Tag: archives
Library Leaders Forum 2016

On October 26-28, I had the honor of attending the Library Leaders Forum 2016, which was held at the Internet Archive (IA). This year’s meeting was geared towards envisioning the library of 2020. October 26th was also IA’s 20th anniversary. I joined my Web Science and Digital Libraries (WS-DL) Research Group in celebrating IA’s 20 years of preservation by contributing a blog post with my own personal story, which highlights a side of the importance of Web preservation for the Egyptian Revolution. More personal stories about Web archiving exist on WS-DL blog.

In the Great room at the Internet Archive Brewster Kahle, the Internet Archive’s Founder, kicked off the first day by welcoming the attendees. He began by highlighting the importance of openness, sharing, and collaboration for the next generation. During his speech he raised an important question, “How do we support datasets, the software that come with it, and open access materials?” According to Kahle, the advancement of digital libraries requires collaboration.

After Brewster Kahle’s brief introduction, Wendy Hanamura, the Internet Archive’s Director of Partnership, highlighted parts of the schedule and presented the rules of engagement and communication:
- The rule of 1 – Ask one question answer one question.
- The rule of n – If you are in a group of n people, speak 1/n of the time.
Before giving the microphone to the attendees for their introductions, Hanamura gave a piece of advice, “be honest and bold and take risks“. She then informed the audience that “The Golden Floppy” award shall be given to the attendees who would share bold or honest statements.
Next was our chance to get to know each other through self-introductions. We were supposed to talk about who we are, where we are from and finally, what we want from this meeting or from life itself. The challenge was to do this in four words.

After the introductions, Sylvain Belanger, the Director of Preservation of Library and Archives in Canada, talked about where his organization will be heading in 2020. He mentioned the physical side of the work they do in Canada to show the challenges they experience. They store, preserve, and circulate over 20 million books, 3 million maps, 90,000 films, and 500 sheets of music.
“We cannot do this alone!” Belanger exclaimed. He emphasized how important a partnership is to advance the library field. He mentioned that the Library and Archives in Canada is looking to enhance preservation and access as well as looking for partnerships. They would also like to introduce the idea of innovation into the mindset of their employees. According to Belanger, the Archives’ vision for the year 2020 includes consolidating their expertise as much as they can and also getting to know how do people do their work for digitization and Web archiving.
After the Belanger’s talk, we split up into groups of three to meet other people we didn’t know so that we could exchange knowledge about what we do and where we came from. Then the groups of two will join to form a group of six that will exchange their visions, challenges, and opportunities. Most of the attendees agreed on the need for growth and accessibility of digitized materials. Some of the challenges were funding, ego, power, culture, etc.
Our visions for 2020, challenges, opportunities – vision: growth & accessibility #libraryleaders2016 @internetarchive pic.twitter.com/ePkpKzvRGB
— Yasmina Anwar (@yasmina_anwar) October 27, 2016

Chris Edward, the Head of Digital Services at the Getty Research Institute, talked about what they are doing, where they are going, and the impact of their partnership with the IA. Edward mentioned that the uploads by the IA are harvested by HathiTrust and the Defense Logistics Agency (DLA). This allows them to distribute their materials. Their vision for 2020 is to continue working with the IA and expanding the Getty research portal, and digitize everything they have and make it available for everyone, anywhere, all the time. They also intend on automating metadata generation (OCR, image recognition, object recognition, etc.), making archival collections accessible, and doing 3D digitization of architectural models. They will then join forces with the International Image Interoperability Framework (IIIF) community to develop the capability to represent these objects. He also added that they want to help the people who do not have the ability to do it on their own.

After lunch, Wendy Hanamura walked us quickly through the Archive’s strategic plan for 2015-2020 and IA’s tools and projects. Some of these plans are:
- Next generation Wayback Machine
- Test pilot with Mozilla so they suggest archived pages for the 404
- Wikimedia link rots
- Building libraries together
- The 20 million books
- Table top scribe
- Open library and discovery tool
- Digitization supercenter
- Collaborative circulation system
- Television Archive — Political ads
- Software and emulation
- Proprietary code
- Scientific data and Journals – Sharing data
- Music — 78’s
“No book should be digitized twice!”, this is how Wendy Hanamura ended her talk.
 Then we had a chance to put our hands on the new tools by the IA and by their partners through having multiple makers’ space stations. There were plenty of interesting projects, but I focused on the International Research Data Commons– by Karissa McKelvey and Max Ogden from the Dat Project. Dat is a grant-funded project, which introduces open source tools to manage, share, publish, browse, and download research datasets. Dat supports peer-to-peer distribution system, (e.g., BitTorrent). Ogden mentioned that their goal is to generate a tool for data management that is as easy as Dropbox and also has a versioning control system like GIT.
Then we had a chance to put our hands on the new tools by the IA and by their partners through having multiple makers’ space stations. There were plenty of interesting projects, but I focused on the International Research Data Commons– by Karissa McKelvey and Max Ogden from the Dat Project. Dat is a grant-funded project, which introduces open source tools to manage, share, publish, browse, and download research datasets. Dat supports peer-to-peer distribution system, (e.g., BitTorrent). Ogden mentioned that their goal is to generate a tool for data management that is as easy as Dropbox and also has a versioning control system like GIT.
After a break Jeffrey Mackie-Mason, the University Librarian of UC Berkeley, interviewed Brewster Kahle about the future of libraries and online knowledge. The discussion focused on many interesting issues, such as copyrights, digitization, prioritization of archiving materials, cost of preservation, avoiding duplication, accessibility and scale, IA’s plans to improve the Wayback Machine and many other important issues related to digitization and preservation. At the end of the interview, Kahle announced his white paper, which wrote entitled “Transforming Our Libraries into Digital Libraries”, and solicited feedback and suggestions from the audience.
"Dark Archive is one of the WORST ideas ever" @brewster_kahle @internetarchive #libraryleaders2016
— Yasmina Anwar (@yasmina_anwar) October 27, 2016
@waybackmachine is the calling card of the @internetarchive and it has been neglected until recently #libraryleaders2016
— Merrilee Proffitt (@MerrileeIAm) October 27, 2016
"Dark Archive is one of the WORST ideas ever" @brewster_kahle @internetarchive #libraryleaders2016
— Yasmina Anwar (@yasmina_anwar) October 27, 2016
@waybackmachine is the calling card of the @internetarchive and it has been neglected until recently #libraryleaders2016
— Merrilee Proffitt (@MerrileeIAm) October 27, 2016
https://twitter.com/tripofmice/status/791790807736946688
https://twitter.com/tripofmice/status/791786514497671168
Its not what we can get away with, but rather what is the role of libraries in #copyright issues -Brewster K. #libraryleaders2016
— Dr.EB 🇵🇸 (@LNBel) October 27, 2016

At the end of the day, we had an unusual and creative group photo by the great photographer Brad Shirakawa who climbed out on a narrow plank high above the crowd to take our picture.
On day two the first session I attended was a keynote address by Brewster Kahle about his vision for the Internet Archive’s Library of 2020, and what that might mean for all libraries.
"A library is engine for research!!" #libraryleaders2016 pic.twitter.com/D2du0L67T2
— Yasmina Anwar (@yasmina_anwar) October 28, 2016
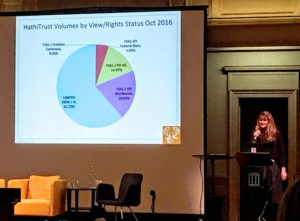
Heather Christenson, the Program Officer for HathiTrust, talked about where HeathiTrust is heading in 2020. Christenson started by briefly explaining what is HathiTrust and why HathiTrust is important for libraries. Christenson said that HathiTrust’s primary mission is preserving for print and digital collections, improving discovery and access through offering text search and bibliographic data APIs, and generating a comprehensive collection of the US federal documents. Christensen mentioned that they did a survey about their membership and found that people want them to focus on books, videos, and text materials.

Our next session was a panel discussion about the Legal Strategies Practices for libraries by Michelle Wu, the Associate Dean for Library Services and Professor of Law at the Georgetown University Law Center, and Lila Bailey, the Internet Archive’s Outside Legal Counsel. Both speakers shared real-world examples and practices. They mentioned that the law has never been clearer and it has not been safer about digitizing, but the question is about access. They advised the libraries to know the practical steps before going to the institutional council. “Do your homework before you go. Show the usefulness of your work, and have a plan for why you will digitize, how you will distribute, and what you will do with the takedown request.”

After the panel Tom Rieger, the Manager of Digitization Services Section at the Library of Congress (LOC), discussed the 2020 vision for the Library of Congress. Reiger spoke of the LOC’s 2020 strategic plan. He mentioned that their primary mission is to serve the members of Congress, the people in the USA, and the researchers all over the world by providing access to collections and information that can assist them in decision making. To achieve their mission the LOC plans to collect and preserve the born digital materials and provide access to these materials, as well as providing services to people for accessing these materials. They will also migrate all the formats to an easily manageable system and will actively engage in collaboration with many different institutions to empowering the library system, and adapt new methods for fulfilling their mission.

In the evening, there were different workshops about tools and APIs that IA and their partners provided. I was interested in the RDM workshop by Max Ogden and Roger Macdonald. I wanted to explore the ways we can support and integrate this project into the UC Berkeley system. I gained more information about how the DAT project worked through live demo by Ogden. We also learned about the partnership between the Dat Project and the Internet Archive to start storing scientific data and journals at scale.

We then formed into small groups around different topics on our field to discuss what challenges we face and generate a roadmap for the future. I joined the “Long-Term Storage for Research Data Management” group to discuss what the challenges and visions of storing research data and what should libraries and archives do to make research data more useful. We started by introducing ourselves. We had Jefferson Bailey from the Internet Archive, Max Ogden, Karissa from the DAT project, Drew Winget from Stanford libraries, Polina Ilieva from the University of California San Francisco (UCSF), and myself, Yasmin AlNoamany.
Some of the issues and big-picture questions that were addressed during our meeting:
- The long-term storage for the data and what preservation means to researchers.
- What is the threshold for reproducibility?
- What do researchers think about preservation? Does it mean 5 years, 15 years, etc.?
- What is considered as a dataset? Harvard considers anything/any file that can be interpreted as a dataset.
- Do librarians have to understand the data to be able to preserve it?
- What is the difference between storage and preservation? Data can be stored, but long-term preservation needs metadata.
- Do we have to preserve everything? If we open it to the public to deposit their huge datasets, this may result in noise. For the huge datasets what should be preserved and what should not?
- Privacy and legal issues about the data.
Principles of solutions
- We need to teach researchers how to generate metadata and the metadata should be simple and standardized.
- Everything that is related to research reproducibility is important to be preserved.
- Assigning DOIs to datasets is important.
- Secondary research – taking two datasets and combine them to produce something new. In digital humanities, many researchers use old datasets.
- There is a need to fix the 404 links for datasets.
- There is should be an easy way to share data between different institutions.
- Archives should have rules for the metadata that describe the dataset the researchers share.
- The network should be neutral.
- Everyone should be able to host a data.
- Versioning is important.
Notes from the other Listening posts:
- LIBRARY 2020: Refining the vision, mapping the collection, and identifying the contributors
- WEB ARCHIVING: What are the opportunities for collaborative technology building?
- DIGITIZATION: Scanning services–develop a list of key improvements and innovations you desire
- DISCOVERY: Open Library– ideas for moving forward

At the end of the day, Polina Ilieva, the Head of Archives and Special Collections at UCSF, wrapped up the meeting by giving her insight and advice. She mentioned that for accomplishing their 2020 goals and vision, there is a need to collaborate and work together. Ilieva said that the collections should be available and accessible for researchers and everyone, but there is a challenge of assessing who is using these collections and how to quantify the benefits of making these collections available. She announced that they would donate all their microfilms to the Internet Archive! “Let us all work together to build a digital library, serve users, and attract consumers. Library is not only the engine for search, but also an engine for change, let us move forward!” This is how Ilieva ended her speech.
It was an amazing experience to hear about the 2020 vision of the libraries and be among all of the esteemed library leaders I have met. I returned with inspiration and enthusiasm for being a part of this mission and also ideas for collaboration to advance the library mission and serve more people.
–Yasmin AlNoamany
Event: Editions Inside of Archives: Literary Editing and Preservation at the Mark Twain Project
I’m sharing this event announcement because it may be of interest to you.
The Literature and Digital Humanities Working Group, and the Americanist Colloquium, would like to invite you to join us at the following talk:
Editions Inside of Archives: Literary Editing and Preservation at the Mark Twain Project
Christopher Ohge
Thursday October 13th, 6.30pm
DLib Collaboratory, 350 Barrows Hall
The Mark Twain Papers & Project not only contains the largest collection of material by and about Mark Twain, it also employs several editors working toward a complete scholarly edition of Mark Twain’s writings and letters. The editors in the Project are sometimes involved in archival management, preservation, and “digital humanities” endeavors. Yet the goals of the archive both overlap with and diverge from those of a scholarly edition, especially in that editions produced by the Mark Twain Project use material from other archives, and considering the limit to which editorial work can faithful to physical manuscripts. Archival projects are sometimes done at the expense of editorial projects, and vice versa; each enterprise has its gains and losses.
Digital scholarly editing can also depart from more traditional print editorial enterprises. When editorial policy modifications occur simultaneously with the evolution of digital interfaces, what is an editor to do? Put another way, when “digitizing” an old book with a different editorial policy, is one obliged to “re-edit” the text or compromise about how to present the product of a different set of expectations for editing and designing scholarly editions? How do notions of readability and reliability change with concurrent technological innovations? I shall examine instances where the physical archive, the digital archive, and editions at the Mark Twain Project have illuminated common as well as new ground on reading, editing, and cultural heritage.
A Night With Voice of Witness: August 16 @ 6pm in the MLK Student Union at UC Berkeley
This Tuesday—August 16, 2016—please join us along with Voice of Witness for an evening of oral history and human rights. OHC interviewer, Shanna Farrell, will moderate a lively discussion between Voice of Witness editors, Peter Orner (Underground America: Narratives of Undocumented Lives) and Robin Levi (Inside this Place, Not of it: Narratives from Women’s Prisons) on the intersections of oral history methods, access, and social justice.
The event will begin at 6pm in the MLK Student Union’s Tilden Room (5th Floor). Light refreshments will be served and Voice of Witness books will be available for purchase.
This event is sponsored by OHC’s Advanced Oral History Summer Institute, which brings together students, faculty and scholars from across the United States for an intensive week of study and discussion. For more details, see the Oral History Center website.

Workshop: Out of the Archives, Into Your Laptop

Event date: Friday, February 12, 2016
Event time: 2:00PM – 3:30PM
Event location: Doe 308A
Before you head out to do research in the archives this semester, please join us for a workshop on best practices for gathering and digitizing research materials. This workshop will focus on capturing visual and manuscript materials, but will be useful for any researcher collecting research materials from archives. Topics covered will include smart capture workflows, preserving and moving metadata, copyright, and platforms for managing and organizing your research data.
Presenters:
- Mary Elings, Head of Digital Collections, Bancroft Library
- Lynn Cunningham, Principal Digital Curator, Art History Visual Resources Center
- Jason Hosford, Senior Digital Curator, Art History Visual Resources Center
- Jamie Wittenberg, Research Data Management Service Design Analyst, Research IT
- Camille Villa, Digital Humanities Assistant, Research IT
BANCROFT SUMMER ARCHIVAL INTERNSHIP 2015
The Bancroft Library University of California Berkeley

SUMMER ARCHIVAL INTERNSHIP 2015
Who is Eligible to Apply
Graduate students currently attending an ALA accredited library and information science program who have taken coursework in archival administration and/or digital libraries.
Born-Digital Processing Internship Duties
The Born-Digital Processing Intern will be involved with all aspects of digital collections work, including inventory control of digital accessions, collection appraisal, processing, description, preservation, and provisioning for access. Under the supervision of the Digital Archivist, the intern will analyze the status of a born-digital manuscript or photograph collection and propose and carry out a processing plan to arrange and provide access to the collection. The intern will gain experience in appraisal, arrangement, and description of born-digital materials. She/he will use digital forensics software and hardware to work with disk images and execute processes to identify duplicate files and sensitive/confidential material. The intern will create an access copy of the collection and, if necessary, normalize access files to a standard format. The intern will generate an EAD-encoded finding aid in The Bancroft Library’s instance of ArchivesSpace for presentation on the Online Archive of California (OAC). Lastly, the intern will complete a full collection-level MARC catalog record for the collection using the University Library’s Millennium cataloging system. All work will occur in the Bancroft Technical Services Department, and interns will attend relevant staff meetings.
Duration:
6 weeks (minimum 120 hours), June 29 – August 7, 2015 (dates are somewhat flexible)
NOTE: The internship is not funded, however, it may be possible to arrange for course credit for the internship. Interns will be responsible for living expenses related to the internship (housing, transportation, food, etc.).
Application Procedure:
The competitive selection process is based on an evaluation of the following application materials:
Cover letter & Resume
Current graduate school transcript (unofficial)
Photocopy of driver’s license (proof of residency if out-of-state school)
Letter of recommendation from a graduate school faculty member
Sample of the applicant’s academic writing or a completed finding aid
All application materials must be postmarked on or before Friday, April 17, 2015 and either mailed to:
Mary Elings
Head of Digital Collections
The Bancroft Library
University of California Berkeley
Berkeley, CA 94720.
or emailed to melings [at] library.berkeley.edu, with “Born Digital Processing Internship” in the subject line.
Selected candidates will be notified of decisions by May 1, 2015.
Event: Bancroft Round Table: Exposing the Hidden Collections of The Bancroft Library: A Report on the “Quick Kills” Project
Please join us for the November Bancroft Library Round Table!
It will take place, as usual, in the Lewis Latimer Room of The Faculty Club at 12:00 p.m. on Thursday, November 20. Lara Michels, archivist at the Bancroft Library, will present Exposing the Hidden Collections of The Bancroft Library: A Report on the “Quick Kills” Project.
Come hear Bancroft archivist Lara Michels report on almost three years of work on the “Quick Kills” manuscripts processing project at the Bancroft Library. Funded by the Rosalinde and Arthur Gilbert Foundation, the “Quick Kills” project has as its aim to increase access to the wonderful, but sometimes hidden, manuscript collections of the Library. Lara will share highlights, insights, and reflections on the process of opening up nearly 150 legacy manuscript collections to a new generation of researchers.
Hope to see you there.
Lara Michels and Baiba Strads Bancroft Library Staff
Bancroft to Explore Text Analysis as Aid in Analyzing, Processing, and Providing Access to Text-based Archival Collections
Mary W. Elings, Head of Digital Collections, The Bancroft Library
The Bancroft Library recently began testing a theory discussed at the Radcliffe Workshop on Technology & Archival Processing held at Harvard’s Radcliffe College in early April 2014. The theory suggested that archives can use text analysis tools and topic modelling — a type of statistical model for discovering the abstract “topics” that occur in a collection of documents — to analyze text-based archival collections in order to aid in analyzing, processing and describing collections, as well as improving access.
Helping us to test this theory, the Bancroft welcomed summer intern Janine Heiser from the UC Berkeley School of Information. Over the summer, supported by an ISchool Summer Non-profit Internship Grant, Ms. Heiser worked with digitized analog archival materials to test this theory, answer specific research questions, and define use cases that will help us determine if text analysis and topic modelling are viable technologies to aid us in our archival work. Based on her work over the summer, the Bancroft has recently awarded Ms. Heiser an Archival Technologies Fellowship for 2015 so that she can continue the work she began in the summer and further develop and test her work.
During her summer internship, Ms. Heiser created a web-based application, called “ArchExtract” that extracts topics and named entities (people, places, subjects, dates, etc.) from a given collection. This application implements and extends various natural language processing software tools such as MALLET and the Stanford Core NLP toolkit. To test and refine this web application, Ms. Heiser used collections with an existing catalog record and/or finding aid, namely the John Muir Correspondence collection, which was digitized in 2009.
For a given collection, an archivist can compare the topics and named entities that ArchExtract outputs to the topics found in the extant descriptive information, looking at the similarities and differences between the two in order to verify ArchExtract’s accuracy. After evaluating the accuracy, the ArchExtract application can be improved and/or refined.
Ms. Heiser also worked with collections that either have minimal description or no extant description in order to further explore this theory as we test the tool further. Working with Bancroft archivists, Ms. Heiser will determine if the web application is successful, where it falls short, and what the next steps might be in exploring this and other text analysis tools to aid in processing collections.
The hope is that automated text analysis will be a way for libraries and archives to use this technology to readily identify the major topics found in a collection, and potentially identify named entities found in the text, and their frequency, thus giving archivists a good understanding of the scope and content of a collection before it is processed. This could help in identifying processing priorities, funding opportunities, and ultimately helping users identify what is found in the collection.
Ms. Heiser is a second year masters’ student at the UC Berkeley School of Information where she is learning the theory and practice of storing, retrieving and analyzing digital information in a variety of contexts and is currently taking coursework in natural language processing with Marti Hearst. Prior to the ISchool, Ms. Heiser worked at several companies where she helped develop database systems and software for political parties, non-profits organizations, and an online music distributor. In her free time, she likes to go running and hiking around the bay area. Ms. Heiser was also one of our participants in the #HackFSM hackathon! She was awarded an ISchool Summer Non-profit Internship Grant to support her work at Bancroft this summer and has been awarded an Archival Technologies Fellowship at Bancroft for 2015.