Digital Collections Unit
How we’ve come to Bridge the Gap
by Sonia Kahn from the Bancroft Digital Collections Unit.
Today the San Francisco-Oakland Bay Bridge, known to locals as just the Bay Bridge, is an essential part of many Bay Area commuters’ daily routine, but a mere 80 years ago the bridge many now take for granted as just one more part of their traffic-filled commute did not exist. On November 12, 2016, the Bay Bridge celebrated its 80th birthday, having officially opened to the public on that date in 1936. Today the Bay Bridge is oft overshadowed by its 6 month younger brother, the Golden Gate Bridge, as an iconic sign of San Francisco. But since the 1930s the Bay Bridge has played an essential role in bridging the gap between the East Bay and San Francisco.
It’s impossible. That was what many critics charged at those who explained they wanted to build a bridge across the San Francisco Bay. The idea to construct a bridge connecting Oakland to San Francisco had been around since the 1870s but saw no real progress until the administration of President Herbert Hoover, when the Reconstruction Finance Corporation agreed to purchase bonds to help fund construction which were to be paid back with tolls. But was building such a bridge really possible? In some places, the Bay was more than 100 feet deep, and on top of that, construction would have to take into consideration the threat of an earthquake. Interestingly, engineers planning for the bridge were more concerned with the threat brought about by high winds which could affect the bridge’s integrity.
Ground was broken for the bridge on July 9, 1933, and was welcomed with celebration. The United States Navy Band played at the event, and an air acrobatic left a trail of smoke between Oakland and Rincon Hill where the bridge would connect the East Bay to San Francisco. Celebration was well warranted. The feat of engineering was constructed in just three years, sixth months ahead of schedule! At a total cost of $77 million, the Bay Bridge was an engineering marvel which spanned more than 10,000 feet and was the longest bridge of its kind when it was completed.

From its opening until 1952, cars were not the only passengers on the Bay Bridge. The two-decker bridge saw cars traveling in both directions up top while trains and trucks traveled in both directions on the lower deck. In 1952 trains were scrapped, and in 1958 the upper deck was reconfigured to handle five lanes of westbound traffic as the lower deck accepted passengers headed for Oakland.
Since the 1950s the Bay Bridge has seen many developments. HOV lanes were added for high-occupancy vehicles, and the 1970s saw a decrease and eventual elimination of tolls for these vehicles. A metering system to regulate vehicles entering the bridge was also added which reduced traffic accidents by 15%. In 1989, the infamous Loma Prieta earthquake caused a portion of the upper deck of the Bay Bridge’s eastern span to collapse, proving that the structure was still susceptible to particularly strong tremors despite its strong moorings. This led to retrofitting procedures on the bridge. Most recently a new eastern span was built and was opened to the public in September 2013 after a decade of construction.
Today the Bay Bridge sees more than 102 million vehicles a year cross its decks, more than 11 times the number it carried in its first year. So perhaps next time you cross the Bay Bridge take a minute to appreciate the 80-year-old engineering marvel that makes crossing the Bay a breeze-if you don’t get stuck in the Bay Area traffic!

The Bancroft Library maintains a collection of over 1,100 photographs from the construction of the Bay Bridge.
View the collection: Construction Photographs of the San Francisco-Oakland Bay Bridge (BANC PIC 1905.14235-14250–PIC)
105 Years of Women’s Suffrage in California
This post comes from Sonia Kahn, one of our student employees who has been digging into some of our favorite digital collections. Today we discuss voting!
With the possibility of a female president now a real possibility, it’s hard to imagine that less than 100 years ago, all women did not have the right to vote in the United States. Many students across the nation now memorize the infamous 19th Amendment, passed in 1920, as granting American women the right to vote. But in fact many women to the west of the Mississippi had gained the right to vote long before their East Coast sisters joined them in 1920. At the beginning of 1920, women had already achieved full equality in suffrage in 15 states, and partial suffrage in another 20, leaving only 12 states where women were completely left out of the voting process. Indeed, here in California, women have had the right to vote since 1911, when the Golden State joined a total of five other Western states in granting women the full right to vote in all elections.
![Women vote for President... why not in California? [broadside]](http://digitalassets.lib.berkeley.edu/calheritage/ucb/honeyman/figures/HN001873aA.jpg)
With the memory of defeat ever present, California suffragettes implemented a new strategy when the topic of equal suffrage came up for a vote once more. Recalling that business had a strong hold on the state’s major cities, supporters of equal suffrage targeted voters in rural and southern California. To get the word out they used traditional tactics such as handing out more than 90,000 “Votes for Women” buttons and distributing three million pieces of promotional literature across southern California alone. But the suffragettes did more than put up posters and hand out buttons. They also pasted their message on billboards and often used electric signs, relaying their message with a spark.

October 10, 1911, was the day of reckoning in which allies of equal suffrage would see if their efforts bore fruit. Again both San Francisco and Alameda counties voted down the measure, and suffrage passed by just a hair in Los Angeles, to the dismay of many suffragettes. But all was not lost, and the tide began to turn as votes from California’s rural districts were tallied. When the final tally was made, equal suffrage had just barely come out on top with a miraculously small margin of just 3,587 votes, out of a total 246,487 ballots cast.
Today in California 73% of eligible adults are registered to vote, but just 43% of those adults turned out for the November 2014 election, a record low. This is a significant decrease from 2012 in which 72% of registered voters turned out to the polls.
One-hundred five years ago, fewer than 4,000 people were pivotal in changing the course of California history. Had they not voted, women in California might have had to wait another nine years to have their voices heard. To the women in California in 1911, a handful of votes were essential in advancing civil rights for thousands, proving that your vote truly does matter.
Check out the collection here: https://calisphere.org/collections/11601/
A Taste of History
Today’s blog post comes to us from Sonia Kahn, one of the student employees in the Digital Collections Unit. Sonia has been digging into some of our favorite digital collections and writing posts to highlight some of the fabulous digitized material from the Bancroft collections.
With Halloween just around the corner, many of us have chocolate on our mind, and some of you may have already dipped into the sugary arsenal meant for potential trick or treaters. But having a sweet tooth isn’t a seasonal event and many of us crave chocolate year-round, especially here in the Bay Area, where tourists from all over the world flock to Ghirardelli Square to sample the offerings of one of San Francisco’s most famous companies.
But the Ghirardelli chocolate company’s history stretches back much farther than the 1964 opening of now iconic Ghirardelli Square. Did you know that the Bancroft Library is home to a Ghirardelli company photo album that contains 56 photographs of the chocolate making process? This short and sweet collection includes photos dating from 1882 to the early 1920s.
![[Factory workers in canning area.]](http://cdn.calisphere.org/data/13030/b4/tf1x0nb2b4/files/tf1x0nb2b4-FID4.jpg)
![[Factory buildings, seen from south.]](http://cdn.calisphere.org/data/13030/fv/tf1k4005fv/files/tf1k4005fv-FID4.jpg)
In 2012 the Ghirardelli company celebrated its 160th anniversary, and today Ghirardelli Square continues to beckon to tourists and locals alike with its tantalizing sweets. The history of the Ghirardelli company is just one of the many collections on California’s cultural heritage that the Bancroft is working to preserve.
Check out the collection here: https://calisphere.org/collections/8416/
Bancroft Library Celebrates Bastille Day
by Randal Brandt (Head of Cataloging)
Acquired via a recent transfer from the Main Library stacks is a complete set of the “Collection des mémoires rélatifs à la Révolution française.” Compiled and edited by St.-Albin Berville and François Berrière and published by Baudouin frères in Paris, 1820-1827, these 53 volumes provide first-hand accounts of the French Revolution by members of the aristocracy whose lives were upended by the events of 1789-1799. Among the memoirs in the set are recollections of the life of Marie-Antoinette written her lady-in-waiting Jeanne-Louise-Henriette Campan, accounts of Louis XVI’s flight to Varennes in 1791, and eyewitness testimony of the storming of the Bastille on July 14, 1789.
The set was originally from the personal library of Professor H. Morse Stephens (1857-1919), who was instrumental in the acquisition of the Bancroft Library by the University of California (and for whom Stephens Hall is named), and many of the volumes still bear his bookplate.

Title page and map from http://oskicat.berkeley.edu/record=b13809670~S6
All volumes in set are cataloged in OskiCat
How to Read an e-book…From 1991
by Kate Tasker (Digital Archivist, Bancroft Library) and Jay Boncodin (Library Computer Infrastructure Services)
In July 2015, the Bancroft Library’s Digital Collections Unit received an intriguing message from UC Berkeley Assistant Professor Alex Saum-Pascual, who teaches in the Spanish and Portuguese Department and with the Berkeley Center for New Media. Alex and her colleague Élika Ortega, a Postdoctoral Researcher at the Institute for Digital Research in the Humanities at the University of Kansas, were working on a Digital Humanities project for electronic literature, and wanted to read a groundbreaking book they had checked out of the UC Berkeley Library. The book was written by Stuart Moulthrop and is titled Victory Garden. But this “book” was actually a hypertext novel (now a classic in the genre) — and it was stored on a 3.5” floppy disk from 1991.

Alex had heard about the digital forensics work happening at the Bancroft Library. She wanted to know if we could help her read the disk so she could use the novel in her new undergraduate course, and in a collaborative exhibit called “No Legacy: Literatura electrónica (NL || LE)” (opening March 11, 2016 in Doe Library). We were excited to help out with such a cool project, and enlisted Jay Boncodin (a retro-tech enthusiast) from Library Computer Infrastructure Services (LCIS) to investigate this “retro” technology.
The initial plan was to make a copy of the floppy, to be read and displayed on an old Mac Color Classic. The software booklet included with the floppy disk listed instructions for installing the “Storyspace” software on Macintosh computers, so this seemed like a good sign.
Our first step was to make an exact bit-for-bit forensic copy of the original disk as a back up, which would allow us to experiment without risking damage to the original. The Digital Collections Unit routinely works with the Library Systems Office to create disk images of older computer media like 3.5” floppies to support preservation and processing activities, so this was familiar territory. We created a disk image using the free FTK Imager program and an external 3.5” floppy disk drive with a USB connector.
Next, all we had to do was copy the disk image to a new blank 3.5” floppy, insert into a floppy disk drive, and voila! We’d have access to a recovered 25-year-old eBook.
…Except the floppy disk drive couldn’t read the floppy, on any of the Macs we tried.
We backed up a step to ensure that nothing had gone wrong with the disk imaging process. We were able to view a list of the floppy disk contents in the FTK Imager program, and extracted copies of the original files for good measure. The file list looked very much like one from a Windows-based program, and we also recognized an executable file (with the .exe extension) which would be familiar to anyone who’s ever downloaded and installed Windows software.
After double-checking the catalog record we realized that despite the documentation this “Macintosh” disk was actually formatted for PCs, so it definitely was not going to run on a Mac.
Switching gears (and operating systems), we then attempted to read the disk on a machine running Windows 7 – but encountered an error stating the program would only run on a 32-bit operating system. Luckily Jay had an image of a 32-bit Windows OS handy, so we could test it out.
It took a couple of tries, but we finally were able to read the disk on the 32-bit OS. Victory!
From there it was an eas(ier) task to copy the software files and install the program.
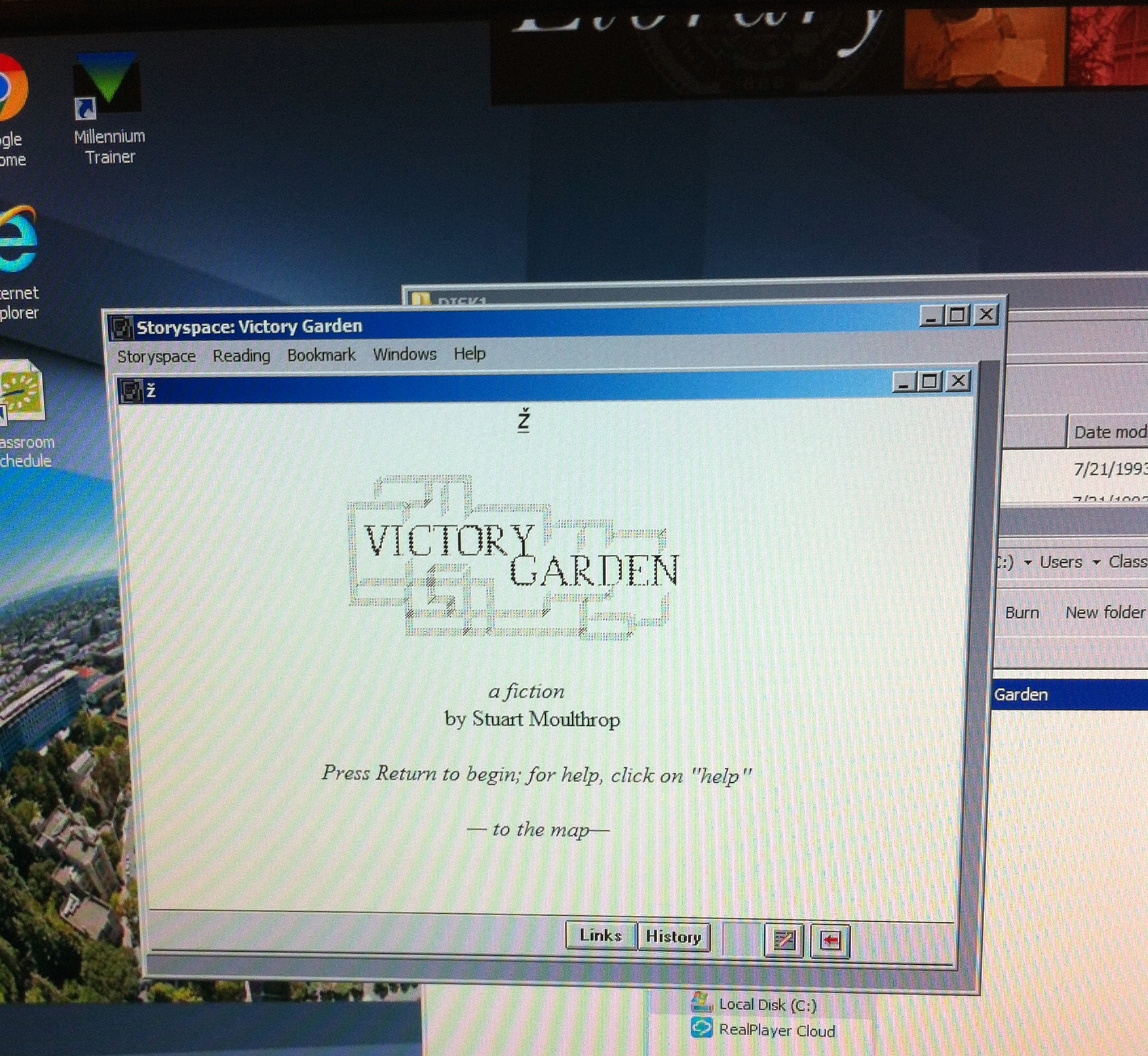
Jay scrounged up a motherboard with a 3.5” floppy drive controller and built a custom PC with an internal 3.5” floppy drive, which runs the 32-bit Windows operating system. After Victory Garden was installed on this PC, it was handed off to Dave Wong (LCIS) who conducted the finishing touches of locking down the operating system to ensure that visitors cannot tamper with it.
The machine has just been installed in the Brown Gallery of Doe Library and is housed in a beautiful wood enclosure designed by students in Stephanie F. Lie’s Fall 2016 seminar “New Media 290-003: Archive, Install, Restore” at the Berkeley Center for New Media.

Since one of the themes of the No Legacy: Literatura electrónica project is the challenge of electronic literature preservation, it seems fitting that the recovery of the floppy disk data was not exactly a straightforward process! Success depended on collaboration with people across the UC Berkeley campus, including Alex and her Digital Humanities team, the Berkeley Center for New Media, Library Computer Infrastructure Services, Doe Library staff, and the Bancroft Library’s Digital Collections Unit.
We’re excited to see the final display, and hope you’ll check it out yourself in the Bernice Layne Brown Gallery in Doe Library. The exhibit runs from March 11 – September 2, 2016.
For more information, visit http://nolegacy.berkeley.edu/.
Spring 2016 Born-Digital Archival Internship
The Bancroft Library University of California Berkeley

SPRING ARCHIVAL INTERNSHIP 2016
Come use your digital curation and metadata skills to help the Bancroft process born-digital archival collections!
Who is Eligible to Apply
Graduate students currently attending an ALA accredited library and information science program who have taken coursework in archival administration and/or digital libraries.
Please note: our apologies, but this internship does not meet SJSU iSchool credit requirements at this time.
Born-Digital Processing Internship Duties
The Born-Digital Processing Intern will be involved with all aspects of digital collections work, including inventory control of digital accessions, collection appraisal, processing, description, preservation, and provisioning for access. Under the supervision of the Digital Archivist, the intern will analyze the status of a born-digital manuscript or photograph collection and propose and carry out a processing plan to arrange and provide access to the collection. The intern will gain experience in appraisal, arrangement, and description of born-digital materials. She/he will use digital forensics software and hardware to work with disk images and execute processes to identify duplicate files and sensitive/confidential material. The intern will create an access copy of the collection and, if necessary, normalize access files to a standard format. The intern will generate an EAD-encoded finding aid in The Bancroft Library’s instance of ArchivesSpace for presentation on the Online Archive of California (OAC). All work will occur in the Bancroft Technical Services Department, and interns will attend relevant staff meetings.
Duration:
15 weeks (minimum 135 hours), January 28 – May 16, 2016 (dates are somewhat flexible). 1-2 days per week.
NOTE: The internship is not funded, however, it is possible to arrange for course credit for the internship. Interns will be responsible for living expenses related to the internship (housing, transportation, food, etc.).
Application Procedure:
The competitive selection process is based on an evaluation of the following application materials:
Cover letter & Resume
Current graduate school transcript (unofficial)
Photocopy of driver’s license (proof of residency if out-of-state school)
Letter of recommendation from a graduate school faculty member
Sample of the applicant’s academic writing or a completed finding aid
All application materials must be received by Friday, December 18, 2015, and either mailed to:
Mary Elings
Head of Digital Collections
The Bancroft Library
University of California Berkeley
Berkeley, CA 94720.
or emailed to melings [at] library.berkeley.edu, with “Born Digital Processing Internship” in the subject line.
Selected candidates will be notified of decisions by January 8, 2016.
It’s Electronic Records Day! Do You Know How to Save Your Stuff?

October 10, 2015 is Electronic Records Day – a perfect opportunity to remind ourselves of both the value and the vulnerability of electronic records. If you can’t remember the last time you backed up your digital files, read on for some quick tips on how to preserve your personal digital archive!
The Council of State Archivists (CoSA) established Electronic Records Day four years ago to raise awareness in our workplaces and communities about the critical importance of electronic records. While most of us depend daily on instant access to our email, documents, audio-visual files, and social media accounts, not everyone is aware of how fragile that access really is. Essential information can be easily lost if accounts are shut down, files become corrupted, or hard drives crash. The good news is there are steps you can take to ensure that your files are preserved for you to use, and for long-term historical research.
Check out CoSA’s Survival Strategies for Personal Digital Records (some great tips include “Focus on your most important files,” “Organize your files by giving individual documents descriptive file names,” and “Organize [digital images] as you create them”).
The Bancroft Library’s Digital Collections Unit is dedicated to preserving digital information of long-term significance. You can greatly contribute to these efforts by helping to manage your own electronic legacy, so please take a few minutes this weekend to back up your files (or organize some of those iPhone photos!) Together, we can take good care of our shared digital history.
Processing Notes: Digital Files From the Bruce Conner Papers
The following post includes processing notes from our summer 2015 intern Nissa Nack, a graduate student in the Master of Library and Information Science program at San Jose State University’s iSchool. Nissa successfully processed over 4.5 GB of data from the Bruce Conner papers and prepared the files for researcher access.
The digital files from the Bruce Conner papers consists of seven 700-MB CD-Rs (disks) containing images of news clippings, art show announcements, reviews and other memorabilia pertaining to the life and works of visual artist and filmmaker Bruce Conner. The digital files were originally created and then stored on the CD-Rs using an Apple (Mac) computer, type and age unknown. The total extent of the collection is measured at 4,517 MB.
Processing in Forensic Toolkit (FTK)
To begin processing this digital collection, a disk image of each CD was created and then imported into the Forensics Toolkit software (FTK) for file review and analysis. [Note: The Bancroft Library creates disk images of most computer media in the collections for long-term preservation.]
Unexpectedly, FTK displayed the contents of each disk in four separate file systems; HFS, HFS+, Joliet, and ISO 9660, with each file system containing an identical set of viewable files. Two of the systems, HFS and HFS+, also displayed discrete, unrenderable system files. We believe that the display of data in four separate systems may be due to the original files having been created on a Mac and then saved to a disk that could be read by both Apple and Windows machines. HFS and HFS+ are Apple file systems, with HFS+ being the successor to HFS. ISO 9660 was developed as a standard system to allow files on optical media to be read by either a Mac or a PC. Joliet is an extension of ISO 9660 that allows use of longer file names as well as Unicode characters.
With the presentation of a complete set of files duplicated under each file system, the question arose as to which set of files should be processed and ultimately used to provide access to the collection. Based on the structure of the disk file tree as displayed by FTK and evidence that a Mac had been used for file creation, it was initially decided to process files within the HFS+ system folders.
Processing of the files included a review and count of individual file types, review and description of file contents, and a search of the files for Personally Identifiable Information (PII). Renderable files identified during processing included Photoshop (.PSD), Microsoft Word (.DOC), .MP3, .TIFF, .JPEG, and .PICT. System files included DS_Store, rsrc, attr, and 8fs.
PII screening was conducted via pattern search for phone numbers, social security numbers, IP addresses, and selected keywords. FTK was able to identify a number of telephone numbers in this search; however, it also flagged groups of numbers within the system files as being potential PII, resulting in a substantial number of false hits.
After screening, the characteristics of the four file systems were again reviewed, and it was decided to use the Joliet file for export. Although the HFS+ file system was probably used to create and store the original files, it proved difficult to cleanly export this set of files from FTK. FTK “unpacked” the image files and displayed unrenderable resource, attribute and system files as discrete items. For example: for every .PSD file, a corresponding rsrc file could be found. The .PSD files can be opened, but the rsrc files cannot. The files were not “repacked” during export, and it is unknown as to how this might impact the images when transferred to another platform. The Joliet file system allowed us to export the images without separating any system-specific supporting files.

Issues with the length of file and path names were particularly felt during transfer of exported files to the Library network drive and, in some cases, after the succeeding step, file normalization.
File Normalization
After successful export, we began the task of file normalization whereby a copy of the master (original) files were used to produce access, and preservation surrogates in appropriate formats. Preservation files would ideally be in a non-compressed format that resists deterioration and/or obsolescence. Access surrogates are produced in formats that are easily accessible across a variety of platforms. .TIFF, .JPEG, .PICT, and .PSD files were normalized to the .TIFF format for preservation and the .JPEG format for access. Word documents were saved in the .PDF format for preservation and access, and .MP3 recordings were saved to .WAV format for preservation and a second .MP3 copy created for access.
Normalization Issues
Photoshop
Most Photoshop files converted to .JPEG and .TIFF format without incident. However, seven files could make the transfer to .TIFF but not to .JPEG. The affected files were all bitmap images of typewritten translations of reviews of Bruce Conner’s work. The original reviews appear to have been written for Spanish language newspapers.
To solve the issue, the bitmap images were converted to grayscale mode and from that point could be used to produce a .JPEG surrogate. The conversion to grayscale should not adversely impact file as the original image was of a black and white typewritten document, not of a color imbued object.
PICT
The .PICT files in this collection appeared in FTK and exported with a double extension (.pct.mac), and couldn’t be opened by either Mac or PC machines. Adobe Bridge was used to locate and select the files and then, using the “Batch rename” feature under the Tools menu, to create a duplicate file without the .mac in the file name.
The renamed .PCT files were retained as the master copies, and files with a duplicate extension were discarded.
Adobe Bridge was then used to create .TIFF and .JPEG images for the Preservation and Access files as in the case of .PSD files.
MP3 and WAV
We used the open-source Audacity software to save .MP3 files in the .WAV format, and to create an additional .MP3 surrogate. Unfortunately the Audacity software appeared to be able to process only one file type at a time. In other words, each original .MP3 file had to be individually located and exported as a .WAV file, which was then used to create the access .MP3 file. Because there were only six .MP3 files in this collection, the time to create the access and preservation files was less than an hour. However, if in the future a larger number of .MP3s need to be processed, an alternate method or workaround will need to be found.
File name and path length
The creator of this collection used long, descriptive file names with no real apparent overall naming scheme. This sometimes created a problem when transferring files, as the resulting path names of some files would exceed the allowable character limits and not allow the file to transfer. The “fix” was to eliminate words/characters while retaining as much information as possible from the original file name until a transfer could occur.
Processing Time
Processing time for this project, including time to create the processing plan and finding aid, was approximately 16 working days. However, a significant portion of the time, approximately ¼ to 1/3, was spent learning the processes and dealing with technological issues (such as file renaming or determining which file system to use).
Case Study of the Digital Files from the Reginald H. Barrett Papers
The following is a guest post from our summer 2015 intern Beaudry Allen, a graduate student in the Master of Archives and Records Administration (MARA) program at San Jose State University’s iSchool.
Case Study of the Digital Files from the Reginald H. Barrett Papers
As archivists, we have long been charged with selecting, appraising, preserving, and providing access to records, though as the digital landscape evolves there has been a paradigm shift in how to approach those foundational practices. How do we capture, organize, support long-term preservation, and ultimately provide access to digital content; especially with the convergence of challenges resulting from the exponential growth in the amount of born-digital material produced?
So, embarking on a born-digital processing project can be a daunting prospect. The complexity of the endeavor is unpredictable, and undoubtedly unforeseen issues will arise. This summer I had the opportunity to experience the challenges of born-digital processing firsthand at the Bancroft Library, as I worked on the digital files from the Reginald H. Barrett papers.
Reginald Barrett was a former professor at UC Berkeley in the Department of Environmental Science, Policy, & Management. Upon his retirement in 2014, Barrett donated his research materials to the Bancroft Library. In addition to more than 96 linear feet of manuscripts and photographs (yet to be described), the collection included one hard drive, one 3.5” floppy disk, three CDs, and his academic email account. His digital files encompassed an array of emails, photographs, reports, presentations, and GIS-mapping data, which detailed his research interests in animal populations, landscape ecology, conservation biology, and vertebrate population ecology. The digital files provide a unique vantage point from which to examine the methods of research used by Barrett, especially his involvement with the development of California Wildlife Habitat Relationships System. The project’s aim was to process and describe Barrett’s born-digital materials for future access.
The first step in processing digital files is ensuring that your work does not disrupt the authenticity and integrity of the content (this means taking steps to prevent changes to file dates and timestamps or inadvertently rearranging files). Luckily, the initial ground work of virus-checking the original files and creating a disk image of the media had already been done by Bancroft Technical Services and the Library Systems Office. A disk image is essentially an exact copy of the original media which replicates the structure and contents of a storage device. Disk imaging was done using a FRED (Forensic Recovery of Evidence Device) workstation, and the disk image was transferred to a separate network server. The email account had also been downloaded as a Microsoft Outlook .PST file and converted to the preservation MBOX format. Once these preservation files were saved, I used a working copy of the files to perform my analysis and description.
My next step was to run checksums on each disk image to validate its authenticity, and to generate file directory listings which will serve as inventories of the original source media. The file directory listings are saved with the preservation copies to create an AIP (Archival Information Package).
Using FTK
Actual processing of the disk images from the CDs, floppy disk, and hard drive was done using the Forensic Toolkit (FTK) software. The program reads disk images and mimics the file system and contents, allowing me to observe the organizational structure and content of each media. The processing procedures I used were designed by Kate Tasker and based on the 2013 OCLC report, “Walk This Way: Detailed Steps for Transferring Born-Digital Content from Media You Can Read In-house” (Barrera-Gomez & Erway, 2013).
Processing was a two-fold approach; one, survey the collection’s content, subject matter, and file formats; and two (which was a critical component to processing), identify and restrict items that contained Personally Identifiable information (PII), or student records protected by the Family Educational Rights and Privacy Act (FERPA). I relied on FTK’s pattern search function to locate Social Security Numbers, credit card numbers, phone numbers, etc., and on its index search function to locate items with sensitive keywords. I was then able to assign “restricted” labels to each item and exclude them from the publicly-accessible material.
While I, like many iSchool graduate students, am familiar with the preservation standard charts for file formats, I was introduced to new file formats and GIS data types which will require more research before they can be normalized to a format recommended for long-term preservation or access. Though admittedly hard, there is something gratifying about being faced with new challenges. Another challenge was identifying and flagging unallocated space, deleted files, corrupted files, and system files so they were not transferred to an access copy.
A large component of traditional archival processing is arrangement, yet creating an arrangement beyond the original order was impractical as there were over 300,000 files (195 GB) on the hard drive alone. Using original order also preserves the original file name convention and file hierarchy as determined by the creator. Overall, I found Forensic Toolkit to be a straightforward, albeit sensitive program, and I was easily able to navigate the files and survey content.
One of the challenges in using FTK which halted my momentum many times was exporting. After processing in FTK and assigning appropriate labels and restrictions, the collection files were exported with the restricted files excluded (thus creating a second, redacted AIP). The exported files would then be normalized to a format which is easy to access (for example, converting a Word .doc format to .pdf). The problem was the computer could not handle the 177 GB of files I wanted to export. I could not export directories larger than 20 GB without it either crashing or receiving export errors from FTK. This meant I needed to export some directories in smaller pieces, with sizes ranging from 2-15 GB. Smaller exports took ten minutes each, while larger files from 10-15 GB could take 4-15 hours, so most of my time was spent wishin’ and hopin’ and thinkin’ and prayin’ the progress bar for each export would be fast.
Another major hiccup occurred in large exports, when FTK failed to exclude files marked as restricted. This meant I had go through the exported files and cross reference my filters so I could manually remove the restricted items. By the end of it, I felt like I did all the work twice, but the experience helped us to determine the parameters of what FTK and the computer could handle.
The dreaded progress bar…

Using ePADD
The email account was processed using an open-source program developed by Stanford University’s Special Collections & Archives that supports the appraisal, processing, discovery, and delivery of email archives (ePADD). Like FTK, ePADD has the ability to browse all files and add restrictions to protect private and sensitive information. I was able to review the senders and message contents, and display interesting chart visualizations of the data. Considering Barrett’s email was from his academic account, I had run “lexicon” searches relating to students to find and restrict information protected by FERPA. ePADD allows the user to choose from existing or user-generated lexicons, in order to search for personal or confidential information, or to perform complex searches for thematic content. I had better luck entering my own search terms to locate specific PII than accepting ePADD’s default search terms, as I was very familiar with the collection by that point and knew what kind of information to search for.
For the most part the platform seems very sleek and user-friendly, though I had to refer to the manual more often than not as I ended up not finding the interface as intuitive as it seemed. After appraisal and processing, ePADD will export the emails to the discovery or delivery modules. The delivery module provides a user interface so researchers can view the emails. The Bancroft Library is in the process of implementing plans to make email collections and other born-digital materials available.
Overall, the project was also a personal opportunity to evaluate the cyclical relationship between theory and practice of digital forensics and processing. Before the project I had a good grasp on the theoretical requirements and practices in digital preservation, but had not conceptualized the implications of each step of the project and how time-consuming it could be. The digital age conjures up images of speed, but I spent 100 hours (in a 7-week period) processing the collection. There are so many variables that need to be considered at each step, so that important information is made accessible. This also amplified the need for collaboration in building a successful digital collection program, as one must rely on participation from curatorial staff and technical services to ensure long-term preservation and access. The project even brought up new questions of “More Product, Less Process” (MPLP) processing in relation to born-digital content: what are the risks associated with born-digital MPLP, and how can an institute mitigate potential pitfalls? How do we need to approach born-digital processing differently?
The Newest Addition to the Bancroft Digital Collections Forensic Workstation
By Kate Tasker and Julie Goldsmith, Bancroft Digital Collections
Last week in the Bancroft’s Digital Collections Unit, we put our new Tableau write blocker to work. Before processing a born-digital collection, a digital archivist must first be able to access and transfer data from the original storage media, often received as hard drives, optical disks and floppy disks. Floppy disks have a mechanism to physically prevent changes to the data during the transfer process, but data on hard drives and USB drives can be easily and irreversibly altered just by connecting the drive to a computer. We must access these drives in write-blocked (or read-only) mode to avoid altering the original metadata (e.g. creation dates, timestamps, and filenames). The original metadata is critical for maintaining the authenticity, security, contextual information, and research value of digital collections.

A write blocker is essentially a one-way street for data; it provides assurance that no changes were made, regardless of user error or software modification. For digital archives, using a write blocker ensures an untampered audit trail of changes that have occurred along the way, which is essential for answering questions about provenance, original order and chain of custody. As stewards of digital collections, we also have a responsibility to identify and restrict any personally identifying information (PII) about an individual (Social Security numbers, medical or financial information, etc.), which may be found on computer media. The protected chain of custody is seen as a safeguard for collections which hold these types of sensitive materials.
Other types of data which are protected by write-blocked transfers include configuration and log files which update automatically when a drive connects to a system. On a Windows formatted drive, the registry files can provide information associated with the user, like the last time they logged in and various other account details. Another example would be if you loaned someone a flash drive and they plugged it into their Mac; by doing so they can unintentionally update or install system file information onto the flash drive like a hidden .Spotlight-V100 file. (Spotlight is the desktop search utility on the Mac OS X, and the contents of this folder serve as an index of all files that were on the drive the last time it was used with a Mac.)
Write blockers also support fixity checks for digital preservation. We use software programs to calculate unique identifiers for every original file in a collection (referred to as cryptographic hash algorithms, or checksums, by digital preservationists). Once files have been copied, the same calculations are run on the files to generate another set of checksums. If they match that means that the digital objects are the same, bit for bit, as the originals, without any modification or data degradation.

Once we load the digital collection files in FTK Imager, a free lightweight version of the Forensic Tool Kit (FTK), a program that the FBI uses in criminal data investigations we can view the folders and files in the original file directory structure. We can also easily export a file directory listing, which is an inventory of all the files in the collection with their associated metadata. The file directory listing provides us with specific information about each file (filename, filepath, file size, date created, date accessed, date modified, and checksum) as well as a summary of the entire collection (total number of files, total file size, date range, and contents). It also helps us to make processing decisions, such as whether to capture the entire hard drive as a disk image, or whether to transfer selected folders and files as a logical copy.
Write blockers are also known in the digital forensics and digital preservation fields as Forensic Bridges. Our newest piece of equipment is already helping us bridge the gap between preserving original unprocessed computer media and creating open digital collections which are available to all.
For Further Reading:
AIMS Working Group. “AIMS Born-Digital Collections: An InterInstitutional Model for Stewardship.” 2012. http://www.digitalcurationservices.org/files/2013/02/AIMS_final_text.pdf
Gengenbach, Martin J. “‘The Way We Do it Here’: Mapping Digital Forensics Workflows in Collecting Institutions.” A Master’s Paper for the M.S. in L.S degree. August, 2012. http://digitalcurationexchange.org/system/files/gengenbach-forensic-workflows-2012.pdf
Kirschenbaum, Matthew G., Richard Ovenden, and Gabriela Redwine. “Digital Forensics and Born-Digital Content in Cultural Heritage Collections.” Washington, DC: Council on Library and Information Resources, 2010. http://www.clir.org/pubs/reports/pub149
BitCurator Project. http://bitcurator.net
Forensics Wiki. http://www.forensicswiki.org/