Summary
Brief discussion in the A&H Data series about what data for the arts and humanities even is.
This is the first of a multi-part series exploring the idea and use of data in the Arts & Humanities. For more information, check out the UC Berkeley Library’s Data and Digital Scholarship page.
Arts & Humanities researchers work with data constantly. But, what is it?
Part of the trick in talking about “data” in regards to the humanities is that we are already working with it. The books and letters (including the one below) one reads are data, as are the pictures we look at and the videos we watch. In short, arts and humanities researchers are already analyzing data for the essays, articles, and books that they write. Furthermore, the resulting scholarship is data.
For example, the letter below from Bancroft Library’s 1906 San Francisco Earthquake and Fire Digital Collection on Calisphere is data.

George Cooper Pardee, “Aid for San Francisco: Letter from the Mayor in Oregon,”
April 24, 1906, UC Berkeley, Bancroft Library on Calisphere.
One ends up with the question “what isn’t data?”
The broad nature of what “data” is means that instead of asking if something is data, it can be more useful to think about what kind of data one is working with. After all, scholars work with geographic information; metadata (e.g., data about data); publishing statistics; and photographs differently.
Another helpful question is to consider how structured it is. In particular, you should pay attention to whether the data is:
- unstructured
- semi-structured
- structured
The level of structure informs us how to treat the data before we analyze it. If, for example, you have hundreds of of images, you want to work with, it’s likely you’ll have to do significant amount of work before you can analyze your data because most photographs are unstructured.

In contrast, the letter toward the top of this post is semi-structured. It is laid out in a typical, physical letter style with information about who, where, when, and what was involved. Each piece of information, in turn, is placed in standardized locations for easy consumption and analysis. Still, to work with the letter and its fellows online, one would likely want to create a structured counterpart.
Finally, structured data is usually highly organized and, when online, often in machine-readable chart form. Here, for example, are two pages from the Polk San Francisco City Directory from 1955-1956 with a screenshot of the machine-readable chart from a CSV (comma separated value) file below it. This data is clearly structured in both forms. One could argue that they must be as the entire point of a directory is for easy of information access and reading. The latter, however, is the one that we can use in different programs on our computers.


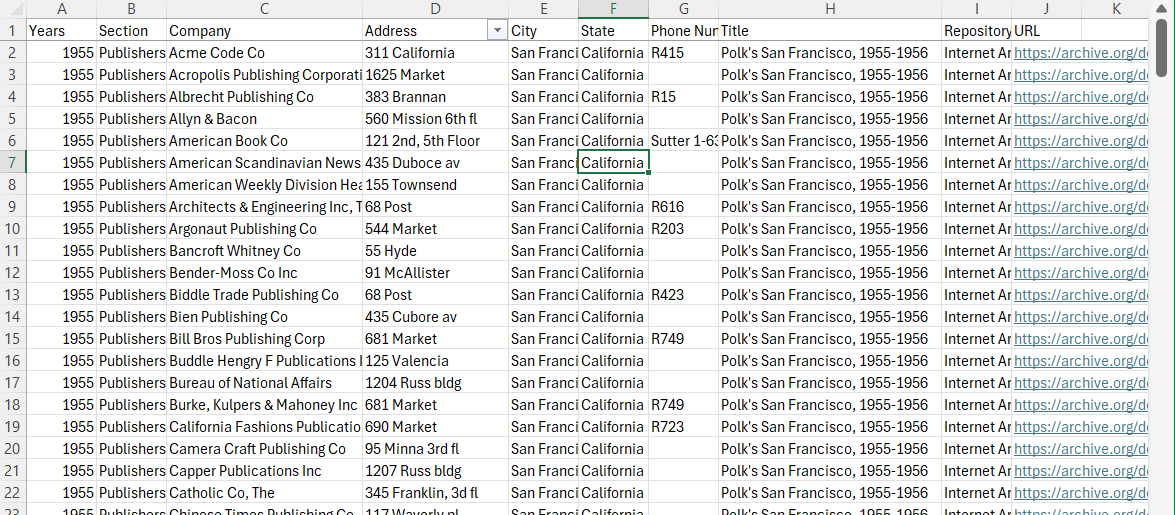 R.L. Polk & Co, Polk’s San Francisco City Directory, vol. 1955–1956 (San Francisco, Calif. : R.L. Polk & Co., 1955),
R.L. Polk & Co, Polk’s San Francisco City Directory, vol. 1955–1956 (San Francisco, Calif. : R.L. Polk & Co., 1955),Internet Archive. | Public Domain.
This post has provided a quick look at what data is for the Arts&Humanities.
The next will be looking at what we can do with machine-readable, structured data sets like the publisher’s information. Stay tuned! The post should be up in two weeks.