Summary
How does one create a workable dataset from a historic city directory?! Let's take a look using the publisher's list from the 1955-56 San Francisco City Directory and then map it.
Last post, I promised to talk about using structured data with a dataset focused on 1950s Bay Area publishing. To get into that topic, I’m going to talk about 1) setting out with a research question as well as 2) data discovery, and 3) data organization, in order to do 4) initial mapping.
Background to my Research
When I moved to the Bay Area, I (your illustrious Literatures and Digital Humanities Librarian) started exploring UC Berkeley’s collections. I wandered through the Doe Library’s circulating collections and started talking to our Bancroft staff about the special library and archive’s foci. As expected, one of UC Berkeley’s collecting areas is California publishing, with a special emphasis on poetry.

In fact, some of Bancroft’s oft-used materials are the City Light Books collections (link to finding aids in the Online Archive of California) that include some of Allen Ginsberg’s pre-publication drafts of “Howl” and original copies of Howl and Other Poems. You may already know about that poem because you like poetry, or because you watch everything with Daniel Radcliffe in it (IMDB on the 2013 Kill your Darlings). This is, after all, the very poem that led to the seminal trial that influenced U.S. free speech and obscenity laws (often called The Howl Obscenity Trial) . The Bancroft collections have quite a bit about that trial as well as some of Ginsberg’s correspondence with Lawrence Ferlinghetti (poet, bookstore owner, and publisher) during the harrowing legal case. (You can a 2001 discussion with Ferlinghetti on the subject here.)
Research Question
Interested in learning more about Bay Area publishing in general and the period in which Ginsberg’s book was written in particular, I decided to look into the Bay Area publishing environment during the 1950s and now (2020s), starting with the early period. I wanted a better sense of the environment in general as well as public access to books, pamphlets, and other printed material. In particular, I wanted to start with the number of publishers and where they were.
Data Discovery
For a non-digital, late 19th and 20th century era, one of the easiest places to start getting a sense of mainstream businesses is to look in city directories. There was a sweet spot in an era of mass printing and industrialization in which city directories were one of the most reliable sources of this kind of information, as the directory companies were dedicated to finding as much information as possible about what was in different urban areas and where men and businesses were located. The directories, as a guide to finding business, people, and places, were organized in a clear, columned text, highly standardized and structured in order to promote usability.
Raised in an era during which city directories were still a normal thing to have at home, I already knew these fat books existed. Correspondingly, I set forth to find copies of the directories from the 1950s when “Howl” first appeared. If I hadn’t already known, I might have reached out to my librarian to get suggestions (for you, that might be me).
I knew that some of the best places to find material like city directories were usually either a city library or a historical society. I could have gone straight to the San Francisco Public Library’s website to see if they had the directories, but I decided to go to Google (i.e., a giant web index) and search for (historic san francisco city directories). That search took me straight to the SFPL’s San Francisco City Directories Online (link here).
On the site, I selected the volumes I was interested in, starting with Polk’s Directory for 1955-56. The SFPL pages shot me over to the Internet Archive and I downloaded the volumes I wanted from there.
Once the directory was on my computer, I opened it and took a look through the “yellow pages” (i.e., pages with information sorted by business type) for “publishers.”

Glancing through the listings, I noted that the records for “publishers” did not list City Light Books. Flipped back to “book sellers,” I found it. That meant that other booksellers could be publishers as well. And, regardless, those booksellers were spaces where an audience could acquire books (shocker!) and therefore relevant. Considering the issue, I also looked at the list for “printers,” in part to capture some of the self-publishing spaces.
I now had three structured lists from one directory with dozens of names. Yet, the distances within the book and inability to reorganize made them difficult to consider together. Furthermore, I couldn’t map them with the structure available in the directory. In order to do what I wanted with them (i.e., meet my research goals), I needed to transform them into a machine readable data set.
Creating a Data Set
Machine Readable
I started by doing a one-to-one copy. I took the three lists published in the directory and ran OCR across them in Adobe Acrobat Professional (UC Berkeley has a subscription; for OA access I recommend Transkribus or Tesseract), and then copied the relevant columns into a Word document.
Data Cleaning
The OCR copy of the list was a horrifying mess with misspellings, cut-off words, Ss understood as 8s, and more. Because this was a relatively small amount of data, I took the time to clean the text manually. Specifically, I corrected typos and then set up the text to work with in Excel (Google Sheets would have also worked) by:
- creating line breaks between entries,
- putting tabs between the name of each institution and corresponding address
Once I’d cleaned the data, I copied the text into Excel. The line breaks functioned to tell Excel where to break rows and the tabs where to understand columns. Meaning:
- Each institution had its own row.
- The names of the institutions and their addresses were in different columns.
Having that information in different spaces would allow me to sort the material either by address or back to its original organization by company name.
Adding Additional Information
I had, however, three different types of institutions—Booksellers, Printers, and Publishers—that I wanted to be able to keep separate. With that in mind, I added a column for EntryType (written as one word because many programs have issues with understanding column headers with spaces) and put the original directory headings into the relevant rows.
Knowing that I also wanted to map the data, I also added a column for “City” and another for “State” as the GIS (i.e., mapping) programs I planned to use wouldn’t automatically know which urban areas I meant. For these, I wrote the name of the city (i.e., “San Francisco”) and then the state (i.e., “California”) in their respective columns and autofilled the information.
Next, for record keeping purposes, I added columns for where I got the information, the page I got it from, and the URL for where I downloaded it. That information simultaneously served for me as a reminder but also as a pointer for anyone else who might want to look at the data and see the source directly.
I put in a column for Org/ID for later, comparative use (I’ll talk more about this one in a further post,) and then added columns for Latitude and Longitude for eventual use.
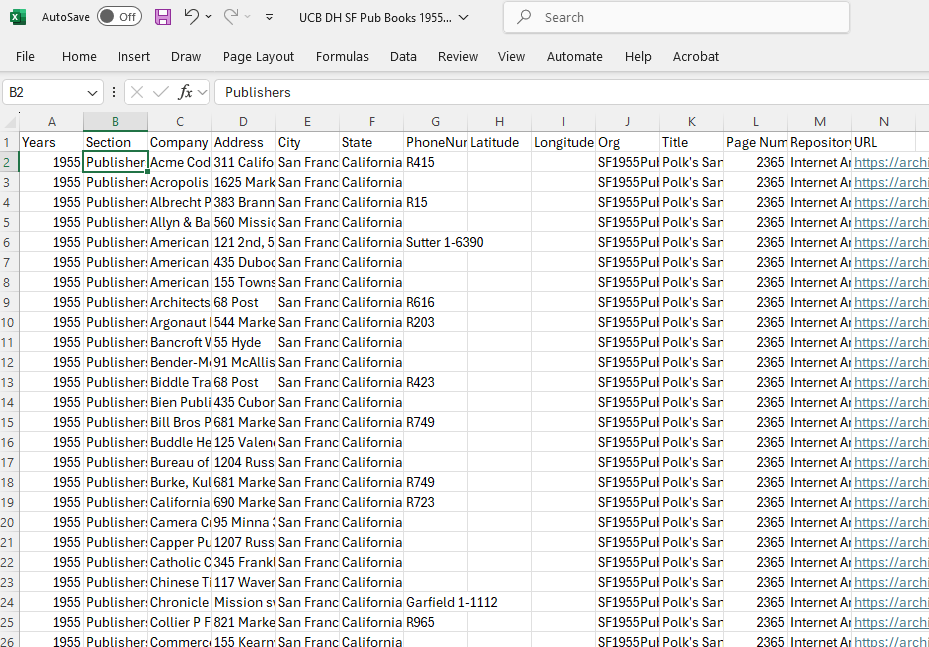
Finally, I saved my data with a filename that I could easily use to find the data again. In this case, I named it “BayAreaPublishers1955.” I made sure to save the data as an Excel file (i.e., .xmlx) and Comma Separated Value file (i.e., .csv) for use and preservation respectively. I also uploaded the file into Google Drive as a Google Sheet so you could look at it.
Initial Mapping of the Data
With that clean dataset, I headed over to Google’s My Maps (mymaps.google.com) to see if my dataset looked good and didn’t show locations in Los Angeles or other spaces. I chose Google Maps for my test because it is one of the easiest GIS programs to use
- because many people are already used to the Google interface
- the program will look up latitude and longitude based on address
- it’s one of the most restrictive, meaning users don’t get overwhelmed with options.
Heading to the My Maps program, I created a “new” map by clicking the “Create a new map” icon in the upper, left hand corner of the interface.
From there, I uploaded my CSV file as a layer. Take a look at the resulting map:
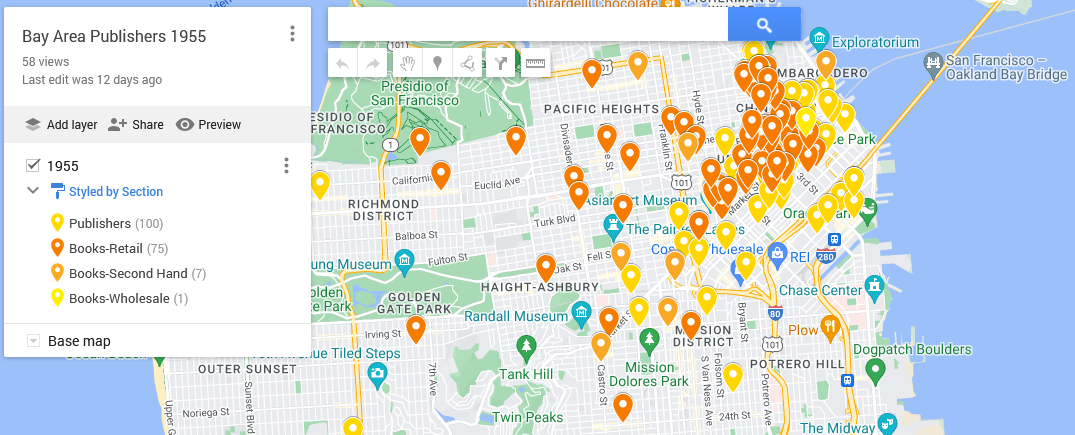
The visualization highlights the centrality of the 1955 San Francisco publishing world, with its concentration of publishing companies and bookstores around Mission Street. Buying books also necessitated going downtown, but once there, there was a world of information at one’s fingertips.
Add in information gleaned from scholarship and other sources about book imports, custom houses, and post offices, and one can start to think about international book trades and how San Francisco was hooked into it.
I’ll talk more about how to use Google’s My Maps in the next post in two weeks!