Digital Humanities
New for Gale Digital Scholar Lab
A new interface for Gale Digital Scholar Lab is coming on December 17, 2021!
What’s different?
- New design
- Add documents to whichever Content Set you want without having to set an Active Content Set.
- Options for cleaning data more visible and user-friendly
- More flexibility for Analysis tools
- Other enhancements based on user feedback
What’s the same?
- The Build, Clean, and Analyze workflow remains the same
- Options for the six types of analyses that researchers can now run will be available
How do I try it out?
To take a tour of the enhanced Gale Digital Scholar Lab, after logging in, select the “Try Our New Experience” link in the header.
What do I need to do before the change?
- Download any existing visualizations and tabular data. There are multiple options for download, including raw analysis data (CSV and JSON) and several visualization image formats. Existing visualizations and tabular data will not be migrated automatically.
- All content sets and clean configurations will migrate to the new platform, with no action required by current researchers.
Workshop: Copyright and Fair Use for Digital Projects

Copyright and Fair Use for Digital Projects
Wednesday, November 10, 11:10am–12:30pm
Online: Register to receive the Zoom link
Rachael Samberg and Tim Vollmer
This training will help you navigate the copyright, fair use, and usage rights of including third-party content in your digital project. Whether you seek to embed video from other sources for analysis, post material you scanned from a visit to the archives, add images, upload documents, or more, understanding the basics of copyright and discovering a workflow for answering copyright-related digital scholarship questions will make you more confident in your publication. We will also provide an overview of your intellectual property rights as a creator and ways to license your own work. Register here.
Upcoming Workshops in this Series:
Coming in Spring 2022:
- By Design: Graphics & Images Basics
- HTML/CSS Toolkit for Digital Projects
- Can I Mine That? Should I Mine That?: A Clinic for Copyright, Ethics & More in TDM Research
- Publish Digital Books & Open Educational Resources with Pressbooks
Please see bit.ly/dp-berk for details.
Workshop: The Long Haul: Best Practices for Making Your Digital Project Last
The Long Haul: Best Practices for Making Your Digital Project Last
Wednesday, October 13, 11:10am-12:00pm
Online: Register to receive the Zoom link
Scott Peterson and Erin Foster
You’ve invested a lot of work in creating a digital project, but how do you ensure it has staying power? We’ll look at choices you can make at the beginning of project development to influence sustainability, best practices for documentation and asset management, and how to sunset your project in a way that ensures long-term access for future researchers. Register here.
Upcoming Workshops in this Series – Fall 2021:
- Copyright and Fair Use for Digital Projects
Please see bit.ly/dp-berk for details.
Workshop: Web Platforms for Digital Projects
Web Platforms for Digital Projects
Tuesday, October 12th, 3:10pm-4:30pm
Online: Register to receive the Zoom link
Stacy Reardon and Kiyoko Shiosaki
How do you go about publishing a digital book, a multimedia project, a digital exhibit, or another kind of digital project? In this workshop, we’ll take a look at use cases for common open-source web platforms WordPress, Drupal, Omeka, and Scalar, and we’ll talk about hosting, storage, and asset management. There will be time for hands-on work in the platform most suited to your needs. No coding experience is necessary. Register here.
Upcoming Workshops in this Series – Fall 2021:
- The Long Haul: Best Practices for Making Your Digital Project Last
- Copyright and Fair Use for Digital Projects
Please see bit.ly/dp-berk for details.
Workshop: Creating Web Maps with ArcGIS Online

Creating Web Maps with ArcGIS Online
Wednesday, September 29, 11:10am-12:30pm
Online: Register to receive the Zoom link
Susan Powell and Erica Newcome
Want to make a web map, but not sure where to start? This short workshop will introduce key mapping terms and concepts and give an overview of popular platforms used to create web maps. We’ll explore one of these platforms (ArcGIS Online) in more detail. You’ll get some hands-on practice adding data, changing the basemap, and creating interactive map visualizations. At the end of the workshop you’ll have the basic knowledge needed to create your own simple web maps. Register here.
Upcoming Workshops in this Series – Fall 2021:
- Web Platforms for Digital Projects
- The Long Haul: Best Practices for Making Your Digital Project Last
- Copyright and Fair Use for Digital Projects
Please see bit.ly/dp-berk for details.
Workshop: Publish Digital Books & Open Educational Resources with Pressbooks
Publish Digital Books & Open Educational Resources with Pressbooks
Tuesday, September 14th, 11:10am-2:30pm
Online: Register to receive the Zoom link
Tim Vollmer and Stacy Reardon
If you’re looking to self-publish work of any length and want an easy-to-use tool that offers a high degree of customization, allows flexibility with publishing formats (EPUB, PDF), and provides web-hosting options, Pressbooks may be great for you. Pressbooks is often the tool of choice for academics creating digital books, open textbooks, and open educational resources, since you can license your materials for reuse however you desire. Learn why and how to use Pressbooks for publishing your original books or course materials. You’ll leave the workshop with a project already under way! Register here.
Upcoming Workshops in this Series – Fall 2021:
- Creating Web Maps with ArcGIS Online
- Web Platforms for Digital Projects
- The Long Haul: Best Practices for Making Your Digital Project Last
- Copyright and Fair Use for Digital Projects
Please see bit.ly/dp-berk for details.
PhiloBiblon 2021 n. 3 (mayo): PhiloBiblon y el mundo wiki. Propuesta de una colaboración
Nos es muy grato anunciar la tercera entrega de PhiloBiblon para 2021, sobre todo porque a la vez podemos anunciar el comienzo de un proyecto piloto, sufragado por la National Endowment of the Humanities (NEH) del gobierno federal de EE.UU: “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept.” La financiación que nos han concedido nos hará comenzar el proyecto el primero de junio del año en curso y finalizará el 30 de mayo de 2022.
El diseño del proyecto a partir de ahora intentará solucionar uno de los problemas más difíciles de proyectos digitales de larga trayectoria: mantener el soporte tecnológico. PhiloBiblon se inició como base de datos ancilar del proyecto para el Dictionary of the Old Spanish Language, llevado a cabo en la University of Wisconsin, Madison, por Lloyd Kasten y su alumno, John Nitti. A lo largo de los últimos 40 años hemos podido sostener, con dificultad, el database management system (DBMS) a la altura de la tecnología al uso. En Madison se empleó al principio el DBMS FAMULUS, creado, irónicamente en Berkeley en 1964, para las bibliografías del personal de la Pacific Southwest Forest and Range Experiment Station. Desde entonces, las transformaciones tecnológicas han sido constantes: desde los discos CD-ROM de ADMYTE (Archivo Digital de Manuscritos Y Textos Españoles) a una primera versión de la web en 1997, hasta llegar a la versión actual en 2014. Estas transformaciones han sido onerosas y han llegado por vía de constantes solicitudes a varias agencias y fundaciones, sobre todo a la NEH. La ayuda actual representa la primera solicitud exitosa desde 2014.
PhiloBiblon utiliza actualmente un DBMS relacional, OpenInsight, de la empresa Revelation Technology, descendiente lineal de Revelation G, la versión con la que comenzamos a trabajar en 1987. Este sistema fue diseñado por John May, estudiante graduado en Historia de la Ciencia a la sazón, que pronto cambió la carrera académica por el mundo de la informática. John ha mantenido y desarrollado PhiloBiblon hasta ahora, conformándolo a lo largo de más de 35 años en diez tablas relacionales: textos, testimonios, manuscritos e impresos, ejemplares de los impresos, personas, instituciones, topónimos y referencias secundarias. Entre sí, estas diez tablas cuentan con 1.246 elementos informáticos (campos), 98 vocabularios controlados, 110 índices y 30 pantallas para la incorporación de nuevos datos. Puedes encontrar versiones en formato PDF de algunas de estas útimas tablas en nuestra página Colaborar, con el objetivo de facilitar las aportaciones de nuestros usuarios.
PhiloBiblon y su DBMS relacional ya existían antes de que Tim Berners-Lee alumbrara la red en Suiza durante 1989, así como su explosión en 1994 al comercializarse el primer navegador realmente útil, Netscape. Era evidente casi desde el principio que la worldwide web ofrecía a PhiloBiblon un vehículo muy superior a los impresos y a los discos CD-ROM para poner nuestros datos al alcance de los investigadores. En aquella primera versión de la red (1997), el usuario podría buscar cualquier códice o frase de interés, pero lo que se recuperaba era siempre un manuscrito o impreso que contenía el elemento de búsqueda. En la versión actual se exportan las tablas de PhiloBiblon a ficheros XML, siendo cada tabla un fichero único. A continuación, se cargan estos ficheros al servidor de la Bancroft Library (y a su sitio espejo en la Universitat Pompeu Fabra), donde el programa eXtensible Text Framework (XTF) los separa en sus registros individuales, los indexa, y más tarde recupera los registros indicados a raíz de una búsqueda. Si se busca una frase, el programa ofrece como resultado el elenco de los textos que contienen dicha frase; si se busca un manuscrito de determinadas características, igualmente se ofrece un elenco de manuscritos que responden a ellas.
El sistema no se caracteriza por su elegancia y podría mejorar su eficiencia, pero funciona bastante bien. Además del problema de sostener el soporte tecnológico, después de la creación de la web 3.0 (la web semántica), PhiloBiblon necesita enfrentarse también con el hecho de que su existencia se organiza dentro de un silo informático, sin relación orgánica con otras fuentes de información. La web semántica está diseñada para utilizar los datos abiertos enlazados (Linked Open Data) precisamente para poder establecer relaciones entre fuentes de información (v.g., recursos como el Catálogo Colectivo del Patrimonio Bibliográfico Español) sin intervención manual del ser humano. Desde 2014, los equipos de PhiloBiblon hemos ido preparando toda una serie de solicitudes a la NEH, a agencias españolas, catalanas y europeas, así como a fundaciones de diverso grado, con el objetivo de financiar la transformación de PhiloBiblon en una fuente de información de la web semántica. Por desgracia, no hemos tenido éxito.
El año pasado, en vez de proponer la creación ex profeso de una nueva base de datos para PhiloBiblon, hemos propuesto una solución radicalmente diferente: incorporar PhiloBiblon al mundo wiki, cuyo producto más conocido es la Wikipedia, creada en 2002. Hoy por hoy, es el ejemplo más visible y de más éxito de la informática al servicio de la humanidad, de todo el mundo, desde los niños de colegio hasta los mayores de la tercera edad. En PhiloBiblon nos servimos de Wikipedia todos los días. En BETA, por ejemplo, citamos la obra en nueve lenguas diferentes, según el tema tratado, más de 1.400 veces. El motor de Wikipedia es el DBMS wikibase, que también sostiene el entorno más estructurada de Wikidata.
Es este último, Wikidata, el que más nos interesa precisamente por su carácter completamente abierto. Pero resulta un método poco apto para un proyecto como PhiloBiblon, que requiere un control más preciso de las personas que pueden contribuir a él. Hemos encontrado la solución ideal para nuestros propósitos en FactGrid, de la Universität Erfurt. Gracias a la generosa acogida de su director, Olaf Simons, vamos a establecer una relación que ojalá sea fructífera y duradera. FactGrid se vale de la misma tecnología de Wikidata y la creación de nuevas entidades emplea los mismos procedimientos utilizados por miles de usuarios del sistema. Hemos creado ya FactGrid:PhiloBiblon, una página web embrión para servir como sandbox (o entorno de pruebas), mientras vamos adiestrándonos en el proceso de crear registros en FactGrid y establecer el modelo detallado para importar de una vez el contenido de PhiloBiblon al nuevo entorno de producción.
A efectos de la solicitud del año pasado, Olaf creó un prototipo para mostrar BITAGAP manid 1067, el manuscrito BNE MSS/10069, que contiene las Cantigas de Santa María de Alfonso X, en el formato por defecto de Wikidata. Aquí lo tenemos, junto a imágenes parciales del mismo registro en la web de PhiloBiblon y en el catálogo de la BNE:
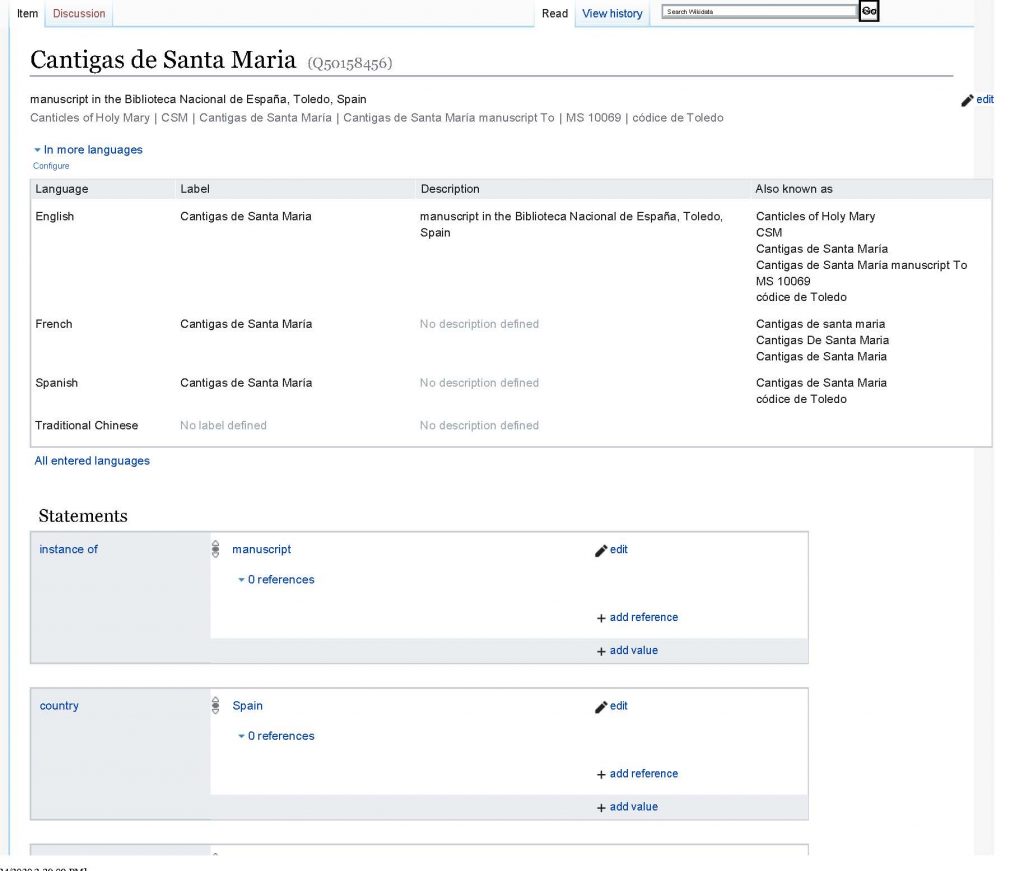


Como el lector puede comprobar, se trata exactamente de los mismos datos, pero con tres presentaciones distintas.
Cuando finalice este proyecto piloto en mayo de 2022, esperamos haber adquirido unas ideas mucho más precisas tanto sobre el formato que queremos utilizar para presentar PhiloBiblon a nuestros usuarios como acerca de los procedimientos necesarios para importar en masa a FactGrid sus más de 415.000 registros. Pero ahora mismo, con el proyecto ni siquiera en ciernes—porque no comienza oficialmente hasta el primero de junio—, nuestros esfuerzos se dedicarán a la limpieza y coordinación de los datos en las bibliografías de PhiloBiblon.
A corto plazo, vamos a emitir una llamada urbi et orbi para reclutar a voluntarios que nos puedan ayudar en la eliminación de erratas y errores, tareas humildes y a veces algo tediosas, pero completamente necesarias ante la exportación de tantos registros a un nuevo entorno tecnológico. Intentaremos congeniar la forma en la que nuestras necesidades se adapten a la de nuestros usuarios.
Charles B. Faulhaber
SSThe Bancroft Library
University of California, Berkeley
Workshop: HTML/CSS Toolkit for Digital Projects
HTML/CSS Toolkit for Digital Projects
Monday, April 12th, 3:10pm-4:30pm
Online: Register to receive the Zoom link
Stacy Reardon and Kiyoko Shiosaki
If you’ve tinkered in WordPress, Google Sites, or other web publishing tools, chances are you’ve wanted more control over the placement and appearance of your content. With a little HTML and CSS under your belt, you’ll know how to edit “under the hood” so you can place an image exactly where you want it, customize the formatting of text, or troubleshoot copy & paste issues. By the end of this workshop, interested learners will be well prepared for a deeper dive into the world of web design. Register here.
Upcoming Workshops in this Series:
- Check back for Fall 2021!
Please see bit.ly/dp-berk for details.
New publication by Nick Paige from the French Department
Check out this new book by Department of French faculty member Nicholas Paige, available in print and as an ebook through the online catalog.

From introduction:
“This book is about the evolution of French and to a lesser degree English novels – by which I mean French- and English-language novels – from 1601 to 1830. And while evolution is very much at the center of my preoccupations, I do not offer a “story” about that evolution. There is no plot, as we might want if we thought of the novel moving forward, perhaps from birth, episode by episode, toward a resolution, some happy state of stability – as if, in other words, the novel’s own history could be made into a kind of novel.”
“In lieu of a story, Technologies of the Novel offers a quantitative account of the ceaseless yet patterned flux of the novel system over these twenty-three decades.”
“Technologies of the Novel is, then, digital and distant; but it is most certainly not antianalogue or anticlose.”
Workshop: Text Data Mining and Publishing
Text Data Mining and Publishing
Tuesday, March 16th, 11:10am-12:30pm
Online: Register to receive the Zoom link
Rachael Samberg and Stacy Reardon
If you are working on a computational text analysis project and have wondered how to legally acquire, use, and publish text and data, this workshop is for you! We will teach you 5 legal literacies (copyright, contracts, privacy, ethics, and special use cases) that will empower you to make well-informed decisions about compiling, using, and sharing your corpus. By the end of this workshop, and with a useful checklist in hand, you will be able to confidently design lawful text analysis projects or be well positioned to help others design such projects. Register here.
Upcoming Workshops in this Series – Spring 2021:
- By Design: Graphics & Images Basics
- HTML/CSS Toolkit for Digital Projects
Please see bit.ly/dp-berk for details.