging” appear throughout many of the oral histories in OHC’s Japanese American Intergenerational Narratives project, and those same questions punctuated much of our time in Utah this past April.
Program cover for the annual meeting of the National Council on Public History held in Salt Lake City, Utah, from April 10-13, 2024.
“Historical Urgency” was the conference theme for this year’s meeting of the National Council on Public History (NCPH) in Salt Lake City, where some 740 attendees presented, networked, and learned together. Presentation topics included community engagement, particularly with communities whose histories face urgent existential threats; communicating the critical importance of history and historical thinking; discourse and dialogue in a time of extreme social polarization; exploration of oral history, especially the collection of oral histories from older generations; and repatriation of human remains and cultural objects. As noted by NCPH president Kristine Navarro-McElhaney, conference discussions highlighted how historians’ work for public audiences remains essential to the fabric of our society, especially during this time of political and cultural polarization—and yet historical perspectives, tools, and history workers themselves have increasingly come under threat. While urgency may seem in opposition to the often slow and deliberate work that oral historians and other public historians do to build trust and lasting relationships with the communities we serve, many of us cannot help but feel a strong sense of urgency and importance in our efforts to collaboratively excavate the past and elevate community stories in ways that help make meaning in the present.
Left to right: OHC interviewers Roger Eardley-Pryor, Shanna Farrell, and Amanda Tewes, and Executive Director of the Japanese American Museum of Oregon Hanako Wakatsuki-Chong at the 2024 NCPH conference in Utah
We felt especially honored to share at this NCPH our work on the Japanese American Intergenerational Narratives Project. Our roundtable presentation recounted the project’s origins, the trauma-informed interviewing approach we used with these oral histories, and some of emergent themes from the project’s interviews, like “belonging,” “art and expression,” “healing,” and “memorialization.” The roundtable’s discussion was moderated by Hanako Wakatsuki-Chong, the Executive Director of the Japanese American Museum of Oregon and a former National Park Service Ranger who recorded her own oral history as part of the project. Nancy Ukai and Masako Takahashi, both of whom also recorded oral histories as part of the project, attended and also presented at the NCPH conference in Utah, where they heard portions their own oral history interviews during our presentation. Our presentation included audio clips from season 8 of The Berkeley Remix podcast, “From Generation to Generation”: The Legacy of Japanese American Incarceration,” as well as graphic narrative artwork by Emily Ehlen, all based on oral histories recorded for the Japanese American Intergenerational Narratives Project.
Masako Takahashi and Roger Eardley-Pryor at the Pictures of Belonging exhibit at the Utah Museum of Fine Arts
Relatedly, during the NCPH conference, I (Roger Eardley-Pryor) joined other public historians for a tour of the Utah Museum of Fine Arts on the University of Utah campus to see a new exhibit titled Pictures of Belonging: Miki Hayakawa, Hisako Hibi, and Miné Okubo. The exhibition was curated by Professor ShiPu Wang of UC Merced and features over 100 paintings and works on paper by these three Japanese American women artists, all critically acclaimed with long and productive careers. Yet during World War II, both Hibi and Okubo were unjustly incarcerated in Utah at Topaz, along with Hayakawa’s parents. Pictures of Belonging follows the three artists’ prewar, wartime, and postwar art practices, sharing an expanded view of the American experience by women who used artmaking to take up space, make their presence and existence visible, and assert their own belonging. Many of the exhibit’s artworks are on view to the public for the first time. The exhibit’s titular theme of “belonging” resonated nicely with the Oral History Center’s Japanese American Intergenerational Narratives Project at UC Berkeley, and Okubo even earned her Master in Fine Arts degree in 1938 from UC Berkeley. Our tour of the art exhibit was co-led by Sarah Palmer, Head Exhibition Designer at the Utah Museum of Fine Arts, and by Dr. Kristen Hayashi, Director of Collections Management & Access and Curator at the Japanese American National Museum in Los Angeles. I am especially grateful I could tour Pictures of Belonging with Masako Takashashi, who herself is an outstanding multi-media artist, was born behind barbed wire at the Topaz prison camp in Utah, and who I worked with to record her forthcoming oral history interview for the Japanese American Intergenerational Narratives Project.
“Dust Storm, Topaz” by Chiura Obata, reprint of 1943 watercolor as displayed at the Topaz Museum in Delta, Utah
Our visit to the Utah Museum of Fine Arts also included another new exhibit titled Chiura Obata: Layer by Layer, which presents an in-depth look at the creation and conservation of Obata’s beautiful “Horses” silk screen painting from 1932. Chiura Obata was an esteemed artist and professor at UC Berkeley who was also incarcerated during World War II at Topaz in Utah, where he and Miné Okubo taught art classes for their fellow Japanese American incarcerees. Kimi Kodani Hill, the granddaughter of Chiura Obata, recently presented at the Utah Museum of Fine Arts on her grandfather’s life and work, and I’m grateful that during our recent meeting in Berkeley, prior to my own Utah trip, she shared stories with me about Obata’s silk screen exhibit. During the screen’s 2022 conservation treatment, conservators at Nishio Conservation Studio discovered that the four-paneled screen contained hidden full-scale preparatory charcoal drawings of the horses. In addition, they found that the screen’s internal layers were made of practice drawings by Professor Obata and his summer 1932 students. The recently conserved screen, the full-scale under-drawings, and a selection of the practice drawings were all on display at the Utah Museum of Fine Arts, along with a short film on the conservation process, which itself is an artform. After we returned to the Bay Area, Kimi Kodani Hill provided a guided tour of another exhibition with forty of Chiura Obata’s watercolors, woodblock prints, and ink paintings from several decades of his life that are currently displayed through mid-July at the San Francisco Museum of Modern Art.
National Historic Landmark sign at Topaz notes that the site is privately owed by the Topaz Museum Board and asks visitors not to remove any objects, including rocks
On April 11, 2024, in Salt Lake City at the NCPH conference, Masako Takahashi and Nancy Ukai joined other members of the Wakasa Memorial Committee to present their own panel titled “Who Writes Our History?” This panel explored the life and tragic death of James Hatsuaki Wakasa, who was shot and killed while confined in Topaz eighty-one years earlier on April 11, 1943. Their panel also addressed urgent and ongoing challenges over descendant and survivor community consent and collaboration with the Topaz Museum following the recent discovery and excavation of the Wakasa Memorial Stone from the Topaz incarceration site in 2021. That massive, 1,000-pound stone memorial was erected in 1943 by Japanese American incarcerees at Topaz just after James Wakasa’s murder there. But US government authorities quickly demanded the memorial’s destruction in their effort to bury acknowledgement of Wakasa’s death from a bullet fired by a white, nineteen-year-old US soldier who was quickly acquitted of any crime. The Wakasa Memorial Committee’s NCPH presentation, which was standing-room only, featured short films and personal reflections on the life, death, memory, and now-contested stone memorial of James Wakasa.
A perimeter fence at Topaz bears the name of the WWII-era mass incarceration in barbed wire
Two days later, still in Utah, Oral History Center interviewers and several other public historians joined Ukai, Takahashi, and other members of the Wakasa Memorial Committee on a pilgrimage to the dust-strewn ruins of the Topaz site on the edge of the Great Basin in Utah’s central desert. The bus ride out to the remote site included watching historical films and sharing personal backgrounds and reflections amongst this group that had assembled from eight different states. Hours later, we arrived at a sparse, sun-bleached landscape encircled by distant snow-capped mountains. Much of the original barbed wire fence around Topaz remains today where some 8,000 Americans were unjustly imprisoned for years during World War II. Crumbled concrete foundations mark sites of now-gone guard towers where US soldiers aimed their guns down at the Japanese American prisoners, and from where they occasionally fired shots, like the one that pierced James Wakasa’s heart in 1943. At the Topaz site, we joined members of the Topaz Museum Board, including board president Patricia Wakida; Scott Bassett, board secretary and education director at the Topaz Museum; and Topaz descendant and board member Dianne Fukami. Together, we all participated in a ceremony organized by the Wakasa Memorial Committee to commemorate Wakasa’s death, as well as the 140 people who died behind barbed wire at Topaz, and the sixteen Japanese American soldiers drafted from Topaz who died during their World War II military service.
Wakasa Memorial Committee members Masako Takahashi (left), Nancy Ukai (center) and Lauren Araki at Topaz near where James Wakasa was shot 81 years earlier. Ukai and Araki drape ancestral name tags around an artist’s rendition of the Wakasa Memorial Stone.
The Wakasa 81st Memorial Ceremony at Topaz began at block 36-7-D, where James Wakasa’s tar-paper barracks once stood. From there, we re-traced Wakasa’s steps across the dusty and now-hauntingly empty landscape to the western perimeter site of his murder, near where the Wakasa Memorial Stone once stood before incarcerated Japanese Americans, under government orders to destroy the memorial, buried it in 1943. An artist’s large recreation of the stone, this one blazing white and made of paper mache and wood, stood near the former burial site of the stone memorial before its removal in 2021. After a land blessing and words of remembrance from survivors born at Topaz, we encircled the artist’s stand-in memorial with name tags bearing the names of our own ancestors. Joshua Shimizu then sang in both Japanese and English the hymn “Rock of Ages,” which was also sung at Wakasa’s funeral in April 1943, and which offered deeper meaning for the missing original Wakasa Memorial Stone.
A folded paper flower used during the ceremony that bears the name of Yasutaro Sakuyama, who died in 1944 while imprisoned at Topaz.
During the “Rock of Ages” hymn, ceremonial participants attached to the base of the art installation many colorful paper flowers that carried tags naming other Japanese Americans who died in Topaz. The paper flowers we carried to the ceremony were made by Topaz survivors and descendants in honor of the paper floral blossoms folded by imprisoned Japanese Americans at Topaz in lieu of actual flowers for James Wakasa’s 1943 funeral. Miné Okubo, the artist whose work we saw earlier at the Utah Museum of Fine Arts, drew several illustrations of Wakasa’s funeral while she was incarcerated at Topaz, including drawings of imprisoned women folding paper flowers to adorn wreaths and crosses. On the desert floor in April 2024, white paper flowers also surrounded the excavation site where the Topaz Museum Board excavated Wakasa’s Memorial Stone in 2021. The Wakasa 81st Memorial Ceremony at Topaz simultaneously evoked absence and living memory. It was especially meaningful to me (Roger) to join Nancy Ukai and Masako Takahashi at the ceremony after having worked together to record their oral histories, in which they shared intergenerational memories about James Wakasa and more recent memories about the Wakasa Memorial Stone’s recent rediscovery and removal from that site.
Public historians and Wakasa Memorial Committee members view the excavated Wakasa Memorial Stone at the Topaz Museum in Delta, Utah
After the ceremony at Topaz, the pilgrimage group boarded the bus and traveled sixteen miles to the handsome Topaz Museum, which opened in 2017 after decades of fundraising and planning in the small town of Delta, Utah. Once there, the pilgrimage group found their way to the back of the museum where we gathered to witness the actual Wakasa Memorial Stone, a one-thousand-pound rock now confined in a small enclosure. After paying our respects to the stone, we toured the Topaz Museum’s exhibits and collections, which include hundreds of artifacts, photographs, and oral histories, as well as 150 pieces of original artwork. The Topaz Museum’s core exhibit explores the complex story of the World War II Japanese American incarceration experience, especially as it transpired at Topaz. The exhibit begins with the racist laws that marginalized early Japanese immigrants, which lead eventually to the mass incarceration of Japanese Americans during World War II. The exhibit extends into the traumatic impacts of their exile, with an obvious focus on the Topaz experience, and it concludes with an examination of the Constitutional violations that the incarcerees were forced to endure. I found the Topaz Museum exhibits to be impressive, interactive, and informative. The pilgrimage group then gathered a final time out back by the Wakasa Memorial Stone before boarding the bus and returning to Salt Lake City.
OHC interviewers Amanda Tewes (in maroon cap) and Shanna Farrell (in purple hat) observe the excavation site of the Wakasa Memorial Stone near where James Wakasa was shot 81 years earlier in April 1943
The emotional experiences throughout our time in Utah reminded me of William Faulkner’s line in Requiem for a Nun: “The past is never dead. It’s not even past.” The public history presentations on “historical urgency” at NCPH, the outstanding exhibits on Japanese American artists, the powerful pilgrimage to Topaz and the commemorative ceremony at the site of James Wakasa’s murder, which we shared with survivors and descendants of the prison camp eighty-one years from the date of Wakasa’s death, as well as our trip to the Topaz Museum to see its exhibits and the excavated Wakasa Memorial Stone all reminded us that history is still very much alive and shapes our present experiences. At both the Topaz incarceration site and at the Topaz Museum in Delta, we witnessed some of the still-simmering tensions between Topaz Museum Board members and members of the Wakasa Memorial Committee over what has happened and what will happen to the now-unearthed Wakasa Memorial Stone. Throughout all of those experiences in Utah, I kept thinking on the recurrent theme of “belonging,” including in the oral histories we continue to conduct in the Oral History Center’s Japanese American Intergenerational Narratives Project. “Belonging” carries multiple meanings and invites complex questions. Within what communities, or within which factions of communities, do we find and feel belonging? Throughout history, and up through the present, where have Japanese Americans found belonging? What about the physical artifacts of Japanese American history, like artwork created during World War II-era incarceration, or like the recently re-discovered Wakasa Memorial Stone? To whom do those objects belong? And importantly, who has the right to tell the history of artifacts, artwork, memorials, or lived experiences? To whom does this history belong?
Answers to questions of belonging are elusive because they’re always evolving. I do know, however, how grateful I feel to continue working with individuals and communities to record oral histories that empower narrators to share their own living memories and reflections on the past, and how the personal histories these interviews record will continue to shape our shared present moments. These experiences in Utah helped further inspire our ongoing work on the Japanese American Intergenerational Narratives Project. We hope that you, too, can find inspiration and meaning in these stories, and that they might inform your own sense of belonging.
— Roger Eardley-Pryor, Oral History Center historian and interviewer
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of all the work we do, including each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
The OHC’s JAIN project documents and disseminates the ways in which intergenerational trauma and healing occurred after the United States government’s mass incarceration of Japanese Americans during World War II. The OHC team interviewed twenty-three Japanese American survivors and descendants of the World War II incarceration to investigate the impacts of healing and trauma, how this informs collective memory, and how these narratives change across generations. Initial interviews in the JAIN project focused on the Manzanar and Topaz prison camps in California and Utah, respectively. The JAIN project began at the OHC in 2021 with funding from the National Park Service’s Japanese American Confinement Sites Grant. The grant provided for 100 hours of new oral history interviews, as well as funding for a new season of The Berkeley Remix podcast and for Emily Ehlen’s unique artwork below, all based on the JAIN project oral histories.
We encourage you to use and share Emily Ehlen’s artwork, along with the JAIN project oral history interviews, especially in classrooms when teaching the history and legacy of the World War II incarceration of Japanese Americans. When using these images, please credit Emily Ehlen as the artist (for example, Fig. 1, Ehlen, Emily, WAVE, digital art, 2023, Oral History Center, The Bancroft Library, University of California, Berkeley), and see the OHC website for more on permissions when using our oral histories. To save a digital copy of any illustration below for fair use, right click on the image and select “Save Image As…” The text description that accompanies each illustration below aims to provide accessibility for the visually impaired in lieu of Alt-Text limitations, which does not easily accommodate graphic narrative images. In a separate blog post, you can learn more about the artist Emily Ehlen and her processes while creating these dynamic illustrations drawn from the memories and reflections of JAIN oral history narrators.
Artist’s statement
Emily Ehlen’s illustrations for the Japanese American Intergenerational Narratives Oral History Project convey compelling narratives and imagery, with impactful shapes and color, by crafting traditionally and translating images into digital pieces. She uses text and imagery to balance the composition and support storytelling elements. Her work encompasses themes of identity and belonging, intergenerational connections, and healing. The collection navigates the impact and experiences of Japanese American incarceration during World War II and its effects on future generations.
WAVE by Emily Ehlen
This image titled WAVE consists of two panels. The top panel depicts text that relates to the number of generations of Japanese descents surrounding a family portrait using barbed wires as arrows. The text is in romanized Japanese and kanji. It reads: “Issei,” meaning first generation; “Nisei,” meaning second generation; “Sansei,” meaning third generation; “Yonsei,” meaning fourth generation; and “Gosei,” meaning fifth generation. The bottom panel depicts a large wave and guard tower behind barbed wire with text above that reads, “Your generation is just one part of the wave, and you do your best to build what you can for the next generation in your family.”
MANZANAR by Emily Ehlen
This image titled MANZANAR consists of four different panels. Each panel depicts a part of an incarceration camp and features barbed wire, the American flag, and the buildings in the camp. Above the top panel there is text that reads, “There’s like a sense of yearning and wanting to know more.” In the middle right panel, a woman in a red top layered over a white T-shirt and green pants runs towards the left of the image. The bottom panel depicts the cemetery monument at Manzanar National Historic Site, with Japanese kanji written on top, which reads, “I REI TO,” or “soul consoling tower.” Below the bottom panel there is text that reads, “I feel like my journey goes ever onward.”
STORIES by Emily Ehlen
This image titled STORIES consists of four panels. The top panel depicts a growing boy talking to his mother. An incarceration camp appears behind the mother. Above this top panel, the text reads, “My mom would not speak of things in camp. Maybe she didn’t want to or couldn’t at the time. It wasn’t ’til I was older did she begin telling me stories of camp.” Under this top panel, the text reads, “I got to know more about my mom, about a part of her life when I wasn’t there.” Two middle panels follow, depicting a green puzzle piece and crying eyes behind barbed wire. The text between these panels reads, “The missing piece she kept. The sadness she concealed.” In the bottom panel, tears from the eyes above fall into a plant on the ground that is growing. The text on this panel reads, “Talking about it didn’t make the pain disappear, but letting her experiences come to light brought a place for healing.”
TEACHER by Emily Ehlen
This image titled TEACHER consists of four panels. The top left panel shows a male teacher next to a chalkboard. The text on the chalkboard reads, “In middle school, we were learning about the Holocaust, and our teacher was telling the whole class like, ‘Well, Jewish people were put in camps…'” The top right panel depicts a raised hand with text that reads, “And I was like, ‘Wait, my grandmother was put in a camp.’ So I raised my hand.” The middle panel depicts a girl sitting at a desk, a male teacher standing, and a large crack between them. On the left of the panel, the girl says, “My grandparents were put in a camp, but they were put in a camp by America.” The text in the large crack reads, “And there was this awkward silence.” The teacher responds, “Well, we didn’t kill people.” The word “kill” has a red strikethrough on it. The bottom panel depicts the girl at the desk alone in the dark. The text reads, “I remember that as the first time I felt like my experience was disparaged or put down, but I was too young to really understand that.” Text on the bottom left indicates these quotations are from Miko Charbonneau’s oral history for the Japanese American Intergenerational Narratives Oral History Project.
EUCALYPTUS by Emily Ehlen
This image titled EUCALYPTUS consists of three panels. The top panel depicts suitcases and boxes of various sizes, and includes text which reads, “When they were all packing to go, my grandfather packed up this box, very carefully, and my mother thought it was, oh, treats or tools, or something—she didn’t know. And she said when they got to camp and opened it up and it was filled with Eucalyptus Leaves.” The words “eucalyptus leaves” are larger than the other words. In the center, the grandfather stands in front of all of the panels with a box of eucalyptus leaves. He is looking down with a sad expression. The bottom panel depicts some eucalyptus leaves as well as barbed wire that mimics the red, white, and blue of an American flag. This panel includes text which reads, “She said, ‘You fool, why did you waste this precious space on this?’ He told her, ‘I thought we may never go back to Berkeley,’ and he loved the fragrance of the Eucalyptus leaves, and they reminded him of the Berkeley he loved. My mother said, ‘I wished I had directed my anger at the U.S. government and not my father, who didn’t know if he’d ever go back to this place that he loved so much.'” Text on the bottom left indicates these quotations are from Nancy Ukai’s oral history for the Japanese American Intergenerational Narratives Oral History Project.
SPLASH by Emily Ehlen
This image titled SPLASH consists of two panels on the top and two on the bottom. The top left panel depicts a younger woman and an older woman in a boat. Text above the top two panels reads, “The U.S. Government told my mother, ‘It is advisable that you move as far away from California as you can. Stay away from other Japanese. Try to become even more American than you think you are, than you already are.'” The top right panel depicts the two women holding hands and standing in the boat. The text below these panels reads,”‘Just quietly go about your business even though this horribly unconstitutional thing has just happened to you and you’ve suffered all this trauma. But try to be American. Try to fit in.'” The bottom left panel depicts a close-up of the women holding hands above the boat and a ripple in the water. Beneath the hands, the text reads, “We were told, ‘Don’t rock the boat, do not make waves.” Beneath the boat, the text reads, “Nonsense. Let’s go make a Big Splash!” The bottom right panel depicts the two women holding hands and jumping into a sea of waves. Text on the bottom left indicates these quotations are from Jean Hibino’s oral history for the Japanese American Intergenerational Narratives Oral History Project.
TOPAZ by Emily Ehlen
This image titled TOPAZ consists of four panels. The top panel depicts white stars behind barbed wire in red and blue that mimics the American flag, as well as a guard tower. The next panel depicts footsteps with plants sprouting from the final four steps. To the right of the footsteps, a white paper crane rests on soil. Red and blue barbed wire appears in the background. Text at the bottom of this panel reads, “The path we make will help us and others heal.” The bottom two panels depict barbed wire at the top and bottom, which frame a group of people all holding hands walking to the right. The group of people, which includes a range of ages, spans both panels. The individuals have glowing lights over their hearts. Plants sprout from the bottom of this panel.
SILENCES by Emily Ehlen
This image titled SILENCES consists of two panels. In the top panel, a woman cries while framed by red barbed wire. The bottom panel depicts wire cutters snipping the red barbed wire. Text reads, “SNIP!” Beneath the barbed wire is text that reads, “We must find the strength to create change. Gather all of our courage so that their silences can be transformed.” Beneath this text is a scene depicting a man with a child on his shoulders moving toward a woman with open arms. To the right of them are an elderly woman and man. Behind the group of people, there is a large, red circular ensō formed from the barbed wire. Glowing lights also appear in the background.
TREE by Emily Ehlen
This image titled TREE consists of one panel, depicting three women of different generations holding hands in front of a large tree wrapped in red barbed wire and filled with white paper cranes. This image includes text which reads, “‘I liked the idea of a piece of paper, let’s say you crumpled a piece of paper, you can still flatten it out, but you can’t undo those folds, you’ll still see evidence, but you can still make something beautiful.” Text on the bottom left indicates these quotations are from Jennifer Mariko Neuwalder’s oral history for the Japanese American Intergenerational Narratives Oral History Project.
FEAST by Emily Ehlen
This image titled FEAST consists of one panel that depicts a long table that stretches from the left side to the bottom right which loops before reaching four people of different generations eating. The food on the table includes a variety of foods like sushi, lasagna, salad, turkey, and dumplings. Text at the top of the image reads, “‘Well, New Year’s was always the big one, my favorite, because of all the food. And my grandmother on my dad’s side used to do a huge New Year’s spread, and so I used to go over to help her prepare the food a couple days in advance, help her cook. And actually, she’s the one that taught me a lot of Japanese cooking, I learned from her.'” Text on the bottom left of the image reads,, “‘So each of these foods has a certain significance, like one is for good luck, one is for good health, different things like that. And so every year we’d all have to eat at least one bite of each of these things. But I always look forward to New Year’s, because it was a day that you would just basically eat all day.'” Text on the bottom left indicates these quotations are from Kimi Maru’s oral history for the Japanese American Intergenerational Narratives Oral History Project.
Acknowledgments for the Japanese American Intergenerational Narratives Oral History Project
This project was funded, in part, by a grant from the U.S. Department of the Interior, National Park Service, Japanese American Confinement Sites Grant Program. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the opinions or policies of the U.S. government. Mention of trade names or commercial products does not constitute their endorsement by the U.S. Government.
This material received federal financial assistance for the preservation and interpretation of U.S. confinement sites where Japanese Americans were detained during World War II. Under Title VI of the Civil Rights Act of 1964, Section 504 of the Rehabilitation Act of 1973, and the Age Discrimination Act of 1975, as amended, the U.S. Department of the Interior prohibits discrimination on the basis of race, color, national origin, disability or age in its federally funded assisted projects. If you believe you have been discriminated against in any program, activity, or facility as described above, or if you desire further information, please write to:
Office of Equal Opportunity
National Park Service
1201 Eye Street, NW (2740)
Washington, DC 20005
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. The Oral History Center is a predominantly self-funded research unit of The Bancroft Library. As such, we must raise the funds to cover the cost of all the work we do, including each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Emily Ehlen graduated from Ringling College of Art and Design and lives in Florida.
For the first time, the Oral History Center, or OHC, partnered with an artist named Emily Ehlen, who created ten graphic narrative illustrations based upon stories and themes recorded in the OHC’s Japanese American Intergenerational Narratives Oral History Project, or JAIN project. The JAIN project documents and disseminates the ways in which intergenerational trauma and healing occurred after the United States government’s mass incarceration of Japanese Americans during World War II.
WAVE by Emily Ehlen
The OHC’s JAIN project documents and disseminates the ways in which intergenerational trauma and healing occurred after the United States government’s mass incarceration of Japanese Americans during World War II. The OHC team interviewed twenty-three Japanese American survivors and descendants of the World War II incarceration to investigate the impacts of healing and trauma, how this informs collective memory, and how these narratives change across generations. Initial interviews in the JAIN project focused on the Manzanar and Topaz prison camps in California and Utah, respectively. The JAIN project began at the OHC in 2021 with funding from the National Park Service’s Japanese American Confinement Sites Grant. The grant provided for 100 hours of new oral history interviews, as well as funding for a new season of The Berkeley Remix podcast and Emily Ehlen’s unique artwork, all based on the JAIN project oral histories.
Below is an interview with Emily Ehlen about her processes in creating such dynamic illustrations drawn from the memories and reflections of JAIN oral history narrators. You can see and save copies of larger images of Emily’s artwork for the JAIN project in a separate blog post.
Artist Bio:
Emily Ehlen is best known for her colorful and whimsical illustrations using mixed media. Watercolor, ink, spray paint, and gouache are the primary mediums she uses for her traditional works, and she also integrates them in her digital pieces. She loves being positive and expressing her interests while using her surroundings as inspiration. To invoke curiosity and imagination, her drawings reflect an open view of the subject and are framed with pieces of expression and reality. Change and adaptability are a constant as she goes through various experimentations and approaches to her art.
Q&A with artist Emily Ehlen:
Q: What was your process for creating the Japanese American Intergenerational Narratives artwork?
Draft version of SILENCES by Emily Ehlen
Emily Ehlen: My process started with selecting powerful imagery and phrases in relation to connecting themes found throughout the oral history transcripts. I composed thumbnails with the intent to represent the information clearly and use symbolism to convey the narrative. I wanted to use as much text from the source as I could, but I wanted to avoid it being too word heavy. It was a balancing act of editing the text and imagery to support each other in the composition and narrative. After developing and consolidating the initial drafts I moved on to tighter linework and color concepts. Once the colors were established, I inlaid patterns and handmade textures to add contrast between objects, panels, and the background. The handmade textures were made with ink washes and spray paint. The final step was applying shading and details to enhance the focus of each element while also keeping the flow throughout the entire composition.
Q: How was your work on this project similar or different to your prior art projects?
A section from Emily Ehlen’s comic “Weaver’s Weaver,” about Kay Sekimachi
Emily Ehlen: This Japanese American Intergenerational Narratives art project was similar to the comic series Drawn to Art: Tales of Inspiring Women Artists that I worked on in 2021 for the Smithsonian American Art Museum. For that Smithsonian project, I drew a three page comic called “Weaver’s Weaver,” featuring Kay Sekimachi, a Japanese American artist. My process for both projects were pretty identical. Although, I think I had a little more freedom with expanding the storytelling elements working on the JAIN project comics. Overall, they were mutually great experiences that I am so grateful to have been a part of.
Q: How did engaging with the Japanese American Intergenerational Narratives oral history transcripts shape the stories you chose to tell and some of the imagery you used in your graphic art?
FEAST by Emily Ehlen
Emily Ehlen: When drafting the concepts of the illustrations, I wanted to use imagery that would convey the message the stories presented. Reading the oral history transcripts, I found lots of interesting details to include, like with the different types of food to include in the FEAST composition. It was inspiring to hear everyone’s unique voice sharing aspects about their and their family’s lives.
Q: How did you choose the various scenes and stories that you eventually depicted? What stories in the transcripts most stood out to you? Why?
EUCALYPTUS by Emily Ehlen
Emily Ehlen: I illustrate with the goal to portray a story the audience can connect and respond to. I wanted to choose stories with lots of emotions that I could highlight in each drawing. The piece I got the most emotional while drawing was Nancy Ukai’s grandfather in EUCALYPTUS. I sympathized with the longing and sadness of missing Berkeley that her grandfather felt. I understood the rationality behind using the box for something else, but that emphasized just how important Berkeley was to him. It was heartbreaking to read, so I knew I had to draw it.
Q: What are some of the story themes that you worked to express throughout your art for this project?
TEACHER by Emily Ehlen
Emily Ehlen: The focus was how the Japanese American incarceration during World War II impacted themselves, their families, and how they responded to it. The themes were identity and belonging, intergenerational connections, and healing. I wanted the weight of the words to be carried through to the art accompanied with them.
Q: Can you describe some of the visual themes or repeated imagery that you incorporated throughout the various pieces you created? How and why did you develop these visual themes?
TREE by Emily Ehlen
Emily Ehlen: The color palette I used helped create the tone and atmosphere of each piece separately while also keeping the collection cohesive. The red was used with duality: the bright saturated hue represented youth, rebelliousness, and intensity; while the dark maroon represented authority and repressed quietness. The soft green color was used to depict change and positivity that connects to the healing theme. The navy blue signifies unity and freedom, but it is used with a sense of serenity and heaviness. For example, the blue in TEACHER extrudes an overbearing presence in contrast to when it’s used in TREE. The ochre yellow has different meanings for its surroundings, like in TEACHER it signifies uncertainty, and in STORIES it’s used to display hope.
STORIES by Emily Ehlen
The water pattern, waves, and watercolor texture are used with family elements, and it contrasts the dry gritty spray paint texture that references the environment of Topaz and Manzanar. Waves are symbols of growth, renewal, and transformation. They also represent the unpredictability of life, to which people learn to navigate its ups and downs. The plants and paper cranes also relate to family connections, development, and healing, going through many stages and flourishing together.
For darker imagery, I wanted the red barbed wire to be synonymous with the red stripes we see on the American flag. To show the lack of freedom and injustice that the Japanese Americans faced, those stripes became wire that entrapped and left scars on following generations. The guard towers were a beacon of looming authority and danger at the incarceration camps. They became a mental block for some that were confined in their silences.
Q: While creating the JAIN art, what did you learn that was new to you?
TOPAZ by Emily Ehlen
Emily Ehlen: I really enjoyed learning about everyone’s perspectives and experiences with being Japanese American. I am Chinese American, so I empathize with the stories about identity and the sense of belonging. This project lit up my desire to discover more about my culture. My motivation for drawing is to see how my art mirrors my development as a person. I think art is a record of growth and change. Like time, it never stops moving forward.
Q: Can you describe one or two of your favorite pieces that you created for this project? Why does this one stand out for you?
SPLASH by Emily Ehlen
Emily Ehlen: This is like asking the question, “Who’s your favorite child?” It’s super difficult because I love each piece for different reasons. I had the most fun drawing the piece SPLASH, about Jean Hibino and her mother. I think it has the most dynamic composition with how the imagery flows together with the text. I like the sequence of stillness to movement, and how a ripple can start a wave.
Q: What are your hopes for how people engage with your art for this project? Who do you hope sees it? What do you hope people take away from your art for this project?
MANZANAR by Emily Ehlen
Emily Ehlen: My hope for how people engage with the comic is to have open conversations about them or topics related to it. It would be nice to see what sticks out to people the most and what connections they make through their perspectives. I hope people are able to feel the sentiments in each piece and learn new aspects of its history. I can’t think of anyone specific I’d want to see it, but I strive to be someone who inspires others by taking creative approaches to new ideas. So, I hope other artists who are interested in drawing and story-telling see it
You can see and save copies of larger images of the graphic art that Emily Ehlen created for the Japanese American Intergenerational Narratives Oral History Project in a separate blog post. We encourage you to use and share Emily Ehlen’s artwork, along with the JAIN project oral history interviews, especially in classrooms when teaching the history and legacy of the World War II incarceration of Japanese Americans. When using these images, please credit Emily Ehlen as the artist (for example, Fig. 1, Ehlen, Emily, WAVE, digital art, 2023, Oral History Center, The Bancroft Library, University of California, Berkeley), and see the OHC website for more on permissions when using our oral histories.
Acknowledgments for the Japanese American Intergenerational Narratives Oral History Project
SILENCES by Emily Ehlen
This project was funded, in part, by a grant from the U.S. Department of the Interior, National Park Service, Japanese American Confinement Sites Grant Program. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the opinions or policies of the U.S. government. Mention of trade names or commercial products does not constitute their endorsement by the U.S. Government.
This material received federal financial assistance for the preservation and interpretation of U.S. confinement sites where Japanese Americans were detained during World War II. Under Title VI of the Civil Rights Act of 1964, Section 504 of the Rehabilitation Act of 1973, and the Age Discrimination Act of 1975, as amended, the U.S. Department of the Interior prohibits discrimination on the basis of race, color, national origin, disability or age in its federally funded assisted projects. If you believe you have been discriminated against in any program, activity, or facility as described above, or if you desire further information, please write to:
Office of Equal Opportunity
National Park Service
1201 Eye Street, NW (2740)
Washington, DC 20005
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. The Oral History Center is a predominantly self-funded research unit of The Bancroft Library. As such, we must raise the funds to cover the cost of all the work we do, including each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Video clip from Robert Cox’s oral history on the Sierra Club’s environmental justice work with Jesus People Against Pollution (JPAP) in 1994
UNC Professor Robert Cox in 1994 upon his first time being elected as president of the national Sierra Club
Robert Cox is a scholar and a gentleman. He also has a fire burning in his belly for protecting nature, confronting injustice, and empowering people, which fueled his long-time leadership in environmental politics, strategy, and influential communication. Robbie Cox served three times as president of the national Sierra Club in 1994-96, 2000-01, and 2007-08. He is Professor Emeritus at the University of North Carolina at Chapel Hill (UNC-CH), and as a scholar of activist rhetoric, Cox helped found the academic field of environmental communication.
Robbie and I recorded nearly eleven hours of his life history over Zoom during five interview sessions in September 2020, during the early months of the COVID-19 pandemic. Robbie’s inspiring stories of environmental activism produced a 253-page transcript, which includes an appendix with several photographs. The stories that Robbie shared in his oral history also emphasized the incredibly high stakes for our present moment of environmental politics, rhetoric, and civic engagement.
Cox was born in September 1945, in Hinton, West Virginia, where his early influences included roaming Appalachian forests and rivers as well as his family’s history of union organizing and work toward social justice. He was recruited to the debate team at the University of Richmond where, from 1963 to 1967, he studied communication, philosophy, history, and religion while also participating in civil rights protests. In 1970, Cox earned his Ph.D. in classical rhetoric studies from the University of Pittsburgh with a dissertation on the rhetorical structures of the Vietnam antiwar movement in which he actively participated. From 1971 to 2010, Cox was a Professor in the Department of Communication at UNC-CH where he helped establish the field of environmental communication and focused his research and teaching on argumentation, rhetorical theory, and social movements. Cox married Professor Julia Wood in 1975 when she also joined the UNC-CH faculty in the Department of Communication.
Video clip from Robert Cox’s oral history on first joining the Sierra Club in 1979
Robert Cox (right) with North Carolina Secretary of Natural Resources Joe Grimsley (left) discussing what would become the North Carolina Wilderness Act of 1984.
Upon Dr. Wood’s suggestion, Cox joined the Sierra Club in 1979 and, over time, he earned leadership positions at every level in the Club: as chair of the Research Triangle Group, as chair of the North Carolina Chapter, and as an elected member to the national board of directors for most years between 1993 and 2013, including three times as president of the national Sierra Club. Cox made significant contributions to passage in the US Congress of the North Carolina Wilderness Bill, to the Sierra Club’s early engagements in the environmental justice movement, to restructuring both the Club’s internal governance and its volunteer structure, as well as helping lead Sierra Club engagements in national politics, particularly during his times as Club president. In this oral history, Cox discusses all of the above, with a focus on leveraging influential communication and strategy, while also sharing his experiences hiking and trekking in the Himalayas, in the mountains of Europe, and in the Appalachian Mountains.
Robbie Cox’s oral history is significant for detailing the environmental activism and political strategies of one of the most influential volunteers in recent Sierra Club history. Some of the themes throughout Robbie’s oral history include the profoundly democratic nature of the Sierra Club, details on the Club’s geographically diverse grassroots activism, as well as numerous ways that volunteer environmentalists work together to shape state and national legislation. Robbie also reconstructed the ways he balanced his double life as UNC professor with his life as an environmental activist, especially through his work in Sierra Club media campaigns. He recounted his decades as a nationally elected volunteer leader in the Sierra Club, as told through the perspective of an academic scholar of rhetoric and communications. And throughout, Robbie shared stories of direct action for environmental causes at all levels of Sierra Club engagement, from local to national.
Video clip from Robert Cox’s oral history on passing the North Carolina Wilderness Act in 1984
The in-depth, life-history approach used in this oral history reveals ways that Robbie’s personal influences and his engagements in the Sierra Club evolved over time. For instance, Robbie’s family history of labor activism instilled in him the power of people and the importance of social justice. Similarly, his participation on debate teams shaped substantially his education and academic work, while also playing a central role throughout his life as a political and environmental activist. Robbie’s interview also explored the Sierra Club’s and his own personal engagements with environmental justice, including his attendance at the First National People of Color Environmental Justice Leadership Summit in 1991, his leveraging of media in the national Sierra Club’s partnership with “Jesus People Against Pollution” in Mississippi, as well as his experiences on toxic tours of colonias in Matamoro, Mexico, along with other actions against the negative results of neoliberal free trade agreements.
Robert Cox (center) speaking in November 1995 as Sierra Club president at the US Capitol Building while delivering to House Speaker Newt Gingrich several green bags containing copies of the Environmental Bill of Rights petition signed by more than a million Americans.
Robbie also shared insider details on several significant moments in the Sierra Club’s recent history. He recounted the Club’s severe financial crises in the 1990s that resulted in his work to reorganize the Club’s internal governance through Project Renewal as well as the Club’s volunteer structures via Project ACT. Robbie recounted his central role in the Sierra Club’s efforts to combat the de-regulatory and anti-environmental Congressional agenda in wake of Newt Gingrich’s Republican take-over of Congress in the 1990s, as well as Robbie’s personal role in securing the Sierra Club’s endorsement of Al Gore, for whom Robbie campaigned in 2000. Robbie also detailed the central role he played in the Groundswell Sierra campaign in the early 2000s to resist a take-over of the Sierra Club by anti-immigration and white supremacist forces. And as the world warms and the seas rise, Robbie discussed ways that the Sierra Club has confronted the compounding crises of climate change in the twenty-first century. Robbie’s decades of environmental activism provides a lens on ways the environmental movement has evolved over time from its early focus on wild lands, to concerns about human health, to engagement on issues of environmental justice, to the modern complexities of climate change. Robbie also reflects on the contemporary Sierra Club’s internal and external challenges in its ongoing work for equity, inclusion, and justice.
Video clip from Robert Cox’s oral history on delivering to Congress the Environmental Bill of Rights with 1.2 million signatures in 1995
Robert Cox (left) and US Vice President Al Gore (right) in July 2000 in Grand Rapids, Michigan, delivering the Sierra Club’s public endorsement of Mr. Gore for US President during the 2000 election.
Back in the summer of 2020, when I spoke with Carl Pope, former Sierra Club executive director, to prepare for Robbie’s oral history, Pope recalled Robbie’s exceptional leadership and effectiveness. When “Professor Cox” first won election to the national Sierra Club board of directors in the 1990s, Pope described Robbie’s presence as “immediately noticeable.” Pope told me how Robbie used his expertise in rhetoric to unify people and advance proposals for environmental action. “You could see Robbie work at a board meeting,” Pope remembered. “When he wanted to get the board to agree, he would offer some initial proposal tentatively, then let folks respond to it and let the room talk. Then he’d come back in and make the same proposal, but he changed two words to see if that worked. He’d keep playing with the proposal and make changes rhetorically, until he got something that would work for everyone.” The Sierra Club’s board of directors come increasingly from a variety of backgrounds across the United States. All directors are volunteers, not employed staff, but like much of the Sierra Club staff, many Club directors consider themselves to be full-time environmental activists. As Carl Pope noted, however, most Sierra Club directors “are not professional communicators. People would talk past each other. Robbie’s skill on the board lubricated that process, which was phenomenally helpful. If anyone wanted to get something done, you asked Robbie.” Indeed, Robbie Cox got things done.
Pope also described Robbie as a kind of environmental philosopher. “He wasn’t ideological,” Pope explained, “but surely, he had his own vision of where the Club should go.” Now, with this publication of Robbie Cox’s oral history, you too can have him tell you in his own words about his visions for the Sierra Club and the ways he mobilized constituencies to make a reality of his visions for environmental protection, political power, and justice.
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of all the work we do, including each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Listen to podcast episode 3, “Environmental Justice for All,” or read a written version of this podcast episode below.
Podcast Episode 3: “Environmental Justice for All” is part of the Voices for the Environment exhibition in The Bancroft Library Gallery
Voices for the Environment: A Century of Bay Area Activism is a gallery exhibition in The Bancroft Library that charts the evolution of environmentalism in the San Francisco Bay Area through the voices of activists who advanced their causes throughout the twentieth century—from wilderness preservation, to economic regulation, to environmental justice. The exhibition is free and open to the public Monday through Friday between 10am to 4pm from Oct. 6, 2023 to Nov. 15, 2024, in The Bancroft Library Gallery, located just inside the east entrance of The Bancroft Library. Curated by UC Berkeley’s Oral History Center, this interactive exhibit is the first in-depth effort to showcase oral history along with other archival collections of The Bancroft Library.
This exhibition includes three podcast episodes that offer deeper narratives to supplement the archival posters, pamphlets, postcards, photographs, oral history recordings, and film footage that are also presented in the gallery. Please use headphones when listening to podcasts in The Bancroft Library Gallery.
A written version of podcast episode 3 is included below.
Listen to episode 3: “Environmental Justice for All” on SoundCloud.
Episode 3: “Environmental Justice for All.” This podcast episode accompanies a section of the Voices for the Environment exhibition that explores how, in the 1980s and 90s, communities of color in the Bay Area fought against environmental racism by creating new organizations, such as the Urban Habitat Program, to demand environmental justice—the equal treatment and meaningful involvement of all people in environmental decision-making. In the city of Richmond, activists in the West County Toxics Coalition and the Asian Pacific Environmental Network, or APEN, organized against toxic threats from the area’s petrochemical and hazardous waste facilities. Environmental justice activists helped transform the American environmental movement from one focused mostly on landscapes to one that increasingly includes the health and wellbeing of historically disenfranchised people.
This podcast episode features historic interviews from the Oral History Center archives in The Bancroft Library at UC Berkeley, including segments from oral history interviews with Carl Anthony, Pamela Tau Lee, Henry Clark, and Ahmadia Thomas, all recorded in 1999 and 2000. This episode was narrated by Sasha Khokha, with thanks to KQED Public Radio and The California Report Magazine.
This podcast was produced by Todd Holmes and Roger Eardley-Pryor of the Oral History Center of The Bancroft Library at UC Berkeley, with help from Sasha Khokha of KQED. The album and episode images were designed by Gordon Chun.
WRITTEN VERSION OF PODCAST EPISODE 3: “Environmental Justice for All”
Pamela Tau Lee: We cannot be afraid to talk about environmental racism. We cannot be afraid to discuss that, talk about what it means: the discrimination of communities in environmental policy and being left out of the process.
Sasha Khokha: What does justice look like? Whose lives matter? And how does that relate to the environment? In the 1980s and 90s, concerns about toxic industrial waste led communities of color in the Bay Area, and across the nation, to create new organizations and demand environmental justice—the equal treatment and meaningful involvement of all people in environmental decision-making.
Pamela Tau Lee: What we need to deal with is the racism that is the root cause of why industry was targeting communities of color: because communities of color would not have any power; that it’s much more acceptable to dump this stuff in communities of color. So if we shied away from talking about racism, we would then not be able to articulate the realities, and we felt it was racism.
[music]
Sasha Khokha: Welcome to Voices for the Environment: A Century of Bay Area Activism. This podcast accompanies an exhibition in The Bancroft Gallery at UC Berkeley that’s the first major effort to bring together both the oral history and archival collections of The Bancroft Library. The voices you’ll hear were recorded by UC Berkeley’s Oral History Center, founded in 1953 to record and preserve the history of California, the nation, and our interconnected world.
Voices for the Environment traces the evolution of environmentalism in the San Francisco Bay Area across the twentieth century, and highlights ways that Bay Area activists have been on the front lines of environmental change.
This is our third and final episode, called “Environmental Justice for All.” I’m your host, Sasha Khokha, from KQED.
[harmonica blues music]
Sasha Khokha: Communities of color have long confronted environmental racism—the disproportionate burden of toxic waste and industrial pollution in neighborhoods that are mostly low income and home to BIPOC folks. But up until the 1980s, the big players in the environmental movement focused on other issues, like preserving redwood groves or protecting bay shoreline from new construction.
Pamela Tau Lee: I think many of the mainstream organizations, you know, they don’t focus on people. They focus on the ecology and other natural resources.
Sasha Khokha: That’s Pamela Tau Lee, a environmental and labor activist from San Francisco whose oral history you’re hearing.
Pamela Tau Lee: These predominantly white organizations did not want to really acknowledge that there was a different experience felt by communities of color.
Sasha Khokha: Take the city of Richmond, where more than 75% of residents identified as people of color in the 2022 census. Located along the bay above Berkeley and Oakland, Richmond has been home to the Chevron oil refinery since 1902. A host of other polluting industries were established there, too. As a result, people in Richmond experience higher levels of pollution and toxins, and have less access to healthy environments to live and play. In the mid-1980s, Richmond residents formed the West County Toxics Coalition. It’s a multi-racial organization aimed at empowering the community to have a greater voice in the environmental issues impacting their neighborhoods.
Henry Clark: You know, like anyone born and raised in North Richmond, we know that there was environmental problems there, you know, over your whole lifetime. So it was quite only logical when the West County Toxics Coalition was formed and they began to organize in North Richmond.
Sasha Khokha: That’s Henry Clark, who grew up in North Richmond. In 1986, after earning his Ph.D. in religious studies, Clark became executive director of the West County Toxics Coalition, and he led it for more than three decades. As a kid in North Richmond, Henry Clark’s home was directly next door to the Chevron oil refinery.
Henry Clark: I can remember clearly waking up many mornings and finding the leaves on the tree burnt crisp overnight from chemical exposure, or you know, going outside and the air would be so foul that you would literally have to grab your nose and try to not breathe the air and go back in the house and wait until it was cleared up. Those type of situations, you know, were a common experience.
Sasha Khokha: Ahmadia Thomas also knows about the foul air in Richmond. She moved there in the mid-1970s and was active in community organizing.
Ahmadia Thomas: Well, then I first came here, I didn’t know, but I used to smell these terrible odors. And I’d say, “What’s that?” And my husband said, “We all smelled it all the time, and we ain’t never made no kick about it.” But they didn’t know what they were smelling. And they were terrible odors: you know ones that smell like sulfur once in a while. Terrible odors out here, after I got out here. When I first came, I didn’t remember smelling all this stuff, but boy, after I was out here a while, I really got environmentally conscious.
Sasha Khokha: Thomas joined the West County Toxics Coalition, too, in part because she was concerned about how Richmond’s industrial pollution was affecting her health—and her neighbors’ health.
Ahmadia Thomas: Like a lot of people had long-term illnesses. Like, these illnesses we don’t know whether they’re short-term or long-term. But if you’ve been affected, say, five years ago and you’re still affected, well now that’s a long term. But, see, a lot of them has been affected. Children, too.
Sasha Khokha: Regular chemical exposures contributed to those illnesses, and so did the periodic accidents, fires, and explosions at the Chevron refinery.
Ahmadia Thomas: And then when they started having the accidents—whoo! There was always a fire or accident. It would be on the TV or in the paper: “There was an accident, but it wasn’t no harm to your health.” And that ain’t true! [laughs] Got to hearing that.
Sasha Khokha: Here’s Henry Clark again.
Henry Clark: You know, these chemical disasters, they do affect people’s lives and people do die from them. You usually don’t hear about the deaths that do occur. You now, they just end up being faceless people whose families may be aware of it, but most of the time you don’t hear about that. Nor do you really even get a good sense of the health impacts, because usually there’s no type of comprehensive health studies that are done or conducted after these disasters.
Sasha Khokha: But the health studies that have been conducted are clear.
Henry Clark: I do know that there’s a 33 percent higher than state average lung cancer rate throughout the Richmond area stretching actually throughout the county, stretching through the industrial corridor.
Sasha Khokha: Here’s Carl Anthony. He’s an architect, a city planner, and a former professor at UC Berkeley.
Carl Anthony: The communities get it. You don’t have to have a Ph.D. to figure out if you have asthma rates five or six times the regional average, it’s clearly symbolic of racism. It is an environmental racism.
Sasha Khokha: With so many other Bay Area groups focused on land, trees, and wildlife, Carl Anthony saw the need for a new organization to deal with the complex urban issues confronting communities of color.
[blues music]
In 1989, Anthony co-founded the Urban Habitat Program to focus on people who lived in cities. He envisioned it would be as multi-racial and multicultural as the Bay Area where he lived. And to better understand the connections between social injustice, economic inequality, and environmental racism, Anthony also helped create a groundbreaking journal, first published on Earth Day in 1990, called Race, Poverty, and the Environment.
Carl Anthony: When we began the Race, Poverty, and the Environment journal, we started looking at these. What is the energy cycle? We began to see that the whole system of extracting energy, distributing it, consuming it, and waste, at every step were huge social issues.
Sasha Khokha: Like the chemical pollution near oil refineries, or the health and safety issues for workers there, or the high cost of energy for low income people: all intertwined social and environmental issues. As executive director of the Urban Habitat Program, Carl Anthony built upon the Bay Area’s progressive and environmental traditions, with a focus on community-led decision making and public investment in historically disenfranchised neighborhoods. But, the more Anthony engaged with issues of environmental justice, the more problems he saw in the ways that mainstream, mostly white American environmental activists understood their own history.
Carl Anthony: There was a deep problem in the myth of the environmental movement, the story of the environmental movement, as having grown out of a certain understanding about the settlement of North America. Put really briefly, the settlement began in New England when the Puritans arrived, and then they found an empty wilderness, and they cleared the forests and built the dams and the towns, and came all the way across the country, and then they looked back and saw how much devastation they had made.
Sasha Khokha: By the start of the 20th century, that environmental devastation inspired the early conservation movement, led by preservationists like John Muir. But for Carl Anthony, this narrative focused too much on wilderness and the conservation of public lands, and not enough on the history of race and American expansion.
Carl Anthony: You know, if you look back a little bit, you say, “Wait a minute, hold it, what’s wrong with this model?” First of all, the North American continent wasn’t empty. There were ten million people here. So where do they fit in this story? And then, millions of people were brought from Africa who worked the land—now it has been eighteen generations—where do they fit in this story? And in particular, from the point of view of the racial issues, the things that were missing in the John Muir model was that this was the end of manifest destiny. It was the end of the frontier wars with the Indians. These were the years when there was rampant racism against Chinese people and against Japanese people in California; the years when Jim Crow was established, and the national parks were set up that were white only.
Sasha Khokha: If the old land-focused narrative of American environmentalism ignored social and racial issues, it also overlooked the urban issues that Carl Anthony was so passionate about.
Carl Anthony: So, the point I’m making about cities is that the environmental movement took off in many ways by saying, “We’re not connected with that whole thing, that mess around the cities. We’re not going to deal with that.” So there was this big hole. But in many ways, the issues that people are complaining about—whether it’s global warming, or whether it’s the squandering of, you know, chopping down the trees, whatever it is—are rooted in the way that we’re living in cities. So I felt that by setting up the Urban Habitat Program, we would then be in the position to be able to say, “This is how we need to think and act in relationship to restoring our cities. Here’s how we’re going to address the environmental issues; here’s how we’re going to address the social justice issues; here’s how we are going to address the economic issues. And because you care so much about biodiversity and energy efficiency and all these things, we would like to invite you to participate with us in doing that.”
[music]
Sasha Khokha: Bay Area activists soon discovered they weren’t alone in the fight for environmental justice. Shortly after starting the Urban Habitat Program, Anthony learned about the Toxic Wastes and Race report published in New York by the United Church of Christ’s Commission on Racial Justice. That analysis showed how government agencies across the nation consistently located toxic waste facilities in communities of color. And when the Church and other groups began to organize a national summit on environmental justice, the Bay Area sent a huge contingent.
Pamela Tau Lee: . . . 1991, in Washington DC, was so powerful to see people of color in this room talking about their struggles for justice in this country. I had not heard anything as dynamic and comprehensive since the Civil Rights [Movement] when I was young.
Sasha Khokha: Pamela Tau Lee, then a labor activist in San Francisco, attended that First National People of Color Environmental Leadership Summit.
Pamela Tau Lee: When you came into that room, you saw native people from Alaska, the deserts of Nevada, the Shoshone tribe. You saw African Americans who lived in small towns in the middle of Alabama, from the South, New Orleans, with African Americans from Harlem, and Detroit, and South Central Los Angeles. You saw brown people from Puerto Rico, from the border, together with Chicanos from New Mexico and California and farmworkers.
Sasha Khokha: At the summit, leaders of color shared examples of environmental racism from across the country, and they discussed what to do about it.
Pamela Tau Lee: People were there to articulate, what is it that we are experiencing? And what is it that we want? And what it is that we stand for? One is we cannot be afraid to talk about environmental racism. In many of the discussions when we start to talk with the traditional environmentalists, who are mainly white, or the government, they were very afraid of that term. And we said we cannot be afraid to discuss that, talk about what it means: the discrimination of communities in environmental policy and being left out of the process. The mainstream environmentalists, they didn’t want us to say anything about racism. They wanted us to use the word “equity.” And what we need to deal with is the racism that is the root cause of why industry was targeting communities of color: because communities of color would not have any power, that it’s much more acceptable to dump this stuff in communities of color. So if we shied away from talking about racism, we would then not be able to articulate the realities, and we felt it was racism.
Sasha Khokha: As Pamela Tau Lee recalled, activists at the summit also discussed a way forward: demanding justice and taking action.
Pamela Tau Lee: What we wanted industry and the government to use as the criteria for action was the facts: that there is a Superfund site there, that the soil is contaminated, that children are sick, that people have cancer, that the air quality here is bad. And therefore, do something! And what we were coming up against was, you know, “Prove it. Prove that the people are sick. Prove it.” And these communities don’t have the resources to do that. The government and industry knows these people are sick, knows the air quality is bad, knows the soil is contaminated, and should take action. So that was another key component, illustrated very wonderfully in the Principles of Environmental Justice.
Sasha Khokha: The First National People of Color Environmental Leadership Summit, and the Principles of Environmental Justice created there, reshaped the trajectory of American environmentalism. It inspired a new generation of activists who put people—not just landscapes—within the environmental agenda. For Pamela Tau Lee, attending that 1991 summit motivated her and others to form a new Asian American organization for environmental justice that would work with people here, in the Bay Area.
Pamela Tau Lee: We came back, Asians came back, we talked together, networked together, and after three years, I think, we formed the Asian Pacific Environmental Network [APEN], which has done very powerful work . . . [with] the ability to begin to articulate what environmental justice looks like for the Asian communities in this country.
Sasha Khokha: The Asian Pacific Environmental Network, or APEN, formed in 1993, and its initial work began in Richmond. APEN helped the Laotian immigrant community from Southeast Asia gain a voice in the larger efforts to address the toxic pollution caused by the Chevron refinery and other industrial sites in the city. Today, APEN continues organizing communities for environmental justice throughout the Bay Area.
[music]
By the mid-1990s, the demands of the environmental justice movement reached the White House. On February 11, 1994, President Bill Clinton signed an Executive Order directing federal agencies to “identify and address the disproportionately high and adverse human health or environmental effects of their actions on minority and low-income populations.” Here’s Carl Anthony reflecting on that moment.
Carl Anthony: Well, I think it was, first of all, an incredible achievement. And I can tell you, the ones that did it in the environmental justice movement were virtually uncompromising that the grassroots people have to be at the table. I mean, [they said], “To hell with all these experts and all these consultants and all these people.” They brought the people in who were suffering from the asthma, and respiratory conditions, and from the cancer.
Sasha Khokha: While the executive order didn’t mandate specific actions by law, Pamela Tau Lee thought it was an important benchmark.
Pamela Tau Lee: I think that President Clinton’s order had a very big impact. Many people want to have more, but there is no way that it was going to become law. But that executive order, I think, gave the movement opportunity to advocate the formation of a national environmental justice advisory committee within the EPA. That enabled the White House to call an interagency body to regularly discuss this. And I think that, you know, it’s not like spectacular changes, but I think that it has made a difference.
[music]
Sasha Khokha: By the late 1990s, when most of the oral histories you’ve heard here were recorded, several environmental justice groups had formed in the Bay Area. Like PODER, a Latinx-led group in San Francisco whose name stood for People Organizing to Demand Environmental and Economic Rights. And PUEBLO, which stood for People United for a Better Life in Oakland. And the Silicon Valley Toxics Coalition in the south bay. These activists often supported each other’s efforts. Here’s Henry Clark.
Henry Clark: Here in the Bay Area, there’s different groups in Oakland or San Francisco that do similar type of work. And so when they have public hearings, or protests, demonstrations, or activities, we go and support their works, send people there to support their work. And when we would have activities here in the Richmond area, they send people over to support our work, so building relationships to mutual support.
Sasha Khokha: Working to integrate environmental, social, and economic change for justice is difficult. So activists celebrate their victories, large and small. Like in the year 2000, when APEN’s Asian Youth Advocates and its Laotian Organizing Project in Richmond were able to create community warning systems in multiple languages for when industrial accidents occur. Or in 1997, when the West County Toxics Coalition shut down the Chevron Ortho Chemical Company’s toxic waste incinerator, which had been belching out pollution for decades.
Henry Clark: That campaign was linked to the Chevron Ortho Chemical Company incinerator that had been operating since 19—I believe—67, on a temporary permit. And Chevron was in the process of getting a permit to expand the hazardous waste that was being burned in that incinerator. The West County Toxics Coalition felt that the company should not get a permit to expand their waste burning. In fact, they should actually decrease the waste that was being incinerated. So we organized a campaign to do public education. We received word that Chevron was withdrawing their permit application to expand the incinerator, and that the incinerator was going to be closing down. And so the incinerator has been closed and dismantled as of June of 1997.
[music]
Sasha Khokha: But creating change doesn’t happen quickly. Most of the big, mainstream and mostly white environmental organizations have been slow to expand their activism, their funding, their membership, and their leadership to include BIPOC folks. Even so, since the 1980s and 90s, activists for environmental justice have unequivocally transformed the U.S. Environmental movement from one focused on trees, and landscapes, and sensitive habitats, to one that increasingly includes the health and wellbeing of historically disenfranchised people.
Carl Anthony: What I consider the most important work that I’m involved in is reframing the environmental story.
Sasha Khokha: Here’s Carl Anthony again.
Carl Anthony: There will have to be a much more systematic acknowledgement that environmental and social issues are connected; they are not separate. In my view, that means the environmental justice movement in some fundamental way must become the mainstream of the environmental movement. And I think the environmental movement has had the enormous luxury of being a white movement. But if we’re really serious about changing the dynamics at a global scale, there’s no way that it can keep going as a white movement.
Sasha Khokha: Bay Area environmental justice organizations, like the Urban Habitat Program, have shown a way for activists to build upon their past while still moving forward, together.
Carl Anthony: We kind of represented that model. That yes, you could in fact be advocates of social justice, you could in fact be militant about social justice, and still be an advocate of environmental preservation.
Sasha Khokha: And Bay Area leaders like Henry Clark and Pamela Tau Lee were on the cutting edge of helping the public understand that environmental justice means justice for all.
Henry Clark: When you’re looking at it from an environmental justice perspective, or justice period, the bottom line is that you work out a situation where it will be just for everyone involved, and that’s really what you have to keep the major focus on, especially when you’re trying to deal with situations that have been historically unjust.
Pamela Tau Lee: Many wealthy whites were content for this to be in the back yards of poor communities of color. Well, we were not going to say, “No, we don’t want it. We’re going to put it in rich, white people’s backyards.” That’s not something that we were going to stand for. We were going to always fight for the protection of all, public health of all, the ecology for all.
Sasha Khokha: After all, as our shared world becomes more interconnected, these are issues that affect all of us. Here’s Carl Anthony again.
Carl Anthony: But ultimately, as we get into the twenty-first century, this is the story of how the whole human race is going to address the shadow side of the industrial revolution. It’s not just a Black story. The fact of the matter is that all of us who benefited from the way the industrial revolution had functioned, the gifts that it has given us, are participants in this problem of the shadow side of consumption and waste and all this. Black people just happen to have, you know, kind of an angle or an insight on a piece of this.
[music]
Sasha Khokha: Our relationships with the world around us define who we are. So do the relationships we have with each other. Over the last century, Bay Area activists helped advance our understanding of both of these kinds of relationships—from preserving California’s ancient forests, to regulating economic development, to pushing for the health of communities of color as an environmental issue. Today, the social and environmental challenges we face appear even more daunting than the ones earlier generations had to face. Only by working together and building on lessons from the past can we work toward the solutions we need to thrive in the twenty-first century and become the newest Voices for the Environment.
[music]
You’ve been listening to “Environmental Justice for All,” the third and final episode in the podcast accompanying Voices for the Environment: A Century of Bay Area Activism. It’s an exhibition in The Bancroft Gallery at UC Berkeley that runs from October 2023 through November 2024. This episode featured historic interviews from the Oral History Center archives in The Bancroft Library at UC Berkeley. It included segments from oral history interviews with: Carl Anthony, Pamela Tau Lee, Henry Clark, and Ahmadia Thomas. To learn more about these interviews and the Oral History Center, visit the website listed in the show notes. This podcast was produced by Todd Holmes and Roger Eardley-Pryor, with help from me, Sasha Khokha. Thanks to KQED Public Radio and The California Report Magazine. I’m your host, Sasha Khokha. Thanks so much for listening!
End of Podcast Episode 3: “Environmental Justice for All”
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of all the work we do, including each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Listen to podcast episode 2, “Tides of Conservation,” or read a written version of this podcast episode below.
Podcast Episode 2: “Tides of Conservation” is part of the Voices for the Environment exhibition in The Bancroft Library Gallery
Voices for the Environment: A Century of Bay Area Activism is a gallery exhibition in The Bancroft Library that charts the evolution of environmentalism in the San Francisco Bay Area through the voices of activists who advanced their causes throughout the twentieth century—from wilderness preservation, to economic regulation, to environmental justice. The exhibition is free and open to the public Monday through Friday between 10am to 4pm from Oct. 6, 2023 to Nov. 15, 2024, in The Bancroft Library Gallery, located just inside the east entrance of The Bancroft Library. Curated by UC Berkeley’s Oral History Center, this interactive exhibit is the first in-depth effort to showcase oral history along with other archival collections of The Bancroft Library.
This exhibition includes three podcast episodes that offer deeper narratives to supplement the archival posters, pamphlets, postcards, photographs, oral history recordings, and film footage that are also presented in the gallery. Please use headphones when listening to podcasts in The Bancroft Library Gallery.
A written version of podcast episode 2 is included below.
Listen to episode 2: “Tides of Conservation” on SoundCloud.
Episode 2: “Tides of Conservation.” This podcast episode accompanies a section of the Voices for the Environment exhibition that explores how three women in Berkeley formed the Save San Francisco Bay Association in the early 1960s to resist numerous land-fill projects that would have turned the waters of the San Francisco Bay into land. By 1965, advocacy from this association, later called Save The Bay, led to the creation of the San Francisco Bay Conservation and Development Commission, or BCDC, a new California state agency tasked with balancing the conflicting interests between economic development and environmental conservation. BCDC’s work helped bolster a rising tide of conservation that led eventually to similar state regulatory agencies, including the equally historic California Coastal Commission.
This podcast was produced by Todd Holmes and Roger Eardley-Pryor of the Oral History Center of The Bancroft Library at UC Berkeley, with help from Sasha Khokha of KQED. The album and episode images were designed by Gordon Chun.
WRITTEN VERSION OF PODCAST EPISODE 2: “Tides of Conservation”
Sylvia McLaughlin: And I was totally appalled, reading the [Berkeley] Gazette, of the city manager’s dream to fill over 2,000 acres in front of Berkeley. And this was one of the things that galvanized us into action.
Sasha Khokha: The San Francisco Bay Area is no stranger to development booms. From the Gold Rush to the rise of Silicon Valley, the region ‘s history has been marked by a steady stream of growth and development. In the decades after World War II, new industries and a roaring postwar economy brought millions of people to the Golden State. By 1962, California ranked as the most populated state in the union. State agencies built dams, universities, and a network of freeways matched only in its intricacy by a statewide aqueduct system stretching over 700 miles, north to south. In the Bay Area, this combined boom in both population and development meant space was at a premium, pushing developers to target building on the 1,600 square miles of the bay itself. By the late 1950s, city councils throughout the region considered a host of fill projects that would turn bay waters into habitable land. And that sparked environmentalists to push back.
Melvin B. Lane: Environmentalists should be extremists. They represent an extreme, and the people who are going to make a buck represent the other one. And the decision-maker should sweat it out in the middle.
[music]
Sasha Khokha: Welcome to Voices for the Environment: A Century of Bay Area Activism. This podcast accompanies an exhibition in The Bancroft Library at UC Berkeley that’s the first major effort to bring together both the oral history and archival collections of The Bancroft Library. The voices you’re going to hear were recorded by UC Berkeley’s Oral History Center, founded in 1953 to record and preserve the history of California, the nation, and our interconnected world.
Voices for the Environment traces the evolution of environmentalism in the San Francisco Bay Area across the twentieth century. It highlights how Bay Area activists have long been on the front lines of environmental change—from efforts to preserve natural spaces in the wake of the 1906 San Francisco earthquake and fire, to the midcentury fight for state environmental protections, to demands to address the disproportionate burden of pollution that sickened communities of color around the bay.
You’re listening to the second episode of Voices for the Environment. We’re calling it “Tides of Conservation.” I’m your host, Sasha Khokha, from KQED.
[mid-century jazz music]
In 1961, OaklandTribune reporter Ed Salzman published an article detailing the number of proposed projects to fill in parts of the San Francisco Bay. What sparked Salzman’s interest was not any one project in particular. But it was a 1959 Army Corp of Engineers map he had stumbled upon while working on another story in Sausalito. On the surface, the government map was a projection of the San Francisco Bay in the year 2000. To Salzman, it was a horrifying glimpse of the reality that awaited Bay Area residents if developers were allowed to keep filling in the Bay. What he saw took his breath away. On the map, the open bay had been reduced to a river. The article, published along with a graphic of the government map, sent shockwaves around the Bay Area, alarming three Berkeley residents: Catherine “Kay” Kerr, Esther Gulick, Sylvia McLaughlin, who talked about seeing that map in an oral history that all three women recorded together in 1985.
Catherine Kerr: There was no denying the fact that the visible destruction of the Bay had been, maybe, of unconscious concern, so that when the Army Corps map appeared in the OaklandTribune showing that the Bay would end up being a river by 2020 because of all the fill, it was clear to me that this was certainly a possible train of events, and it needed to be stopped.
Sylvia McLaughlin: And I was totally appalled, reading in the [Berkeley] Gazette, of the city manager’s dream to fill over 2,000 acres in front of Berkeley. And this was one of the things that galvanized us into action.
Catherine Kerr: What happened was that the map that came out in the Tribune was brought to my attention. I went to a tea at the Town and Gown Club, and I said to Sylvia, “Did you see that terrible future of the Bay? And Sylvia said, “I certainly did. I think we should do something about it.” About two weeks later, Esther came over. We were sitting in the living room, and it was a beautiful day, and the Bay was very blue. I said to Esther, “I don’t know what’s going to happen to the bay. Did you see the map in the Tribune?” She said, “Yes. Wasn’t it awful?” I said, “Well, do you think you would have time to do something about it?” Esther said, “Well, yes, I think I would.” So I said, “All right, good. There’s three.” I called Sylvia, and we got together, set a date for coffee, and decided how we would start. We decided to start with Berkeley.
Sasha Khokha: The three Berkeley women who started meeting in the spring of 1961 fit squarely within a well-established Bay Area tradition of women environmental activists. They were white, highly educated, and well-connected in local and state political circles. Kay Kerr, the initial organizer of the group, was a Stanford graduate who was regularly active on the Berkeley campus and in city affairs. Her husband, Clark Kerr, was a Berkeley professor and president of the UC system, a position that put Kay in regular contact with the UC Board of Regents, which included the Governor, Lieutenant Governor, and Speaker of the Assembly. Esther Gulick was a Berkeley graduate and wife of Berkeley economics professor, Charles Gulick. She, too, was active in campus and city affairs. Sylvia McLaughlin had graduated from Vassar College and later married Donald McLaughlin, president of a California gold mining company.
These three Berkeley residents bonded over a desire to save the Bay. They read city council plans, consulted with a host of academics on the Berkeley campus, and then called a meeting of the leading environmental organizations in the Bay Area. They were hoping that after they presented their information, the professional conservationists would take charge and spearhead the effort to save the Bay.
Esther Gulick: We had most of the leaders who were very influential in their own organizations.
Catherine Kerr: All of the conservationists that we could think of. The three of us had decided that we were not conservationists and this was a really terrible problem. We were going to tell them about the problem, and then we expected they would carry the ball.
Esther Gulick: We weren’t going to form an organization at all.
Catherine Kerr: We didn’t have any of the expertise. We explained about the Army Corps map. And everything that we could find out was that there were maybe eighty square miles of fill already proposed by various cities around the Bay. And so we said, “This is the problem.” And so, I remember Dave Brower saying. “Well, it’s just exceedingly important, but the Sierra Club is interested in wilderness and in trails.” Then the next guy, Newton Drury, said, “Well, this is very important, but we’re saving the redwoods, and we can’t save the Bay.” And then it went around the room to the point where there was dead silence. So we said, “Well, the Bay is going to go down the drain.” Dave Brower said, “Now there’s only one thing to do: start a new organization, and we’ll give you all our mailing lists.” And they all wished us a great deal of luck when they went out the door. Yes.
Sylvia McLaughlin: They said, “Someone should really do something about this.”
Esther Gulick: It turned out that we were the somebodies.
Sasha Khokha: When the meeting ended, the mission of saving San Francisco Bay stayed in the hands of these three Berkeley women. The new organization they formed that evening in the Berkeley Hills would be known as the Save San Francisco Bay Association. And the environmental groups who felt they couldn’t take on the Bay campaign? They did follow through on the promise to share their mailing lists with Kerr, Gulick, and McLaughlin. Out of the first 700 mailers the three women sent out, they received some 600 pledges of support. Within a month, Save San Francisco Bay had secured a solid membership base. And those members were starting to get vocal in their opposition to Berkeley’s plan to to fill in more than 2,000 acres of Bay shoreline. The expansion would have doubled the size of the university town.
Sylvia McLaughlin: Berkeley had gotten—their plan was at the stage of the planning commission. They were holding hearings, almost the last stage before it got to the city council itself.
Esther Gulick: I think that’s what made the people of Berkeley, when we once got organized and sent letters to about a thousand people in Berkeley to ask them if they were interested in joining Save The Bay and told them some of the things that were going to happen if this went through—like Berkeley being almost twice the size as it now is, with the other half out in the Bay, and there were things like maybe an airport going to be out there, there were going to be storage buildings and that kind of thing—they just couldn’t believe it. You know? They, like us, thought the Bay belonged to us, the Bay belonged to everybody.
Sasha Khokha: Thanks to the new Save San Francisco Bay Association, Berkeley city council meetings were soon inundated with objections to the plan. So were the mailboxes of elected officials.
Sylvia McLaughlin: We felt that numbers were very important. As an example, at the city council meetings we noticed that the people who stood up to represent themselves had no audience. The city council in those days was very polite. But if someone stood up and said they represented an organization of thus-and-so-many members, the city council was more inclined to lean forward and sit on the edge of their chairs and be a bit more responsive. So from those observations, we felt that it was important to get as many members as possible.
Catherine Kerr: I would say that was one of our very first lessons, that if you were going to save the Bay, you had to have the support, and you had to educate the politicians. And the second thing was that you couldn’t educate them or get their support without facts. So we spent a great deal of time on collecting facts and then educating everybody that would listen.
Esther Gulick: Also, the fact that we were getting members was very important. Because they listened to how many members we had and how many letters they got.
Sylvia McLaughlin: Our members were very responsive. We would suggest that they attend critical city council meetings and they would. Sometimes the following city council meeting would be wall to wall with chamber of commerce people. It went back and forth like that.
[music]
Sasha Khokha: Ultimately, the will of Bay Area residents trumped the aspirations of developers. In 1963, the Berkeley city council rescinded the plan to fill in the Bay from the city’s waterfront master plan. It was a big victory for city residents. And it would change Berkeley and the larger Bay forever. But with dozens of fill plans still pending on the dockets of other cities, the three Berkeley activists knew something had to be done in Sacramento to really save the Bay across the region. That opportunity came the following year when Kay Kerr was able to secure a meeting with state Senator Eugene McAteer.
[music]
A San Francisco native, McAteer was a powerhouse in Bay Area politics. He had served on the San Francisco board of supervisors throughout most of the 1950s before heading to the state senate in 1958. He quickly established himself in the legislature. He was close friends with fellow San Franciscan, Governor Edmund “Pat” Brown, and fostered good working relationships with the leadership of both houses. Like most California politicians of that era, McAteer was a builder and supported a range of development and state infrastructure projects, from freeways and universities to dams and other water projects. He also had a calculating eye when it came to climbing the political ladder. And he could tell that the Bay issue was a significant one for the state. He’d seen the legislature stall over the issue before. So, following his meeting with Kay Kerr, he proposed a different tact: a study commission on regulating bay development.
Joseph Bodovitz became one of the planners to lead that study. After an early career as a reporter for the San Francisco Examiner, Bodovitz worked for many years with the San Francisco Bay Area Planning and Urban Research Association, also called SPUR. In his oral history, he explained how Eugene McAteer’s involvement in the issue of bay regulation was both novel and key to why the plan succeeded
Joseph Bodovitz: I think what people tend to forget now is how unusual it was to have anybody of McAteer’s stature interested in an environmental issue in the sixties. It would be common now, but part of what was intriguing about it at the time was, here was a person who had not been identified with environmental causes at all, part of the establishment in the state senate, suddenly taking up a brand-new and obviously glamorous, important kind of issue. But, here was a big issue brought by conservationists for a couple of years, and here was the legislature not wanting to legislate. There was no consensus that would have let a bill pass. Yet, here was somebody with the power of McAteer able to say, “Well let’s have a study commission.” And McAteer obviously had enough clout with the governor and with both houses to get a relatively simple thing like that through. But as I say, the kind of political novelty of a McAteer being involved in a “do-gooder”, “posy-plucker” issue just made it a different kind of issue. I don’t know what would be a good example, like Ronald Reagan really being serious about protecting redwoods or something.
Sasha Khokha: The study bill that the legislature passed in 1964 gave McAteer’s team four years to develop a plan and show it could work. Their plan focused on three areas. First, a permit process for all proposed development and land use changes on the Bay. Second, a set of standards and criteria to judge the permit applications. Third, the development of an appointment commission that would hold monthly public hearings and decide on the applications. In the end, McAteer’s study group created what became known as the San Francisco Bay Conservation and Development Commission, or BCDC.
These were uncharted waters. There was no precedent for this kind of environmental regulation back in 1965. In fact, BCDC was the first regulatory agency of its kind in the nation. For Joe Bodovitz, the chief architect of the Bay commission plan, this meant that the pressure was on and the clock was ticking.
Joseph Bodovitz: And here was the hand we were dealt in 1965: a temporary commission. Which means if you don’t score a touchdown, then the ballgame is over. Right? You don’t go on forever, so you don’t have the luxury of permanence. The goal was, “Let’s do something that will be the basis for successful legislation in 1969, that will both protect the Bay and encourage the kind of shoreline development you want to have. If you’ve shown, over the four years, that people were fairly treated; and that rational, necessary development was encouraged, not discouraged; and that the valuable bay-fill-in parts of the Bay were protected or whatever, you make a case for continuing. And finally, because the people that oppose you are going to be very strong, very well-financed and all, you have to maintain the public support that got the whole thing started. If you lose that, you’ve got nothing. You’ve got a plan and nobody who cares.
[music]
Sasha Khokha: While Bodovitz crafted the Bay plan and served as executive director of the commission’s staff, the operation of BCDC rested in the hands of founding chairman, Melvin B. Lane. Lane was the publisher of Sunset magazine. He fit the balanced approach McAteer and others envisioned for the new regulatory agency. He was a Republican and a successful businessman who could speak with authority to developers and real estate interests. At the same time, he was an environmentalist whose magazine had long celebrated the beauty of California and the West, and the importance of preserving natural lands. As Lane recalls in his oral history, he approached regulating bay development with a handful of basic policy concepts.
Melvin B. Lane: One of them was that, you don’t put something in the Bay that can just as well go on land. The next one was, you don’t put something next to the Bay that can just as well go inland. And that covered an awful lot of things. A house doesn’t have to be in the Bay, a yacht harbor does. [laughs] You know? So, if there’s a choice, okay, the things that are water-related get a priority over these others. Things that the general public can enjoy will get preference over things that just a limited group can enjoy. The things that a limited group of people can enjoy will get a preference over the something that only is for a single person, or a single owner. There are a lot of industries that need to be in the Bay, but if you fill it up with houses and warehouses, you don’t leave room for those things that really have to be there.
Sasha Khokha: Lane talked about how BCDC took a perspective very different from the view of a city council or a developer.
Melvin B. Lane: I think looking at the resource, and what we thought it should be one hundred years from now, took priority over what somebody could do to make a short-term profit. One of the big theories I came out of it with is called “salami logic.” It’s very true, in my opinion, that if you look at a slice, you see something very different than if you look at the whole loaf. If somebody owns a piece of shoreline and some mud flats, and they go to the city council and they say, “Now I just want to fill in a little bit out here to help my building, but I’m going to put a little path around here, and there’s a picnic table. And I’ve got this architect that’s going to put ivy on my building, and I’m going to create fifty jobs, and I’m going to pay you twenty thousand a year in taxes, and on and on. And, I’ve only taken .0007 per cent of the bay.” A city council can’t turn that down. But if you looked at all of the privately-owned shallow parts of San Francisco Bay and said, “Now if this happens to even a large part of it, was that a good idea?” We’d say, “No.” If you looked at that one slice, you’d say, “Yes.” So as planners, we should be looking at the total, but a developer looks at only his thing.
Sasha Khokha: Operating a commission that actually rejected permits for multi-million-dollar developments wasn’t easy. Almost immediately, BCDC found itself squaring off against all kinds of Bay Area business interests.
Melvin B. Lane: At the time BCDC was created there were some firms who were fighting it extremely hard, and they’d fought McAteer all the way through on the legislation. One of those certainly was Leslie Salt.
Sasha Khokha: Leslie Salt Company was the largest landowner on the San Francisco Bay, operating 26,000 acres of salt ponds at the southern tip of the Bay. By the time BCDC was created, however, this company was looking to develop large portions of their property as commercial and residential real estate. BCDC rejected the proposal. And that was a decision that impacted Mel Lane both personally and professionally, since he knew the family that owned Leslie Salt.
Melvin B. Lane: Aug Schilling, the president, was a friend of my family and my wife’s family. And they were a customer of my company. No, how do I say that? They bought things from us [laughs]. Or at least we were trying to sell them both advertising in our magazine, and one of the companies they owned was Spice Islands, and we published a book for Spice Islands. They were our biggest single customer in book publishing for a period of years right in the middle of all this fighting. So anyway, I knew them. They had decided a couple of years before BCDC came into being, that they were going to start making money on their real estate, because they were never going to do it in the salt business. So, they were off on these grandiose plans for filling in all the salt ponds, and therefore were scared to death of BCDC, as they should have been. And so, we did fight and scratch with them, and anything we ever had in Sacramento they were right there.
Sasha Khokha: We don’t know if Aug Schilling thought his company’s permit would get preferential treatment because he knew Mel Lane. But he didn’t hide his disdain for the new agency regulating development in the Bay. After the decision, he referred to BCDC as “a bunch of Fabian socialists.”
BCDC also battled corporate giants, including US Steel and Castle & Cooke, better known by its two subsidiaries, C&H Sugar and Dole. The two companies proposed large fill projects on either side of the historic Ferry Building in downtown San Francisco. US Steel wanted to build an office complex in the harbor that would have included a 550-foot skyscraper, a structure more than twice the size of the Ferry Building’s clock tower. Castle & Cooke’s project was even more ambitious. They had an idea for something called Ferry Port Plaza, a 42-acre fill that would house a hotel and an assortment of restaurants and shops. The footprint of the proposed plaza would have been 30% larger than Alcatraz Island. BCDC rejected both projects. And that sparked a bitter fight not just with the companies, but also their allies in City Hall, including Mayor Joseph Alioto.
Melvin B. Lane: Well, they wanted to put some big office buildings out in the Bay. And we did fight them on that, and everybody else took credit for it. But that U.S. Steel and Castle & Cook big building, we were the ones that stopped those. And they would have had those, because they had the city politics of San Francisco under control, and Alioto was right in the middle of it. We had awful fights with Joe Alioto over them.
Sasha Khokha: One of the more audacious proposals BCDC faced in its early years, was called the West Bay Project. It was backed by a real estate consortium that included David Rockefeller, Crocker Land company, and Ideal Cement. They wanted to fill in part of the Eastside of the Peninsula running from San Bruno to the San Mateo Bridge. Mel Lane recalls how the plan sought to remove 250 million cubic yards of dirt from San Bruno Mountain to fill in 27 square miles of the Bay.
Melvin B. Lane: They would cut down the mountain, push it in the Bay, and go right over Bayshore [Freeway] onto barges and take it down and fill in down there. And then, Rockefeller would put up the money and all the professional skills of planning the land and marketing it. Well, it’s like Candlestick Park, pushing land into the Bay. Developers just love that, God, they think that is so wonderful. Anyway, we finally wore them down, but they were tough and very able.
[music]
Sasha Khokha: In 1969, the California Legislature made BCDC, or San Francisco Bay Conservation and Development Commission, permanent. Sadly, Senator Eugene McAteer did not live to see the final vote. He suffered a fatal heart attack two years earlier. His vision, however—and the bold activism of people like Kay Kerr, Esther Gulick, and Sylvia McLaughlin—became enshrined in a regulatory agency that was the first of its kind in the country.
BCDC becoming an official state agency marked two milestones in the evolution of Bay Area environmentalism. First, it gave environmental considerations a permanent place in state government. Second, the agency aimed to strike a balance between economic development and environmental conservation. Here’s Joe Bodovitz:
Joseph Bodovitz: But see, it worked both ways, because the more development-minded people had to take a look at marshlands, but similarly, the dyed—absolute, if that’s the right term, conservationists, had to understand there was an economy in the Bay Area, and that shipping, after all, did depend on ports, and ports did depend on dredging and deep water access. People sort of had to confront the legitimate interests of both conservation and development. The idea, again, that Mel felt very strongly about is that reasonable, fair-minded people, confronted with facts in a reasonably unemotional way, are going to come out largely agreeing to the same kinds of things. They may disagree on a particular permit or a particular issue, but no fair-minded person can say marshlands aren’t important. Similarly, no fair-minded person can say ports aren’t important to the Bay Area economy.
Sasha Khokha: In fact, in his oral history, Mel Lane talked about exactly this: how what made BCDC historic was its role as government mediator. It created and enforced rules across the Bay; and it occupied a middle ground between activists and developers. Mel Lane said that was core to its mission.
Melvin B. Lane: I have a theory I inherited from Dave Brower actually. And that is, that environmentalists should be extremists. They represent an extreme, and the people who are going to make a buck represent the other one, and the decision-maker should sweat it out in the middle. These battles are ones that you don’t solve them ever, with the coast or bay or air or water or whatever it is, because tomorrow there is another group of citizens and voters and government leaders, so those battles just go on forever.
[music]
Sasha Khokha: What began with the activism of three women in Berkeley, and a brave proposal from a state senator, flourished into an environmental agency whose impact would be felt for decades to come. The work of BCDC certainly saved San Francisco Bay. It also helped bolster a rising tide of conservation that, in time, led to the creation of similar state regulatory agencies, like the Tahoe Regional Planning Agency, the Delta Stewardship Council, and the equally historic California Coastal Commission, which both Joe Bodovitz and Mel Lane would also help steer in its formative years.
Yet, as the 20th century continued, the Bay Area once again found itself at a crossroads. Yes, environmental concerns now had a permanent place in government, but not everyone received equal treatment. Our next episode of Voices for the Environment explores how the disproportionate impact of pollution on communities of color led to calls for environmental justice.
You’ve been listening to “Tides of Conservation,” the second episode in the podcast for Voices for the Environment: A Century of Bay Area Activism. It’s an exhibition in The Bancroft Gallery at UC Berkeley that runs from October 2023 through November 2024. This segment featured historic interviews from the Oral History Center archives in The Bancroft Library at UC Berkeley. Interviews include Esther Gulick, Catherine “Kay’ Kerr, Sylvia McLaughlin, Joseph Bodovitz and Melvin B. Lane. To learn more about these interviews and the Oral History Center, visit the website listed in the show notes. This podcast was produced by Todd Holmes and Roger Eardley-Pryor, with help from me, Sasha Khokha. Thanks to KQED Public Radio and The California Report Magazine. I’m your host, Sasha Khokha. Thanks for listening!
End of Podcast Episode 2: “Tides of Conservation.”
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of all the work we do, including for each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Listen to podcast episode 1, “A Preservationist Spirit,” or read a written version of this podcast episode below.
Podcast Episode 1: “A Preservationist Spirit” is part of the Voices for the Environment exhibition in The Bancroft Library Gallery
Voices for the Environment: A Century of Bay Area Activism is a gallery exhibition in The Bancroft Library that charts the evolution of environmentalism in the San Francisco Bay Area through the voices of activists who advanced their causes throughout the twentieth century—from wilderness preservation, to economic regulation, to environmental justice. The exhibition is free and open to the public Monday through Friday between 10am to 4pm from Oct. 6, 2023 to Nov. 15, 2024, in The Bancroft Library Gallery, located just inside the east entrance of The Bancroft Library. Curated by UC Berkeley’s Oral History Center, this interactive exhibit is the first in-depth effort to showcase oral history along with other archival collections of The Bancroft Library.
This exhibition includes three podcast episodes that offer deeper narratives to supplement the archival posters, pamphlets, postcards, photographs, oral history recordings, and film footage that are also presented in the gallery. Please use headphones when listening to podcasts in The Bancroft Library Gallery.
A written version of podcast episode 1 is included below.
Listen to episode 1: “A Preservationist Spirit” on SoundCloud.
Episode 1: “A Preservationist Spirit.” This podcast episode accompanies a section of the Voices for the Environment exhibition that explores how, after the 1906 San Francisco earthquake and fire, demands to rebuild San Francisco targeted the state’s ancient and fire-resistant redwood trees, while desires for a reliable water supply called for damming the Hetch Hetchy Valley within Yosemite National Park. In the decades that followed, an outpouring of activism shaped the ensuing conflict between economic development and environmental protection, and fueled a preservationist spirit in the Bay Area that would only grow over the century.
This podcast episode features historic interviews from the Oral History Center archives in The Bancroft Library at UC Berkeley, including segments from the “Growing Up in the Cities” collection recorded in the late 1970s by Frederick M. Wirt, as well as oral history interviews with Carolyn Merchant recorded in 2022, with Ansel Adams recorded in the mid-1970s, and with David Brower recorded in the mid-1970s. The oral history of William E. Colby from 1953 was voiced by Anders Hauge, and the oral history of Francis Farquhar from 1958 was voiced by Ross Bradford. This episode also features audio from the film Two Yosemites, directed and narrated by David Brower in 1955. This episode was narrated by Sasha Khokha of KQED Public Radio and The California Report Magazine.
This podcast was produced by Todd Holmes and Roger Eardley-Pryor of the Oral History Center of The Bancroft Library at UC Berkeley, with help from Sasha Khokha of KQED. The album and episode images were designed by Gordon Chun.
WRITTEN VERSION OF PODCAST EPISODE 1: “A Preservationist Spirit”
Anonymous Witness 1: The older people were running around wild! They thought it was the end of the world. Everything was shaking.
Anonymous Witness 2: Kind of a low roar. You had the feeling that the roof was coming off.
Anonymous Witness 3: It was a six-story brick building. We were on the third floor. When we finally got out of the building, we were on the top floor. The top three had gone off.
Anonymous Witness 2: By night the city was—it looked like the whole downtown area was on fire
Anonymous Witness 1: Everything was burned, you couldn’t—the home was gone. Everything was gone.
Sasha Khokha: Those are voices of people who survived the 1906 San Francisco earthquake and fire. And they’re just some of the rare recordings you’re going to hear in Voices for the Environment: A Century of Bay Area Activism.
[music]
This podcast accompanies an exhibition in The Bancroft Library at UC Berkeley that’s the first major effort to bring together both the oral history and archival collections of The Bancroft Library. You’re about to hear more voices recorded by UC Berkeley’s Oral History Center, founded in 1953 to record and preserve the history of California, the nation, and our interconnected world.
Voices for the Environment traces the evolution of environmentalism in the San Francisco Bay Area across the twentieth century, and highlights how Bay Area activists have long been on the front lines of environmental change—starting with efforts to preserve natural spaces in the wake of the 1906 San Francisco earthquake and fire. We’ll also learn about the midcentury fight for state environmental protections, and demands to address the disproportionate burden of pollution that sickened communities of color across the Bay.
You’re listening to the first episode of Voices for the Environment. We’re calling it “A Preservationist Spirit.” I’m your host, Sasha Khokha, from KQED.
[music]
Sasha Khokha: A beautiful vista, an ancient forest, a flooded valley. Our relationships with the world around us define who we are, from the air and water that sustains us, to the natural spaces we enjoy, to the creatures we share our surroundings with. Together, we refer to these intertwined elements as “the environment.” Sometimes we struggle with how to change those relationships. We call that work “environmentalism.”
[piano music from the early twentieth century]
In the San Francisco Bay Area, a new environmental spirit was flourishing in the first decade of the twentieth century. The catalyst for this public activism was not pollution, oil spills, or climate change. Not yet. Back then, it was the 1906 earthquake and fire.
On the morning of April 18, 1906, a massive earthquake struck just two miles off the coast of San Francisco, then California’s largest city. The quake, with an estimated magnitude of 7.9, was absolutely devastating. Thousands of buildings crumbled to the streets, reducing vast sections of the city to rubble. The recordings you’re about to hear are rare, firsthand accounts of people from the Bay Area who survived the harrowing event. These interviewees were children back in 1906, and they recounted their experiences decades later.
Anonymous Witness 5: I was ten years old, I’d just had a tenth birthday, but I had never heard of an earthquake, I didn’t know the word.
Anonymous Witness 6: We woke up. It’d shake, shake you right out of bed, but we couldn’t get out. The house boxed and the doors jammed, and we had a heck of a time.
Anonymous Witness 5: My mother got us into the doorway and stood us there. And she said, “now stand right here.” And she stood us right in the doorway, “Stand right here.” I said, “Well, what is it?” And we could look across the room and out the building and see the buildings collapsing out there.
Anonymous Witness 1: But when the earthquake came in 1906, the day of it, my mother had a baby girl on that morning. She was ill all evening, all night. The earthquake was so strong that, we lived on the first floor, and on the third floor, the balcony and everything fell down. And fire, our kitchen caught fire, there was my father. So finally, the people—there was a little Irish lady who lived next door with her two young sons, I think they were seventeen and nineteen at that time. Her sons broke the windows and took mother, the mattress, baby and all, brought them outside on the sidewalk. I remember that like yesterday.
Anonymous Witness 3: We were four people living in one large room in what was called the Old Supreme Court Building, which was diagonally situated across or located across from the City Hall. Larkin and McAllister Streets. It was a six-story brick building. We were on the third floor. When we finally got out of the building, we were on the top of it. The top three had gone off.
Anonymous Witness 2: So my father said, “You’ve got to get up. You’ve got to get up and dress.” First thing, we went out in the street and you could smell gas. People were all out of their homes in their pajamas and their nightshirts, and so forth, wanted to see what’s happening. Well, it wasn’t too later in the morning when we fully dressed and went out and down the street. And the street car on Geary [Street], the rails were all up in the air and bent. Big gaps, you didn’t, couldn’t—you wondered how far down it went, big gaping holes.
Anonymous Witness 5: And we watched people go by with empty bird cages, and wheeling empty baby buggies, and you know, in a state of complete shock.
[sound effect: fire bell ringing]
Sasha Khokha: As devastating as the earthquake was for San Francisco, it was fire that caused most of the damage. The quake ruptured gas main all throughout the city, sparking nearly three dozen fires, producing an inferno that burned for three-days straight. To make matters worse, firefighters and residents in San Francisco soon ran out of water.
Anonymous Witness 2: And then, about Noon time, we got word that city’s on fire and there’s no water
Anonymous Witness 1: We didn’t have a stitch of clothes on, just an up-top shirt, couldn’t get anything. He went back, thinking he’d be able to save something. Everything was burned, you couldn’t—the home was gone. Everything was gone, so we didn’t.
Anonymous Witness 5: We had gotten some blankets from my aunt. And of course, we went out with nothing from our building except what we were wearing. And we got some blankets from my aunt, and we slept in that—we stayed in that lot. That’s my first recollection of the fire, because from there we could watch everything burn.
[sound effect: dynamite demolition explosions]
Sasha Khokha: No water and a raging fire left city officials only one option: to create fire blocks by dynamiting the buildings that stood in the fire’s path so there would be nothing left to burn.
Anonymous Witness 5: We watched them blast down on Valencia Street and down on Mission Street, sort of backfiring, watched them blast the old theater out there, the Valencia Theater. We slept under the blankets that night, and had to wake every once in a while and shake them because they were heavy with ashes.
Anonymous Witness 4: I recall going to where the Mint is today to watch the fire from where the Mint is on that hill. We could see the fire burning downtown from there on Baker.
Anonymous Witness 2: There’s the school up—it’s right up the hill here—the Lone Mountain College. It was a bare hill at that time, that’s where the name Lone Mountain came to be. So, we walked up there, and by night the city was—it looked like the whole downtown area was on fire.
Anonymous Witness 6: Mr Shields had an automobile, he was the third neighbor to us. So we went down on Market Street. Here was the Palace Hotel, and we were here. And we saw the windows go boom-boom from the heat.
Sasha Khokha: Here’s more recollections of what became known as the Great Fire of 1906.
Anonymous Witness 7: We could see the flames, the fire, from the hills that were burning, all the houses. And the Fairmont Hotel was being built at the time, and it wasn’t finished. And the fire was all around there, but I don’t think it did that much damage there. But just like it was over the sky above us.
Anonymous Witness 2: I can recall the first night when the city was on fire, saying nothing, just staring there next to my father. And I cried and cried. He finally looked down at me and he says, “Well, what can you do about it?” I said, “There goes San Francisco.”
Sasha Khokha: When the last fire was finally extinguished, San Francisco lay in ruins. The earthquake and fire had claimed over 3,000 lives and destroyed 80 percent of what was then the largest and richest city west of Chicago. Within weeks, the mission to rebuild San Francisco got underway.
What you may not know is that the plan to rebuild involved cutting down some of California’s ancient redwood forests. Coastal redwood trees (known scientifically as Sequoia sempervirens) are among the largest and oldest organisms living on Earth. They’ve survived along California’s coast for at least 20 million years, some of them reaching more than 300 feet high and twenty feet wide. That giant size made them a prime timber source to rebuild the devastated city, especially because redwood is pretty fire resistant.
That started a logging frenzy. Timber interests like the Redwood Car Shippers Bureau circulated promotional photos showing buildings constructed out of redwood still standing amid a burned-out San Francisco skyline. [sound effect: sawing wood] In the years that followed, lumber mills up and down the coast worked overtime to meet the city’s endless demand. And record shipments of redwood made their way to San Francisco Bay.
And here’s where the earthquake and fire led to an early call for environmental preservation. Bay Area residents, including John Muir and other members of the newly formed Sierra Club, spearheaded the effort to stop logging redwoods. Muir was an immigrant from Scotland who fell in love with the Sierra Nevada. In the late 1800s, he settled in the Bay Area city of Martinez. In 1892, he and other Bay Area residents founded the Sierra Club with an early mission to explore, preserve, and protect California’s mountains and forests. They feared the logging frenzy to rebuild San Francisco had already taken its toll on the region’s redwoods.
Take the area around Palo Alto. Located 30 miles south on the peninsula, the city got its name from surrounding redwood forests. Palo Alto means “tall tree” in Spanish. In the years after the earthquake and fire, that reference would be lost though, because rebuilding San Francisco depleted those “tall tree” forests.
Concerned residents throughout the Bay Area reacted quickly. They started lobbying the state and federal government to protect the region’s remaining redwood groves. State officials responded by expanding the boundaries of Big Basin Redwoods State Park in the Santa Cruz mountains. It’s California’s first and oldest state park, founded in 1902. Over the decades, the protected area of Big Basin would steadily expand to include some 18,000 acres. That’s 6 times as big as the park’s original boundaries.
Federal officials took action to preserve the redwoods, too. In 1908, Bay Area Congressman William Kent led the charge to federally protect 295 acres of redwood forest in Marin County, just north of San Francisco. The preserved area is known as Muir Woods National Monument. Here’s what John Muir wrote to Kent shortly after the Monument’s creation: “Saving these redwoods from the axe and saw, from money-changers and water-changers, and giving them to our country and the world is in many ways the most notable service to God and man I’ve heard of since my forest wandering began.”
John Muir and other men became figureheads of environmental preservation. But women played a critical—yet often overlooked—role in early environmental activism, too. Women provided much of the grassroots momentum to save California’s redwoods through letter writing, lobbying, fundraising, and leading various organizations. Women in the Sempervirens Club and California Club were instrumental to the creation of protected areas like Big Basin Redwoods State Park, Muir Woods National Monument, and Calaveras Big Trees State Park. The creation of these protected areas forced timber companies to concentrate their operations in more remote regions along the North and Central coasts. But the activists in women’s organizations, from the California Federation of Women’s Clubs to the Women’s Save the Redwoods League, kept pushing to protect those regions, too.
Men may have cast the votes in congress and state government to protect redwood forests, but it was the activism of women throughout California that helped put these issues on the table in the first place. Here’s UC Berkeley environmental historian Carolyn Merchant:
Carolyn Merchant: Women had power, but they had power through their roles in a traditional patriarchal society, so that they could do more things within that patriarchy than had been thought of before. And so women began to feel a sense of power, a sense of what they could do. And they can actually assert that power in order to help save the planet, and how women themselves can become important forces in the whole role of conservation and resources.
Sasha Khokha: The tug-of-war between the development of cities like San Francisco and preservation of California’s redwood forests—that was a fight that would continue for decades, putting the focus on humans, rather than fire or pests, as the primary threat to these ancient trees and their environments. This battle helped ignite and expand the preservationist spirit that would shape environmental activism in the Bay Area for the next century.
[music]
San Francisco had long impacted environments well beyond its city boundaries. In the wake of the 1906 earthquake and fire, the city’s efforts to rebuild began to affect more remote regions of the state, including areas previously protected by preservationists. And as rebuilding San Francisco continued, the city began to need not just trees, but water.
In 1908, city leaders proposed a project to provide a reliable water source for San Franciscans. The scale of the idea was unprecedented. They wanted to dam the Hetch Hetchy Valley, which was then preserved as part of Yosemite National Park. The plan was to engineer a system to carry the water 160 miles to San Francisco—what used to be a 2 day stagecoach ride before the Yosemite Valley Railroad opened in 1907.
The proposal to dam Hetch Hetchy sparked a five year debate, from San Francisco city hall to the steps of congress in Washington DC. The preservationists who opposed the dam were led by John Muir and other Sierra Club officials. They argued Hetch Hetchy Valley was a sacred piece of Yosemite National Park. If it were sacrificed to bring water to San Francisco, that would set a dangerous precedent for tapping into resources in all kinds of protected areas.
William E. Colby: Another outstanding matter that came before the Sierra Club for action, and John Muir was strongly behind it, was what we refer to as the Hetch Hetchy fight. The Hetch Hetchy Valley had been included in Yosemite National Park largely as a result of John Muir’s efforts.
Sasha Khokha: That was Anders Hauge [How-gee] reading the oral history of William E. Colby, who stood on the frontlines with John Muir during the Hetch Hetchy campaign. Colby, who was born and raised in the Bay Area, held the post of Secretary of the Sierra Club for more than forty years. He led campaigns to expand Sequoia National Park, as well as create Olympic and Kings Canyon National Parks. Here is Hauge again reading from Colby’s 1953 oral history about how he cut his political teeth in the fight to keep Hetch Hetchy preserved.
William E. Colby: San Francisco became interested in acquiring this as a municipal water supply. When we heard of it, of course John Muir was tremendously exercised to think that a great part of his work would be undone. And so the Sierra Club very strongly opposed this application by the city of San Francisco. We were successful in preventing the grant for a number of years.
Sasha Khokha: But city developers pushed back. Creating a viable water supply? That was progress. It would help bring fresh water to a thirsty city. Developers also drew heavily on the imagery of a vulnerable San Francisco left without water in the face of a raging fire. The 1906 earthquake and fire was the first natural disaster captured on film. So advocates for the dam had lots of material to help make their case.
William E. Colby: But the tide turned when Woodrow Wilson became president, because he named Franklin K. Lane, who had been City Attorney of San Francisco when the application for the Hetch Hetchy site had been made, Secretary of the Interior. Because of this change in the political situation, we found that we were at a great disadvantage. We had tremendous support from many sources. But this political change was too powerful for us. We even enlisted the support of civil engineers, hydraulic engineers, who aided us in preparing reports showing that there were half a dozen other sources of supply that San Francisco could have obtained. And that was absolutely demonstrated later on by the fact that Oakland went over to the Mokelumne River and obtained a very fine water supply and brought it into Oakland long before San Francisco got the Hetch Hetchy supply. We were handicapped in every direction.
Sasha Khokha: In the end, Congress sided with the city of San Francisco, passing the 1913 Raker Act, which permitted the flooding of the Hetch Hetchy Valley in Yosemite. And the construction of the massive O’Shaughnessy Dam, with an extensive water-delivery system. Colby recalled in his 1953 oral history how this decision impacted his friend and mentor, John Muir.
William E. Colby: The loss of Hetch Hetchy Valley was a tremendous blow to John Muir. I’m quite sure that this loss of the Hetch Hetchy Valley had a great deal to do with Mr. Muir’s subsequent Illness and ultimate death. He probably died in advance of the time that he would have if the attempt to save Hetch Hetchy had not gone against him. Muir didn’t mince any words in expressing his ideas of the tremendous loss to the nation by reason of the flooding of Hetch Hetchy Valley.
Sasha Khokha: John Muir died in December of 1914 – one year after congress voted to authorize San Francisco’s plan to dam the Hetch Hetchy Valley.
[piano music]
Decades later, native San Franciscan and famed photographer Ansel Adams shared his grief over the loss of Hetch Hetchy. Adams joined the Sierra Club shortly after Muir’s death and would build his career photographing Yosemite National Park.
Ansel Adams: We lost the Hetch Hetchy. And one of the great disappointments there was Gifford Pinchot’s support of it. You see, he really turned the trick with the secretary of the interior.
Sasha Khokha: Gifford Pinchot as America’s first professionally trained forester. From 1898 through 1910, he served three American presidents in the US Department of Agriculture as the nation’s chief of forestry. He also became a major supporter of damming the Hetch Hetchy Valley. If John Muir became a figurehead for the preservation of nature, Pinchot’s early leadership of the US Forest Service symbolized the corporate and multi-use model of natural resources.
Ansel Adams: People forget the Forest Service is primarily a commercially oriented, really, a controlling administration. It’s just recently that they’ve been stressing “many uses” for political reasons. It sounds very fine, and in many ways is all right. But when you get into very beautiful areas that should have park or wilderness status, see, it doesn’t work.
Sasha Khokha: As Adams recalls, the Hetch Hetchy site was not just about getting water, but hydroelectricity for the growing city of San Francisco. That would help build the power grid of the utility giant Pacific Gas and Electric, or PG&E.
Ansel Adams: The Hetch Hetchy—where are you going to get your water? In San Francisco, that’s our water supply. And San Francisco, that is a big community. And the Russian River was considered. See, what happened there was that there was another site further down that would be much bigger in expanse but not so deep. And we worked for that very hard, but that could not provide enough power. There wouldn’t be enough “fall.” But the whole Hetch Hetchy was put where it is, in the Hetch Hetchy Valley, because of the favorable power situation.
Sasha Khokha: Some of the defenders of Hetch Hetchy came from San Francisco’s business community, like Francis Farquhar [Far-kwar]. He was a Harvard-educated accountant who joined the Sierra Club a year after moving to San Francisco in 1910. He would serve more than 25 years on the Club’s board of directors, including two terms as Sierra Club president. Here is Ross Bradford reading from Farquhar’s 1958 oral history.
Francis Farquhar: I never participated in the Hetch Hetchy matter. I was in Boston at the time the bill finally passed. I had seen it in 1911 when I came out to the Sierra Club outing with Jim Rennie. We came all the way down the Tuolumne canyon and camped in the Hetch Hetchy Valley a day or two. I recognized its beauty.
Sasha Khokha: For Farquhar, the devastating loss of Hetch Hetchy had a silver lining. Because – although tragic – it may have provided one of the most powerful and lasting influences for what would become the environmental movement in the U.S.
Francis Farquhar: I think that it is too bad that the national park idea had not developed further at the time to prevent the surrender of such an important portion of a national park. Possibly, the fact that Hetch Hetchy was surrendered strengthened the whole national park idea with the slogan, “Never another Hetch Hetchy.”
[music crescendo]
Sasha Khokha: Few activists in America likely used that slogan as effectively as David Brower. Many consider him the godfather of the modern environmental movement. He’s from Berkeley, and served as the first executive director of the Sierra Club from 1952 to 1969. He oversaw a tenfold expansion of the Club’s membership and led campaigns to establish ten new national parks. Brower also pioneered the use of film, books, and other media to advocate for environmental causes. One of those was the fight against a proposed dam on the Colorado River in Dinosaur National Monument.
David Brower: I didn’t go to Dinosaur until 1953. That was the year the Sierra Club started to run river trips that were patterned after a river trip that Harold Bradley had taken his family on the year before. He went there to make a film, and made a family film, and showed around. That was certainly one of the things that awakened my interest in what was there.
Sasha Khokha: When the dam proposal came to congress, Brower and other environmentalists waged an all-out campaign to preserve Dinosaur National Monument.
David Brower: It did—at least it was important to the Sierra Club. It was important to a lot of the conservation organizations, where they could really take on the establishment and stop it. There were all kinds of—that is, whatever led Newton Drury to say, “Dinosaur is a dead duck,” was a force that was reversed, and it was reversed with a battle that had a nationwide audience. And we persuaded a good many of the people whose voices were heard in Congress. They’re a lot of people, but you find a few of the leaders and get them to go, and you’re in fairly good shape.
Sasha Khokha: In his oral history, Brower says the similarity of the dam project in Dinosaur to Hetch Hetchy was striking. He highlighted that parallel in his advocacy film, “The Two Yosemites.”
David Brower: There was one other thing that worked pretty hard, worked well in our lobbying effort. And that was the lowest budget film on record. The one I did on Two Yosemites. The budget was, I guess, five rolls of Kodachrome film and my own time. I did the editing, and I wrote the script, and then I recorded it. We put out this film, it’s an eleven-minute film. We made six copies of it. I showed those in a good many places. And it had quite an impact. That is, what had been done to Hetch Hetchy, and all the claims that were made of how beautiful a lake it would be and how great a recreational resource. Of course, it wasn’t. It isn’t. It wasn’t necessary. And the parallel with Dinosaur was so beautiful that we worked on that constantly.
David Brower in the film Two Yosemites: The other Yosemite was only a little less beautiful than this one, and a few miles to the north: Hetch Hetchy Valley. John Muir, the Sierra Club, and other conservation groups fought hard against this destructive park invasion. San Francisco argued that, without this water, they would wither; it must have this cheap power; there were no good alternatives; and the dam would enhance the beauty of the place and make it more accessible; the greatest good for the greatest number; teeming San Francisco against the few people who had yet visited Yosemite. Not one of the city’s claims has proved valid.
Sasha Khokha: David Brower’s activism, along with efforts of other preservationists, did prove successful. In 1955, the Secretary of the Interior withdrew the proposal for the dam at Dinosaur National Monument. And that campaign was just one of many environmental efforts Brower would lead from Sierra Club headquarters in the Bay Area. By the late 1960s, Brower’s leadership would elevate the Sierra Club’s national profile, transforming it from a California-based group to one of the largest and most influential environmental organizations in North America.
[music]
We’ve heard how a new and bustling San Francisco arose from the ashes of the 1906 earthquake and fire. So did a robust and ever-growing spirit of preservation, a force that would shape environmentalism in the Bay Area, and beyond, for well over the next century. The activism that began to preserve the state’s ancient redwood forests would result in forty-nine state and federally protected redwood parks in California. And the legacy of the Hetch Hetchy fight helped inform the preservation of landscapes across the U.S.—423 federally protected areas to be exact.
Yet, in the middle of the twentieth century, environmentalism in the Bay Area once again found itself at a crossroads.The Postwar development boom forced a choice between protecting the environment and using natural resources to meet the needs of a growing population. You can hear that story in our next episode of Voices for the Environment.
You’ve been listening to “A Preservationist Spirit,” the first of three episodes in the podcast Voices for the Environment: A Century of Bay Area Activism. It’s part of an exhibition in The Bancroft Library at UC Berkeley that runs from October 2023 through November 2024. This episode featured historic interviews from the Oral History Center archives in The Bancroft Library at UC Berkeley. Including segments from the “Growing Up in the Cities Project” recorded by Frederick M. Wirt; and oral history interviews with Ansel Adams, Carolyn Merchant, and David Brower. The oral history of William E. Colby was voiced by Anders Hauge, and the oral history of Francis Farquhar was voiced by Ross Bradford. To learn more about these interviews and the Oral History Center, visit the website listed in the show notes. This podcast was produced by Todd Holmes and Roger Eardley-Pryor, with help from me, Sasha Khokha. Thanks to KQED Public Radio and The California Report Magazine. I’m your host, Sasha Khokha. Thanks for listening!
End of Podcast Episode 1: “A Preservationist Spirit.”
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
Please consider making a tax-deductible donation to the Oral History Center if you’d like to see more work like this conducted and made freely available online. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of all the work we do, including for each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Video clip from Carolyn Merchant’s oral history on the 1970s social contexts for her book The Death of Nature
Professor Carolyn Merchant at UC Berkeley. (Photograph by Robert Holmgren.)
Carolyn Merchant is a Distinguished Professor Emerita of Environmental History, Philosophy, and Ethics at UC Berkeley. Her extensive research and teaching at Cal explored historical relationships between humanity, nature, and science with an ecofeminist focus on Western culture’s domination of nature and women. Throughout her academic career, Merchant published numerous peer-reviewed articles and wrote eleven books, as well as four edited volumes. Her genre-shaping publications—including The Death of Nature: Women, Ecology, and the Scientific Revolution (1980); Ecological Revolutions: Nature, Gender, and Science in New England (1989); Radical Ecology: The Search for a Livable World (1992), among others—influenced various academic fields from Women’s Studies to the History of Science, and from Ethics to Environmental History.
Merchant and I video-recorded seven hours of her oral history over four interview sessions in the spring of 2022. Those recordings resulted in a 132-page transcript that includes an appendix with photographs. Merchant’s full-life oral history not only explored her intellectual and academic career, but also recorded lesser known details from her female-centered childhood, her educational mentors, her personal relationships, and her social activism, all of which shaped her academic research and teaching at UC Berkeley.
Carolyn Merchant in her senior year in Vassar College, Poughkeepsie, New York, 1958.
Merchant was born in 1936, in Rochester, New York, where she and her younger sister were raised by their mother, grandmother, and aunt. Merchant recalled how sharing a home with five strong women taught her that “women could do anything. …That gave me a role model unconsciously to know that I could do anything I wanted to.” As a high school senior in 1954, Merchant became a national top ten finalist in the Westinghouse Science Talent Search. She earned her AB in Chemistry from Vassar College in 1958, studied physics for a year at the University of Pennsylvania, and then, at the University of Wisconsin, Madison, she earned her MA in 1962 and her PhD in 1967 in the History of Science. Her graduate research explored the Vis Visa controversy in the seventeenth and eighteenth centuries over a “living force” in nature, from Gottfried Wilhelm Leibniz to Jean-Baptiste le Rond D’Alembert.
Video clip from Carolyn Merchant’s oral history on learning and teaching the history of science, 1960s and 1970s
During graduate school in Wisconsin, Merchant met and married botanist Hugh Iltis, with whom she had two sons, both of whom later graduated from UC Berkeley. Merchant also began her environmental activism during graduate school, which included lighting Wisconsin prairies on fire as a means to restore native plants and animal habitat. At that time, Merchant first read Betty Friedan’s The Feminine Mystique and Rachel Carson’s Silent Spring, which affected both her life and academic trajectories. In the late 1960s, upon completing her PhD thesis and her divorce from Iltis, Merchant and her sons moved from Wisconsin to Berkeley, California.
Carolyn Merchant in Honolulu, Hawaii, 1967.
Merchant’s life on the west coast provided new opportunities and realizations. While teaching the History of Science as a Visiting Lecturer at Oregon State University, Merchant lived on a Corvallis farm where the runner-up Dairy Queen of the state of Oregon taught her how to milk goats and cows. Merchant’s back-to-the-land experiences would shape her later analysis on utopias and what she described as the “organic society,” from John Salisbury’s organic concept of the state in 1159, to Francis Bacon’s The New Atlantis in 1627. To support herself and her family back in Berkeley, Merchant worked as an adjunct instructor, which she eventually parlayed into a fulltime position. She taught as a Lecturer at the University of San Francisco, where by 1976 she became an Assistant Professor, and she also taught in the innovative, interdisciplinary, yet short-lived Strawberry Creek College program at UC Berkeley.
Throughout the 1970s in the Bay Area, Merchant engaged in feminist, environmental, anti-war, and anti-capitalist politics, which is how she first met UC Berkeley historian Charles Sellers, whom she later married. Over many decades together, Merchant and Sellers advocated for social justice and shared adventures traversing the United States in a camper van while searching for rare birds and visiting far flung archival collections. On the road, Merchant used some of the first laptop computers to draft her eventual publications. Back in the Bay Area, Merchant connected with intellectuals like Theodore Roszak and became a visiting scholar at Stanford’s Center for Advanced Study in Behavioral Sciences. Around that time, Merchant learned from a USF colleague that UC Berkeley planned to hire a professor to work in the then-nascent field of environmental history. “I can do that,” she said to herself, and walked up the hill from her house to campus to submit her application. As she recalled, “when I was interviewed, I was from Stanford, and I was not a local yokel four blocks away in Berkeley where my house actually was.”
Video clip from Carolyn Merchant’s oral history on her hiring at UC Berkeley’s College of Natural Resources, 1980
Carolyn Merchant at her home in Berkeley, California, July 1984.
Women played a central role in Merchant’s research, as well as with her hiring at UC Berkeley in 1979. Merchant applied to the College of Natural Resources for a position in a new department then called Conservation and Resource Studies, which later became the Department of Environmental Science, Policy, and Management. On the hiring committee were five male faculty members and five female undergraduates. Many women took courses in the college, yet the faculty of the College of Natural Resources were still mostly men. After her on-campus interview, Merchant recalled “the students wanted a woman, and they lobbied. …They wanted to understand what role women had played in the environment, and how they used the environment, and how they developed as scientists and environmental scientists. And they liked me because I was interested in pursuing those topics and finding out by digging into the archives who the women were and what they had done.” The first three hires for the new department were all women. In 1980, one year after Merchant joined the faculty at UC Berkeley, she published The Death of Nature: Women, Ecology, and the Scientific Revolution, which remains in print today and has been translated into numerous languages. As Merchant recalled, when the book appeared, “there was a column in Newsweek, and then it was brought up at a congressional hearing. It [my book] was a criticism of what mechanistic science alone would do to the environment if it wasn’t associated with an ethic and some restraints and understanding of what the consequences were. So it was very gratifying to see that reception.”
The majority of Carolyn Merchant’s oral history explores her career as a Professor of Environmental History, Philosophy, and Ethics at UC Berkeley. The topics we discussed ranged from the evolution of Merchant’s research and teaching to her reflections on how the College of Natural Resources has changed over time. Generally, Merchant’s research and teaching examined the history and ethics of science and the environment through the lens of gender. As she noted during her oral history, “gender is so important and so central. Because most of human history, and most of even environmental history and the history of science, has been concerned with the roles that men play. And I want to make the roles that women play and the importance of gender as an equal thing, so that the roles of women are not obscured—and that women and men are equal partners not only in an existing political economy and a social economy, but they are equal partners in every aspect of trying to work together as partners to make the whole planet continue to live on.”
Video clip from Carolyn Merchant’s oral history ongendered reproduction
In her oral history, Merchant also addressed some of the specific, interrelated research themes that she developed throughout her career. One of those themes focused on science and domination, especially Merchant’s attention to impacts on nature as both a mental construct and a physical reality when institutions of science emerged within a patriarchal society. She also spoke about women and nature through the lens of ecofeminism. “Ecofeminism comes from a woman named Françoise d’Eaubonne in France,” Merchant explained. “Ecofeminism asserts the power of women and also their interrelationships with nature, and how women can save nature, and how women themselves can become important forces in the whole role of the conservation of resources.” Merchant discussed her partnership ethic, a contribution she made to environmental ethics in which humans of all genders, along with nonhuman nature, would be valued as equal partners inhabiting a flourishing earth. “Partnership makes nature and humans equal, and interactive, and sharing and giving,” Merchant declared, “and we have to conserve nature if we are going to go ahead and live in the future with an active nature and an active humanity.” In light of her own politics to protect and conserve nature, Merchant also reflected on about the importance of gendered reproduction, and how control of women’s bodies and the unpaid labor of those bodies are essential to the material, social, and cultural maintenance of a capitalist and patriarchal society. In contrast to the modern world’s focus on production, Merchant emphasized the need for reproduction: “allowing the reproduction of nature and its systems to continue is what is going to allow humanity to reproduce itself and to continue. …Because if we don’t allow the natural resources of the world to keep reproducing themselves, if we don’t set aside land or pass laws that prevent us from using everything up, we won’t be able to continue reproduction.”
Carolyn Merchant’s oral history is now available to read online, even as the ever-worsening impacts of climate change create an interrelated set of crises for the Earth and all living organisms on it, including humanity. After her long career teaching and researching environmental topics at UC Berkeley, Merchant admitted, “of course, I’m distressed that we have all the environmental problems that we have now.” Yet, in the face of these crises, she also shared her optimism. “There’s also hope in the sense that there are laws being passed, there are people who are working continuously, and there are new societies and new organizations being formed. So we’re at a tipping point. And hopefully, we’ll go in the direction of conservation, and environmental justice, and environmental reform, and saving the Earth.”
Video clip from Carolyn Merchant’s oral history onher partnership ethic for humanity and nature
Video clip from Carolyn Merchant’s oral history on becoming a national finalist in the Westinghouse Science Talent Search, 1954
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
If you’d like to see more interviews like this conducted and made freely available online, please consider making a tax-deductible donation to the Oral History Center. While we receive modest institutional support, we are a predominantly self-funded research unit of The Bancroft Library. We must raise the funds to cover the cost of each oral history. You can give online, or contact us at ohc@berkeley.edu for more information about our funding needs for present and future projects.
Video clip from Doris Sloan’s oral history on living in the Bay Area, on deep time, and on thinking like a geologist:
Doris Sloan is a geologist and paleontologist who earned her PhD at UC Berkeley and who taught, wrote, and engaged in environmental activism and education throughout the Bay Area, across California, and beyond. Sloan and I recorded nine hours of her then 92-year life history at her home in Berkeley, California, in May 2022. Our four recording sessions resulted in a 162-page oral history volume that includes an appendix of photographs with family as well as documents from her efforts in the early 1960s to stop PG&E’s construction of a nuclear power plant atop Bodega Head, under which runs the seismic San Andreas fault. Today, the coastal outcrop of Bodega Head is preserved as part of California’s scenic 17-mile-long Sonoma Coast State Park.
Doris Sloan in 1963 as the Sonoma County Coordinator of the Northern California Association to Preserve Bodega Head and Harbor (NCAPBHH).
Sloan’s involvement in the “Battle for Bodega Head” helped inspire her later career as a geologist and teacher—a career she began by returning to graduate school as a mother in her early forties with children still at home. Sloan overcame numerous challenges, including gender discrimination in what were then male dominated departments and academic fields, to earn her MS in Geology in 1975 and her PhD in Paleontology in 1981. Her dissertation was an ecostratigraphic thesis on the sedimentary fossils of tiny creatures that once lived the San Francisco Bay. For many years, Sloan taught research-driven senior seminars in Environmental Science at UC Berkeley as well as geology courses for UC Extension. She lectured on travel excursions and field trips around California and across much of the Earth. Sloan became a board member with Save the Bay and a founding member of Citizens for East Shore Parks. In 2006, she published with UC Press the popular California natural history guide, Geology of the San Francisco Region. In her rich oral history, Sloan discussed all of the above, with details on her formative childhood experiences, her environmental and anti-nuclear activism, her experiences as a female geology graduate student at UC Berkeley, as well as her diverse teaching career.
Doris Sloan, age 6 (front center), on a salamander egg collecting trip with father, Viktor Hamburger (right), and two of his graduate students in St. Louis County, Missouri, circa 1936.
Doris Sloan was born in October 1930, in Freiburg, Germany. At age four, she and her family fled Germany after the Nazis removed her father, preeminent embryologist Viktor Hamburger, from the faculty at the University of Freiburg because of his Jewish ancestry. Her family settled in Missouri after her father secured a faculty appointment at Washington University in St. Louis. As a young girl, Sloan accompanied her father and his embryology students on field research trips to collect salamander eggs. She also shared fond memories of youthful summers working in Woods Hole on Cape Cod at the Marine Biological Laboratory. Sloan attended Bryn Mawr College from 1948 to 1951, where she began attending Quaker meetings. Upon her mother’s deteriorating health, Sloan returned to St. Louis and graduated in 1952 from Washington University with a BA in Sociology. In that same year Sloan moved to San Francisco, California, with her then-husband, with whom she had four children. In 1957, she and her young family moved to Sonoma County, where she was neighbors with Peanuts cartoonist Charles Schulz. It was there in Sonoma County where, in the interests of protecting her children from nuclear radiation and preserving the beauty of the Sonoma Coast, that Sloan began her environmental activism that would, among other experiences, inspire her later career as a geologist and teacher.
Video clip from Doris Sloan’s oral history about her role in the “Battle of Bodega Head, Part 1:
Doris Sloan at the now water-filled “Hole in the Head” on Bodega Head on Mother’s Day in 2022. Photograph by her daughter Christy Sloan.
Sloan detailed her engagements in the multi-year “Battle of Bodega Head” that, in 1964, successfully stopped PG&E’s construction of a nuclear power plant on Bodega Head. After being told by an official from California’s Office of Atomic Energy Development and Radiation Protection to let go of concerns about the forthcoming nuclear plant and “leave it to the experts,” Sloan enlisted in the activist organization called the Northern California Association to Preserve Bodega Head and Harbor (NCAPBHH)—a name others created and she described as “dreamt up on a Friday night after too many beers.” The Association included an eclectic mix of anti-nuclear citizen activists that included communist chicken farmers, libertarian land owners, conservative cattle ranchers, Bodega fisherman, UC Berkeley professors, Sierra Club members, and jazz musicians and songwriters. In her role as Sonoma County Coordinator of NCAPBHH, Sloan also collaborated with an internationally recognized geophysicist and geologist named Pierre Saint-Amand. Fortuitously, on a rainy and wind-swept day, Sloan accompanied Saint-Amand on a clandestine and consequential visit to the “Hole in the Head,” the site on Bodega Head where PG&E had already drilled a deep pit into granite rock to place its nuclear reactor. It was on that visit, while looking into that hole, that Saint-Amand and Sloan discovered evidence of the San Andreas fault running directly through the reactor’s containment site, a discovery that eventually halted further nuclear construction there.
Video clip from Doris Sloan’s oral history about her role in the “Battle of Bodega Head, Part 2:
Doris Sloan driving with her children and many helium-filled balloons to a NCAPBHH event at Bodega Head on Memorial Day, 1963. (Original film negative slightly damaged.)
As Sloan recalled about their activist victory in the early 1960s, “to have a group of citizens win out over a major institution was really pretty unique. … Bodega was a very important story at the very beginning of a huge cultural shift for not only environmental matters on nuclear energy, but in so many other ways, too. Basically, citizen involvement at every level, from students to housewives. And to be a part of that, I look back on that and think, wow, how could anybody have been so lucky in so many ways?” The story of this citizen-led anti-nuclear activism has been told elsewhere, including in Oral History Center interviews with David Pesonen and Joel Hedgpeth, as well as by nuclear historians J. Samuel Walker and UC Berkeley alumnus Thomas Wellock. Sloan’s storytelling on her personal role in the “Battle of Bodega Head”—like launching over a thousand helium-filled balloons from Bodega Head to the accompaniment of live jazz playing “Blues Over Bodega”—adds both flourish and important details to the eventual successes of NCAPBHH.
Sloan’s involvement at Bodega Head played a crucial role in launching the next phase of her life as a geologist and teacher. After moving with her children to Berkeley in 1963, Sloan worked for the Friends Committee on Legislation, a Quaker lobbying group. Yet, by the early 1970s, Sloan’s long-standing fascination of nature, a desire to experience more of it, and her memory of discovering fault seams on Bodega Head led her to take UC Extension courses on geology taught high up in the Sierra Nevada’s Emigrant Wilderness by a remarkable UC Berkeley professor named Clyde Wahrhaftig. Wahrhaftig eventually became a significant mentor and friend to Sloan on her academic journey, as were UC Berkeley geologists Garniss Curtis and William B.N. (Bill) Berry. In her oral history, Sloan shares many joys from her field research and academic experiences at Berkeley, including mapping rock formations in California’s Mazourka Canyon, communing with ancient bristlecone pines in the White Mountains, learning about limestone deposition in Florida, a fascinating question about an imaginary dinosaur civilization from Walter Alvarez during her PhD oral examination, and her own work deciphering the sedimentary mysteries of fossils from mud under the San Francisco Bay. Sloan also shared some of the challenges she faced in the late 1970s as one of the few women in Berkeley’s geology and paleontology departments that, by her account, then included more than a few male chauvinistic dinosaurs.
Video clip from Doris Sloan’s oral history about Clyde Wahrhaftig, a UC Berkeley geologist, mentor, and friend:
Doris Sloan lecturing during a University of California Museum of Paleontology (UCMP) field trip to the Marin Headlands in 2010. Photograph by John Karachewski.
Sloan’s oral history also explores her ensuing years as a teacher, travel guide, author, and environmental activist. Sloan discussed several senior research seminars in Environmental Studies that she taught at UC Berkeley, some records of which are preserved in UC Berkeley’s Library including East Bay Parklands: Planning and Management (1978), Seismic Safety in Berkeley (1979), San Pablo Bay: An Environmental Perspective (1980), and Hazardous Substances: A Community Perspective (1984). Sloan recorded stories and samples from lectures she delivered in her UC Extension geology courses and in her field classes for numerous organizations, including the Oakland Museum, Sierra Club, the Point Reyes National Seashore Association, and the Yosemite Association. And she shared some of her travel experiences as a guide for Cal Alumni groups on journeys all across the Earth, from the Himalayas to Central Asia, and from South America to Scandinavia. Sloan also spoke about her local environmental activism as a board member of Save The Bay, as a founding member of Citizens for East Shore Parks, and on her friendship with Save The Bay co-founder Sylvia McLaughlin, including efforts to secure what is now named as McLaughlin Eastshore State Park.
Doris Sloan’s enlightening oral history records marvelous stories from the first ninety-two years of her remarkable life—from fleeing Nazi Germany to summers in Woods Hole; from raising children in northern California to stopping construction of a nuclear power plant on the San Andreas fault; from graduate school in her forties at UC Berkeley to lecturing across California and much of the world. I am honored to have become one of Doris’s friends, and I’m lucky for the opportunity to become one of her students. Now, with the publication of Doris Sloan’s oral history, you also have the chance to learn from her deep wisdom and experience.
Video clip from Doris Sloan’s oral history about the Bay Area’s complicated geology:
Doris Sloan with oral historian Roger Eardley-Pryor at her home in Berkeley, California, in May 2023.
ABOUT THE ORAL HISTORY CENTER
The Oral History Center of The Bancroft Library preserves voices of people from all walks of life, with varying political perspectives, national origins, and ethnic backgrounds. We are committed to open access and our oral histories and interpretive materials are available online at no cost to scholars and the public. You can find our oral histories from the search feature on our home page. Search by name, keyword, and several other criteria. Sign up for our monthly newsletter featuring think pieces, new releases, podcasts, Q&As, and everything oral history. Access the most recent articles from our home page or go straight to our blog home.
































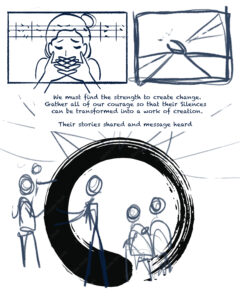




















 Carolyn Merchant’s oral history is now available to read online, even as the ever-worsening impacts of climate change create an interrelated set of crises for the Earth and all living organisms on it, including humanity. After her long career teaching and researching environmental topics at UC Berkeley, Merchant admitted, “of course, I’m distressed that we have all the environmental problems that we have now.” Yet, in the face of these crises, she also shared her optimism. “There’s also hope in the sense that there are laws being passed, there are people who are working continuously, and there are new societies and new organizations being formed. So we’re at a tipping point. And hopefully, we’ll go in the direction of conservation, and environmental justice, and environmental reform, and saving the Earth.”
Carolyn Merchant’s oral history is now available to read online, even as the ever-worsening impacts of climate change create an interrelated set of crises for the Earth and all living organisms on it, including humanity. After her long career teaching and researching environmental topics at UC Berkeley, Merchant admitted, “of course, I’m distressed that we have all the environmental problems that we have now.” Yet, in the face of these crises, she also shared her optimism. “There’s also hope in the sense that there are laws being passed, there are people who are working continuously, and there are new societies and new organizations being formed. So we’re at a tipping point. And hopefully, we’ll go in the direction of conservation, and environmental justice, and environmental reform, and saving the Earth.”




