Nos es muy grato anunciar la tercera entrega de PhiloBiblon para 2021, sobre todo porque a la vez podemos anunciar el comienzo de un proyecto piloto, sufragado por la National Endowment of the Humanities (NEH) del gobierno federal de EE.UU: “PhiloBiblon: From Siloed Databases to Linked Open Data via Wikibase: Proof of Concept.” La financiación que nos han concedido nos hará comenzar el proyecto el primero de junio del año en curso y finalizará el 30 de mayo de 2022.
El diseño del proyecto a partir de ahora intentará solucionar uno de los problemas más difíciles de proyectos digitales de larga trayectoria: mantener el soporte tecnológico. PhiloBiblon se inició como base de datos ancilar del proyecto para el Dictionary of the Old Spanish Language, llevado a cabo en la University of Wisconsin, Madison, por Lloyd Kasten y su alumno, John Nitti. A lo largo de los últimos 40 años hemos podido sostener, con dificultad, el database management system (DBMS) a la altura de la tecnología al uso. En Madison se empleó al principio el DBMS FAMULUS, creado, irónicamente en Berkeley en 1964, para las bibliografías del personal de la Pacific Southwest Forest and Range Experiment Station. Desde entonces, las transformaciones tecnológicas han sido constantes: desde los discos CD-ROM de ADMYTE (Archivo Digital de Manuscritos Y Textos Españoles) a una primera versión de la web en 1997, hasta llegar a la versión actual en 2014. Estas transformaciones han sido onerosas y han llegado por vía de constantes solicitudes a varias agencias y fundaciones, sobre todo a la NEH. La ayuda actual representa la primera solicitud exitosa desde 2014.
PhiloBiblon utiliza actualmente un DBMS relacional, OpenInsight, de la empresa Revelation Technology, descendiente lineal de Revelation G, la versión con la que comenzamos a trabajar en 1987. Este sistema fue diseñado por John May, estudiante graduado en Historia de la Ciencia a la sazón, que pronto cambió la carrera académica por el mundo de la informática. John ha mantenido y desarrollado PhiloBiblon hasta ahora, conformándolo a lo largo de más de 35 años en diez tablas relacionales: textos, testimonios, manuscritos e impresos, ejemplares de los impresos, personas, instituciones, topónimos y referencias secundarias. Entre sí, estas diez tablas cuentan con 1.246 elementos informáticos (campos), 98 vocabularios controlados, 110 índices y 30 pantallas para la incorporación de nuevos datos. Puedes encontrar versiones en formato PDF de algunas de estas útimas tablas en nuestra página Colaborar, con el objetivo de facilitar las aportaciones de nuestros usuarios.
PhiloBiblon y su DBMS relacional ya existían antes de que Tim Berners-Lee alumbrara la red en Suiza durante 1989, así como su explosión en 1994 al comercializarse el primer navegador realmente útil, Netscape. Era evidente casi desde el principio que la worldwide web ofrecía a PhiloBiblon un vehículo muy superior a los impresos y a los discos CD-ROM para poner nuestros datos al alcance de los investigadores. En aquella primera versión de la red (1997), el usuario podría buscar cualquier códice o frase de interés, pero lo que se recuperaba era siempre un manuscrito o impreso que contenía el elemento de búsqueda. En la versión actual se exportan las tablas de PhiloBiblon a ficheros XML, siendo cada tabla un fichero único. A continuación, se cargan estos ficheros al servidor de la Bancroft Library (y a su sitio espejo en la Universitat Pompeu Fabra), donde el programa eXtensible Text Framework (XTF) los separa en sus registros individuales, los indexa, y más tarde recupera los registros indicados a raíz de una búsqueda. Si se busca una frase, el programa ofrece como resultado el elenco de los textos que contienen dicha frase; si se busca un manuscrito de determinadas características, igualmente se ofrece un elenco de manuscritos que responden a ellas.
El sistema no se caracteriza por su elegancia y podría mejorar su eficiencia, pero funciona bastante bien. Además del problema de sostener el soporte tecnológico, después de la creación de la web 3.0 (la web semántica), PhiloBiblon necesita enfrentarse también con el hecho de que su existencia se organiza dentro de un silo informático, sin relación orgánica con otras fuentes de información. La web semántica está diseñada para utilizar los datos abiertos enlazados (Linked Open Data) precisamente para poder establecer relaciones entre fuentes de información (v.g., recursos como el Catálogo Colectivo del Patrimonio Bibliográfico Español) sin intervención manual del ser humano. Desde 2014, los equipos de PhiloBiblon hemos ido preparando toda una serie de solicitudes a la NEH, a agencias españolas, catalanas y europeas, así como a fundaciones de diverso grado, con el objetivo de financiar la transformación de PhiloBiblon en una fuente de información de la web semántica. Por desgracia, no hemos tenido éxito.
El año pasado, en vez de proponer la creación ex profeso de una nueva base de datos para PhiloBiblon, hemos propuesto una solución radicalmente diferente: incorporar PhiloBiblon al mundo wiki, cuyo producto más conocido es la Wikipedia, creada en 2002. Hoy por hoy, es el ejemplo más visible y de más éxito de la informática al servicio de la humanidad, de todo el mundo, desde los niños de colegio hasta los mayores de la tercera edad. En PhiloBiblon nos servimos de Wikipedia todos los días. En BETA, por ejemplo, citamos la obra en nueve lenguas diferentes, según el tema tratado, más de 1.400 veces. El motor de Wikipedia es el DBMS wikibase, que también sostiene el entorno más estructurada de Wikidata.
Es este último, Wikidata, el que más nos interesa precisamente por su carácter completamente abierto. Pero resulta un método poco apto para un proyecto como PhiloBiblon, que requiere un control más preciso de las personas que pueden contribuir a él. Hemos encontrado la solución ideal para nuestros propósitos en FactGrid, de la Universität Erfurt. Gracias a la generosa acogida de su director, Olaf Simons, vamos a establecer una relación que ojalá sea fructífera y duradera. FactGrid se vale de la misma tecnología de Wikidata y la creación de nuevas entidades emplea los mismos procedimientos utilizados por miles de usuarios del sistema. Hemos creado ya FactGrid:PhiloBiblon, una página web embrión para servir como sandbox (o entorno de pruebas), mientras vamos adiestrándonos en el proceso de crear registros en FactGrid y establecer el modelo detallado para importar de una vez el contenido de PhiloBiblon al nuevo entorno de producción.
A efectos de la solicitud del año pasado, Olaf creó un prototipo para mostrar BITAGAP manid 1067, el manuscrito BNE MSS/10069, que contiene las Cantigas de Santa María de Alfonso X, en el formato por defecto de Wikidata. Aquí lo tenemos, junto a imágenes parciales del mismo registro en la web de PhiloBiblon y en el catálogo de la BNE:
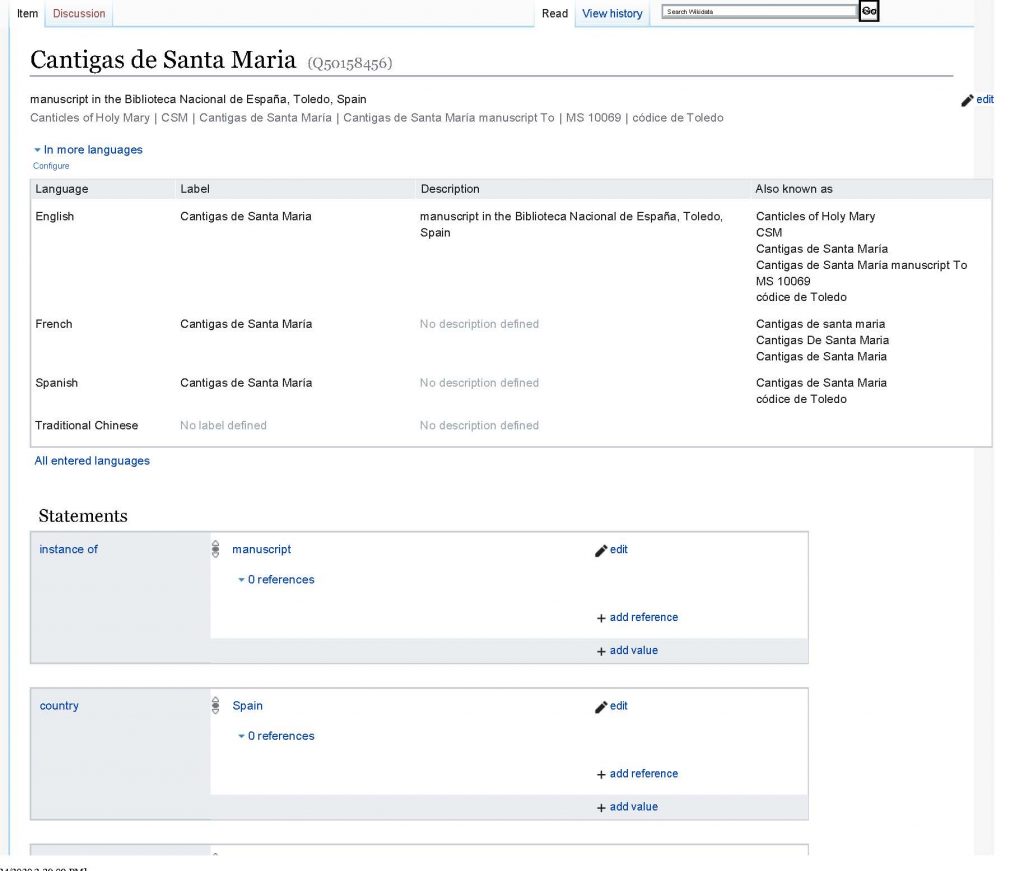


Como el lector puede comprobar, se trata exactamente de los mismos datos, pero con tres presentaciones distintas.
Cuando finalice este proyecto piloto en mayo de 2022, esperamos haber adquirido unas ideas mucho más precisas tanto sobre el formato que queremos utilizar para presentar PhiloBiblon a nuestros usuarios como acerca de los procedimientos necesarios para importar en masa a FactGrid sus más de 415.000 registros. Pero ahora mismo, con el proyecto ni siquiera en ciernes—porque no comienza oficialmente hasta el primero de junio—, nuestros esfuerzos se dedicarán a la limpieza y coordinación de los datos en las bibliografías de PhiloBiblon.
A corto plazo, vamos a emitir una llamada urbi et orbi para reclutar a voluntarios que nos puedan ayudar en la eliminación de erratas y errores, tareas humildes y a veces algo tediosas, pero completamente necesarias ante la exportación de tantos registros a un nuevo entorno tecnológico. Intentaremos congeniar la forma en la que nuestras necesidades se adapten a la de nuestros usuarios.
Charles B. Faulhaber
SSThe Bancroft Library
University of California, Berkeley