Tag: big data
“Big Data as a Way of Life”: How the UCB Library Can Support Big Data Research at Berkeley
This post summarizes findings and recommendations from the Library’s Ithaka S+R Local Report, “Supporting Big Data Research at the University of California, Berkeley” released on October 1, 2021. The research was conducted and the report written by Erin D. Foster, Research Data Management Program Service Lead, Research IT & University of California, Berkeley (UCB) Library, Ann Glusker, Sociology, Demography, Public Policy, & Quantitative Research Librarian, UCB Library, and Brian Quigley, Head of the Engineering & Physical Sciences Division, UCB Library.
OVERVIEW:
In 2020, the Ithaka S+R project “Supporting Big Data Research” brought together twenty-one U.S. institutions to conduct a suite of parallel studies aimed at understanding researcher practices and needs related to data science methodologies and big data research. A team from the UCB Library conducted and analyzed interviews with a group of researchers at UC Berkeley. The timeline appears below. The UC Berkeley team’s report outlines the findings from the interviews with UC Berkeley researchers and makes recommendations for potential campus and library opportunities to support big data research. In addition to the UCB local report, Ithaka S+R will be releasing a capstone report later this year that will synthesize findings from all of the parallel studies to provide an overall perspective on evolving big data research practices and challenges to inform emerging services and support across the country.

PROCESS:
After successfully completing human subjects review, and using an interview protocol and training provided by Ithaka S+R, the team members recruited and interviewed 16 researchers from across ranks and disciplines whose research involved big data, defined as data having at least two of the following: volume, variety, and velocity.
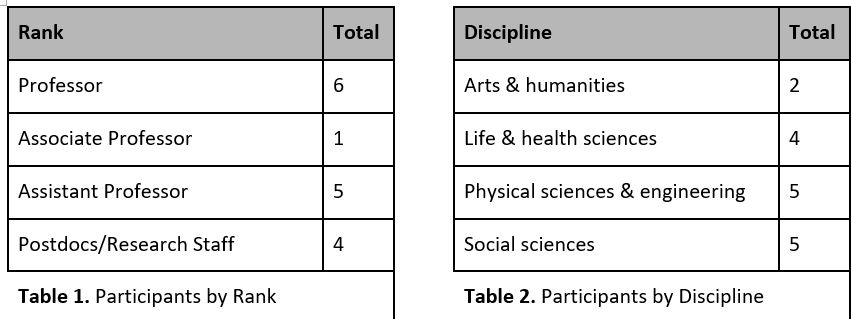
THEMES:
After transcribing the interviews and coding them using an open coding process, six themes emerged. These themes and sub-themes are listed below and treated fully in the final report. The report includes a number of quotes so that readers can “hear” the voices of Berkeley’s big data researchers most directly. In addition, the report outlines the challenges reported by researchers within each theme.

RECOMMENDATIONS:
The most important part of the entire research process was developing a list of recommendations for the UC Berkeley Library and its campus partners. Based on the needs and challenges expressed by researchers, and influenced by our own sense of the campus data landscape including the newly formed Library Data Services Program, these recommendations are discussed in more detail in the full report. They reflect the two main challenges that interviewees reported Berkeley faces as big data research becomes increasingly common. One challenge is that the range of discrete data operations happening all over campus, not always broadly promoted, means that it is easy to have duplications of services and resources — and silos. The other (related) challenge is that Berkeley has a distinctive data landscape and a long history of smaller units on campus being at the cutting edge of data activities. How can these be better integrated while maintaining their individuality and freedom of movement? Additionally, funding is a perennial issue, given the fact that Berkeley is a public institution in an area with a high cost of living and a very competitive salary structure for tech workers who provide data supports.
Here are the report’s recommendations in brief:
-
Create a research-welcoming “third place” to encourage and support data cultures and communities.
The creation of a “data culture” on campus, which can infuse everything from communications to curricula, can address challenges related to navigating the big data landscape at Berkeley, including collaboration/interdisciplinarity, and the gap between data science and domain knowledge. One way to operationalize this idea is to utilize the concept of the “third place,” first outlined by Ray Oldenburg. This can happen in, but should not be limited to, the library, and it can occur in both physical and virtual spaces. Encouraging open exploration and conversation across silos, disciplines, and hierarchies is the goal, and centering Justice, Diversity, Equity and Inclusion (JEDI) as a core principle is essential.
- The University Library, in partnership with Research IT, conducts continuous inquiry and assessment of researchers and data professionals, to be sure our efforts address the in-the-moment needs of researchers and research teams.
- The University Library, in line with being a “third place” for conversation and knowledge sharing, and in partnership with a range of campus entities, sponsors programs to encourage cross-disciplinary engagement.
- Research IT and other campus units institute a process to explore resource sharing possibilities across teams of researchers in order to address duplication and improve efficiency.
- The University Library partners with the Division of Computing, Data Science, and Society (CDSS) to explore possibilities for data-dedicated physical and virtual spaces to support interdisciplinary data science collaboration and consultation.
- A consortium of campus entities develops a data policy/mission statement, which has as its central value an explicit justice, equity, diversity and inclusion (JEDI) focus/requirement.
-
Enhance the campus computing and data storage infrastructure to support the work of big data researchers across all disciplines and funding levels.
Researchers expressed gratitude for campus computing resources but also noted challenges with bandwidth, computing power, access, and cost. Others seemed unaware of the full extent of resources that were available to them. It is important to ensure that our computing and storage options meet researcher needs and then encourage them to leverage those resources.
- Research, Teaching & Learning and the University Library partner with Information Services & Technology (IST) to conduct further research and benchmarking in order to develop baseline levels of free data storage and computing access for all campus researchers.
- Research IT and the University Library work with campus to develop further incentives for funded researchers to participate in the Condo Cluster Program for Savio and/or the Secure Research Data & Computing (SRDC) platform.
- The University Library and Research IT partner to develop and promote streamlined, clear, and cost-effective workflows for storing, sharing, and moving big data.
-
Strengthen communication of research data and computing services to the campus community.
In the interviews, researchers directly or indirectly expressed a lack of knowledge about campus services, particularly as they related to research data and computing. In light of that, it is important for campus service providers to continuously assess how researchers are made aware of the services available to them.
- The University Library partners with Research IT to establish a process to reach new faculty across disciplines about campus data and compute resources.
- The University Library partners with Research IT and CDSS (including D-Lab and BIDS) to develop a promotional campaign and outreach model to increase awareness of the campus computing infrastructure and consulting services.
- The University Library develops a unified and targeted communication method for providing campus researchers with information about campus data resources – big data and otherwise.
-
Coordinate and develop training programs to support researchers in “keeping up with keeping up”
One of the most-cited challenges researchers stated in terms of training is that of keeping up with the dizzying pace of advances in the field of big data, which necessitate learning new methods and tools. Even with postdoc/grad student contributions, it can seem impossible to stay up to date with needed skills and techniques. Accordingly, the focus in this area should be to help researchers to keep up with staying current in their fields.
- The University Library addresses librarians’/library staff needs for professional development to increase comfort with the concepts of and program implementation around the research life cycle and big data.
- The University Library’s newly formed Library Data Services Program (LDSP) is well-positioned to offer campus-wide training sessions within the Program’s defined scope, and to serve as a hub for coordination of a holistic and scaffolded campus-wide training program
- The University Library’s LDSP, departmental liaisons, and other campus entities offering data-related training should specifically target graduate students and postdocs for research support.
- CDSS and other campus entities investigate the possibility of a certificate training program — targeted at faculty, postdocs, graduate students — leading to knowledge of the foundations of data science and machine learning, and competencies in working with those methodologies.
The full report concludes with a quote from one of the researchers interviewed, which we team members feel encapsulates much of the current situation relating to big data research at Berkeley, as well as the challenges and opportunities ahead:
[Physical sciences & engineering researcher] “The tsunami is coming. I sound like a crazy person heaping warning, but that’s the future. I’m sure we’ll adapt as this technology becomes more refined, cheaper… Big data is the way of the future. The question is, where in that spectrum do we as folks at Berkeley want to be? Do we want to be where the consumers are or do we want to be where the researchers should be? Which is basically several steps ahead of where what is more or less the gold standard. That’s a good question to contemplate in all of these discussions.
Do we want to be able to meet the bare minimum complying with big data capabilities? Or do we want to make sure that big data is not an issue? Because the thing is that it’s thrown around in the context that big data is a problem, a buzzword. But how do we at Berkeley make that a non-buzzword?
Big data should be just a way of life. How do we get to that point?”
Featured Book: Exploring Big Historical Data: The Historian’s Macroscope

I’ve just ordered a copy of Exploring Big Historical Data: The Historian’s Macroscope for the Library, but have also discovered that there is a pre-press version available online.
You can find more information about the book at the publisher’s website.